 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralization Tower Network: A Novel Deep Neural Network Architecture for Multi-Task Learning
Jan 02, 2018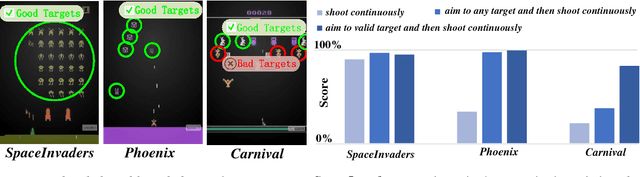
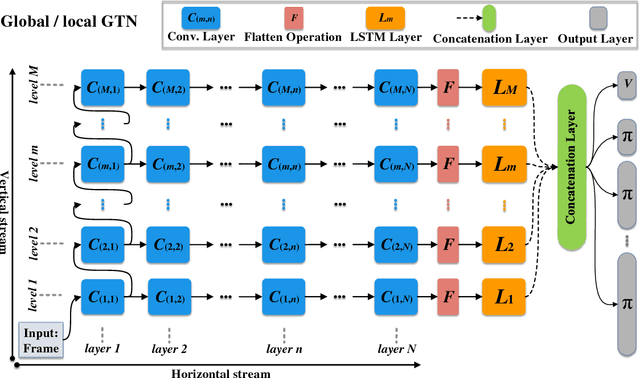
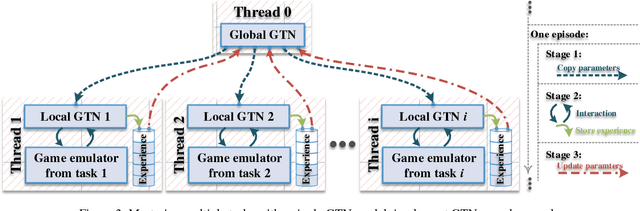
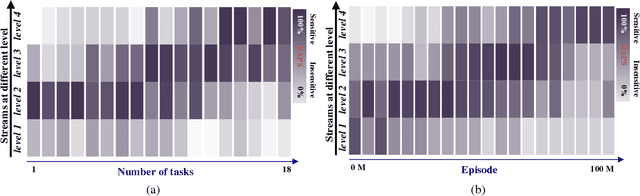
Deep learning (DL) advances state-of-the-art reinforcement learning (RL), by incorporating deep neural networks in learning representations from the input to RL. However, the conventional deep neural network architecture is limited in learning representations for multi-task RL (MT-RL), as multiple tasks can refer to different kinds of representations. In this paper, we thus propose a novel deep neural network architecture, namely generalization tower network (GTN), which can achieve MT-RL within a single learned model. Specifically, the architecture of GTN is composed of both horizontal and vertical streams. In our GTN architecture, horizontal streams are used to learn representation shared in similar tasks. In contrast, the vertical streams are introduced to be more suitable for handling diverse tasks, which encodes hierarchical shared knowledge of these tasks. The effectiveness of the introduced vertical stream is validated by experimental results. Experimental results further verify that our GTN architecture is able to advance the state-of-the-art MT-RL, via being tested on 51 Atari games.
Learning Approximate Stochastic Transition Models
Oct 26, 2017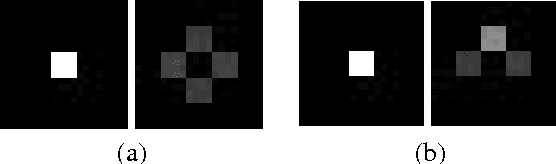


We examine the problem of learning mappings from state to state, suitable for use in a model-based reinforcement-learning setting, that simultaneously generalize to novel states and can capture stochastic transitions. We show that currently popular generative adversarial networks struggle to learn these stochastic transition models but a modification to their loss functions results in a powerful learning algorithm for this class of problems.
