 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-Informed Generative Solver: Bridging Data-Driven Priors and Conservation Laws for Stable Spatiotemporal Field Reconstruction
May 21, 2026Reconstructing continuous physical fields from sparse measurements is a central inverse problem, but data-driven generative models can produce states that violate governing dynamics. We introduce a physics-informed generative solver that separates stable prior learning from inference-time enforcement of conservation laws. Martingale-Regularized Score Matching regularizes score pretraining with a Score Fokker-Planck constraint, yielding a dynamically stable prior. Physics-Informed Implicit Score Sampling then guides denoising trajectories by gradients of physical residuals, projecting samples toward admissible manifolds without retraining. In acoustics, the method co-generates pressure and particle velocity from sparse sensors, enabling dense virtual arrays that suppress spatial aliasing. The same framework generalizes to real-world ERA5 meteorological fields under extreme sparsity. Together, this work establishes a rigorous and generalizable paradigm for solving high-dimensional inverse problems, bridging the gap between generative artificial intelligence and first-principles science.
Graph Neural Network based Agent in Google Research Football
Apr 23, 2022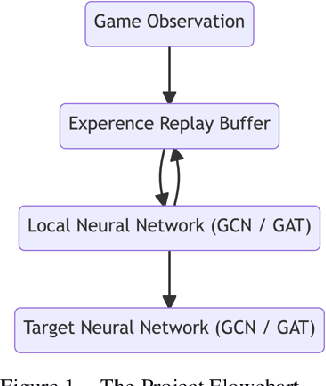
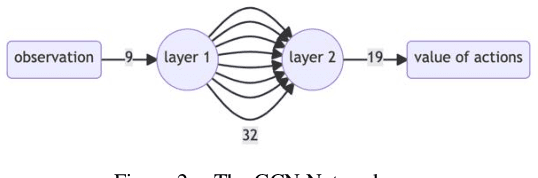
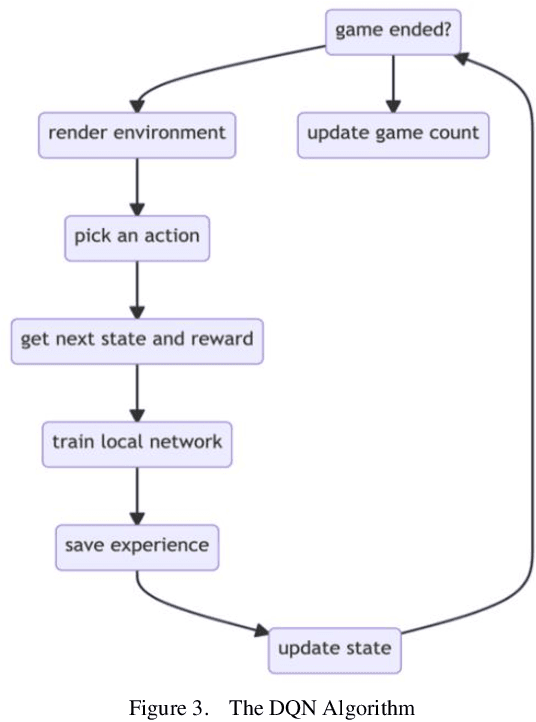
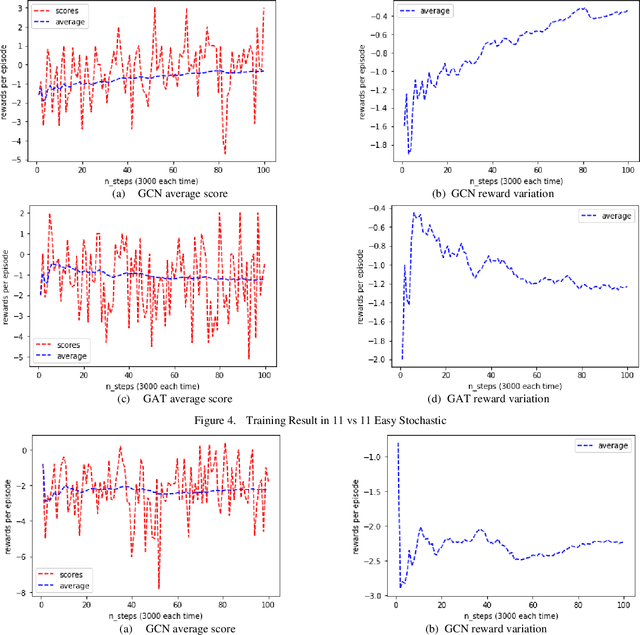
Deep neural networks (DNN) can approximate value functions or policies for reinforcement learning, which makes the reinforcement learning algorithms more powerful. However, some DNNs, such as convolutional neural networks (CNN), cannot extract enough information or take too long to obtain enough features from the inputs under specific circumstances of reinforcement learning. For example, the input data of Google Research Football, a reinforcement learning environment which trains agents to play football, is the small map of players' locations. The information is contained not only in the coordinates of players, but also in the relationships between different players. CNNs can neither extract enough information nor take too long to train. To address this issue, this paper proposes a deep q-learning network (DQN) with a graph neural network (GNN) as its model. The GNN transforms the input data into a graph which better represents the football players' locations so that it extracts more information of the interactions between different players. With two GNNs to approximate its local and target value functions, this DQN allows players to learn from their experience by using value functions to see the prospective value of each intended action. The proposed model demonstrated the power of GNN in the football game by outperforming other DRL models with significantly fewer steps.