 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuhao Zhu
End-to-End Learning of Energy-Constrained Deep Neural Networks
Jun 12, 2018

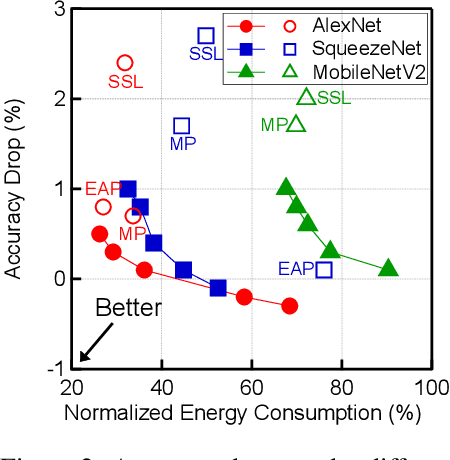

Deep Neural Networks (DNN) are increasingly deployed in highly energy-constrained environments such as autonomous drones and wearable devices while at the same time must operate in real-time. Therefore, reducing the energy consumption has become a major design consideration in DNN training. This paper proposes the first end-to-end DNN training framework that provides quantitative energy guarantees. The key idea is to formulate the DNN training as an optimization problem in which the energy budget imposes a previously unconsidered optimization constraint. We integrate the quantitative DNN energy estimation into the DNN training process to assist the constraint optimization. We prove that an approximate algorithm can be used to efficiently solve the optimization problem. Compared to the best prior energy-saving techniques, our framework trains DNNs that provide higher accuracies under same or lower energy budgets.
Euphrates: Algorithm-SoC Co-Design for Low-Power Mobile Continuous Vision
Mar 29, 2018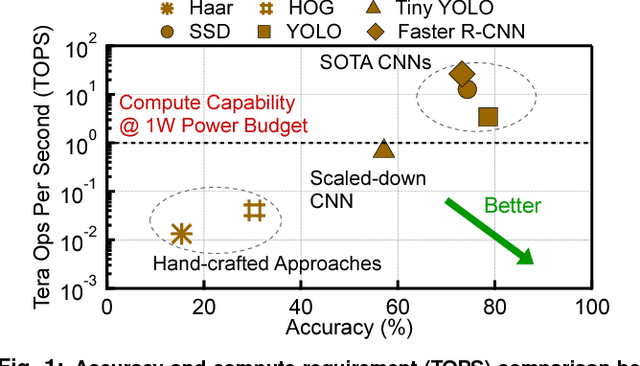
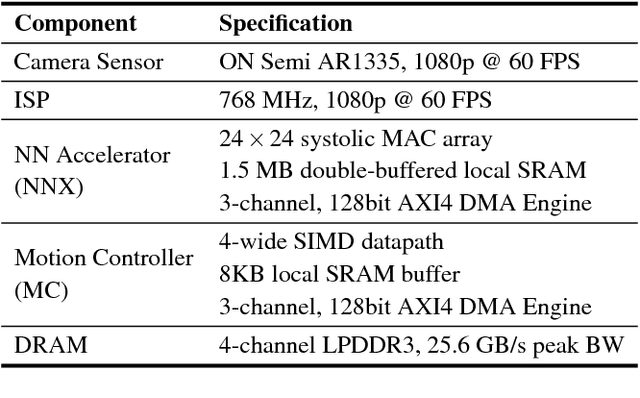
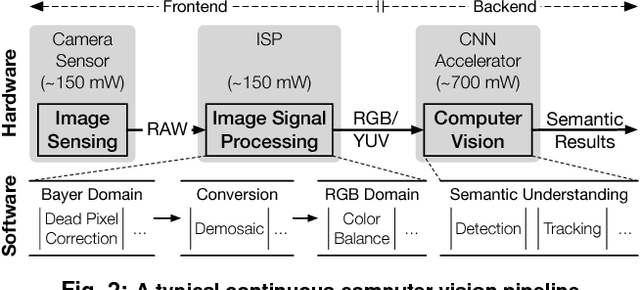
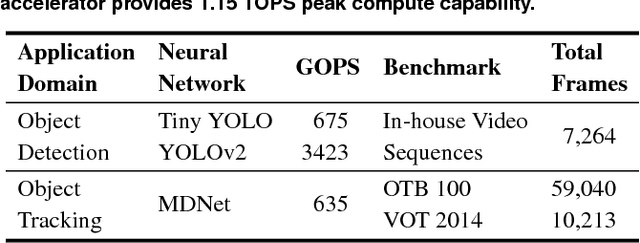
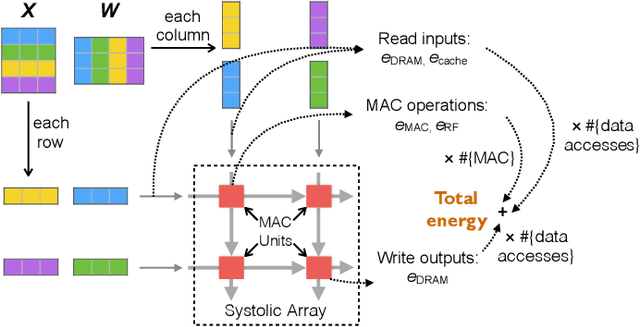
Continuous computer vision (CV) tasks increasingly rely on convolutional neural networks (CNN). However, CNNs have massive compute demands that far exceed the performance and energy constraints of mobile devices. In this paper, we propose and develop an algorithm-architecture co-designed system, Euphrates, that simultaneously improves the energy-efficiency and performance of continuous vision tasks. Our key observation is that changes in pixel data between consecutive frames represents visual motion. We first propose an algorithm that leverages this motion information to relax the number of expensive CNN inferences required by continuous vision applications. We co-design a mobile System-on-a-Chip (SoC) architecture to maximize the efficiency of the new algorithm. The key to our architectural augmentation is to co-optimize different SoC IP blocks in the vision pipeline collectively. Specifically, we propose to expose the motion data that is naturally generated by the Image Signal Processor (ISP) early in the vision pipeline to the CNN engine. Measurement and synthesis results show that Euphrates achieves up to 66% SoC-level energy savings (4 times for the vision computations), with only 1% accuracy loss.