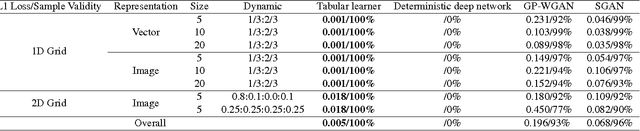
Summable Reparameterizations of Wasserstein Critics in the One-Dimensional Setting
Sep 19, 2017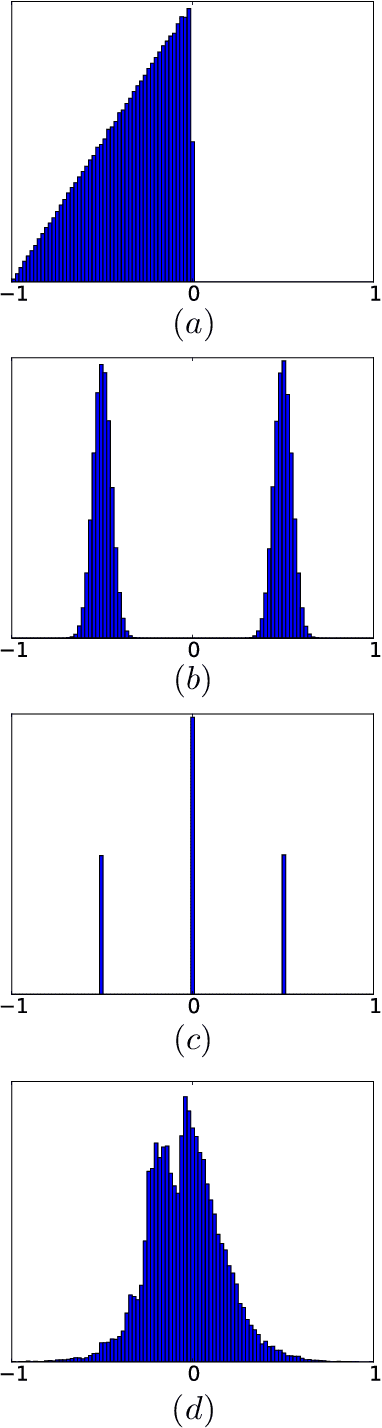
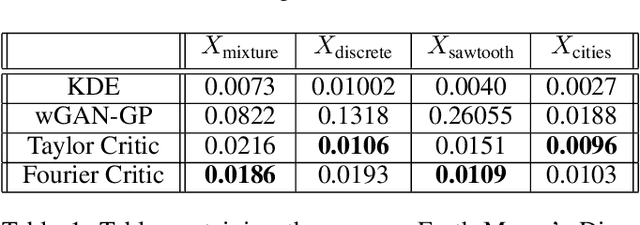
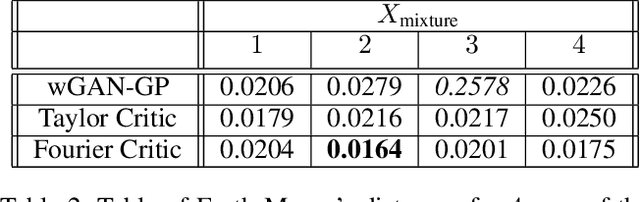
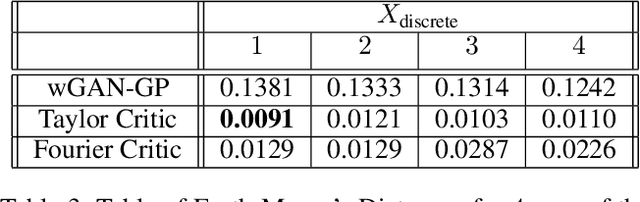
Generative adversarial networks (GANs) are an exciting alternative to algorithms for solving density estimation problems---using data to assess how likely samples are to be drawn from the same distribution. Instead of explicitly computing these probabilities, GANs learn a generator that can match the given probabilistic source. This paper looks particularly at this matching capability in the context of problems with one-dimensional outputs. We identify a class of function decompositions with properties that make them well suited to the critic role in a leading approach to GANs known as Wasserstein GANs. We show that Taylor and Fourier series decompositions belong to our class, provide examples of these critics outperforming standard GAN approaches, and suggest how they can be scaled to higher dimensional problems in the future.