Cloud No Longer a Silver Bullet, Edge to the Rescue
Feb 15, 2018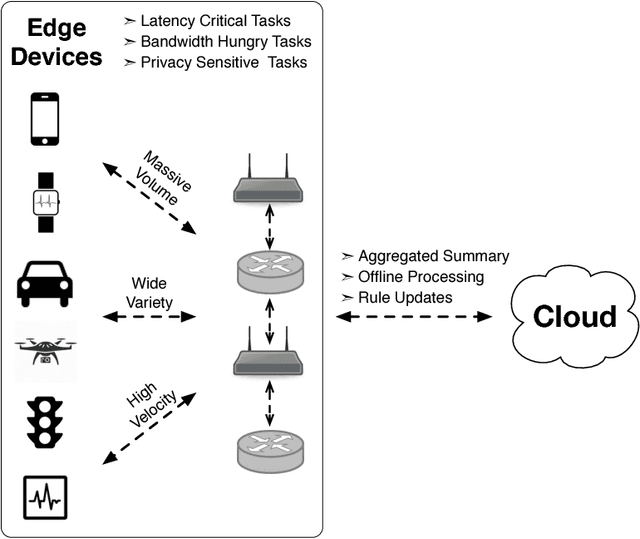
This paper takes the position that, while cognitive computing today relies heavily on the cloud, we will soon see a paradigm shift where cognitive computing primarily happens on network edges. The shift toward edge devices is fundamentally propelled both by technological constraints in data centers and wireless network infrastructures, as well as practical considerations such as privacy and safety. The remainder of this paper lays out our view of how these constraints will impact future cognitive computing. Bringing cognitive computing to edge devices opens up several new opportunities and challenges, some of which demand new solutions and some of which require us to revisit entrenched techniques in light of new technologies. We close the paper with a call to action for future research.
Mobile Machine Learning Hardware at ARM: A Systems-on-Chip (SoC) Perspective
Feb 01, 2018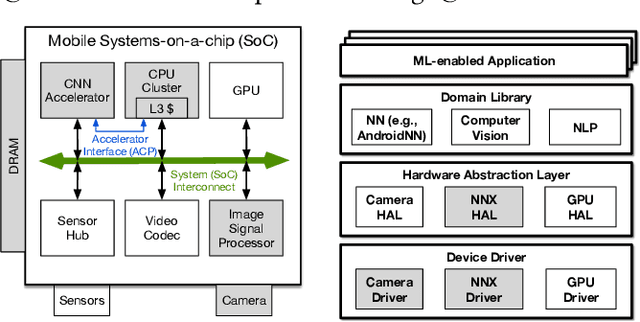
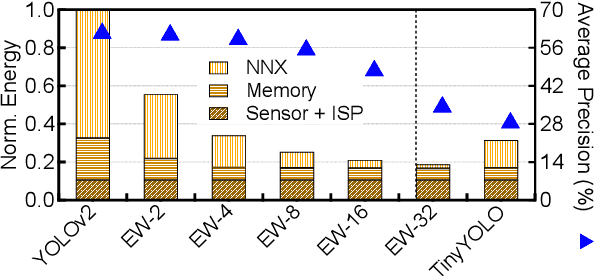
Machine learning is playing an increasingly significant role in emerging mobile application domains such as AR/VR, ADAS, etc. Accordingly, hardware architects have designed customized hardware for machine learning algorithms, especially neural networks, to improve compute efficiency. However, machine learning is typically just one processing stage in complex end-to-end applications, involving multiple components in a mobile Systems-on-a-chip (SoC). Focusing only on ML accelerators loses bigger optimization opportunity at the system (SoC) level. This paper argues that hardware architects should expand the optimization scope to the entire SoC. We demonstrate one particular case-study in the domain of continuous computer vision where camera sensor, image signal processor (ISP), memory, and NN accelerator are synergistically co-designed to achieve optimal system-level efficiency.