Semantic Segmentation with Reverse Attention
Jul 20, 2017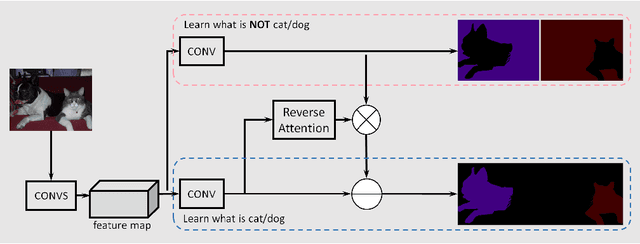
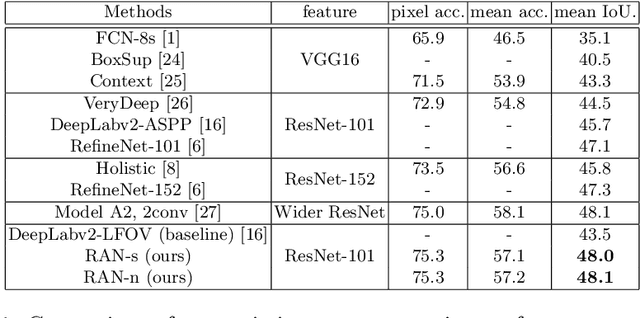
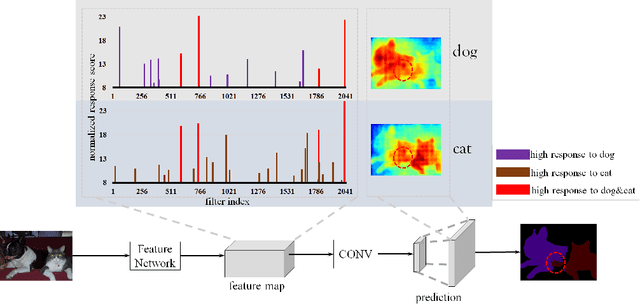
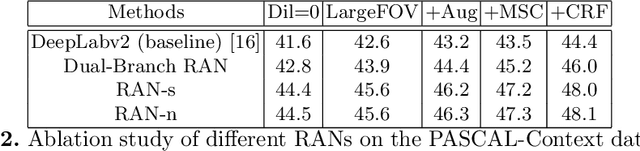
Recent development in fully convolutional neural network enables efficient end-to-end learning of semantic segmentation. Traditionally, the convolutional classifiers are taught to learn the representative semantic features of labeled semantic objects. In this work, we propose a reverse attention network (RAN) architecture that trains the network to capture the opposite concept (i.e., what are not associated with a target class) as well. The RAN is a three-branch network that performs the direct, reverse and reverse-attention learning processes simultaneously. Extensive experiments are conducted to show the effectiveness of the RAN in semantic segmentation. Being built upon the DeepLabv2-LargeFOV, the RAN achieves the state-of-the-art mIoU score (48.1%) for the challenging PASCAL-Context dataset. Significant performance improvements are also observed for the PASCAL-VOC, Person-Part, NYUDv2 and ADE20K datasets.
Object Boundary Guided Semantic Segmentation
Jul 06, 2016
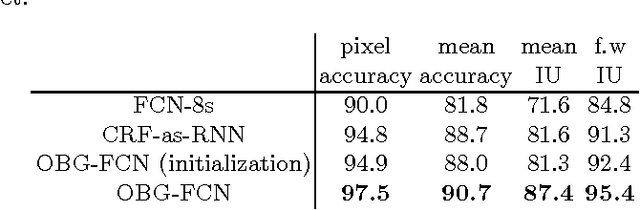

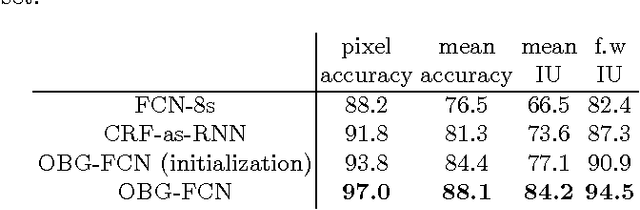
Semantic segmentation is critical to image content understanding and object localization. Recent development in fully-convolutional neural network (FCN) has enabled accurate pixel-level labeling. One issue in previous works is that the FCN based method does not exploit the object boundary information to delineate segmentation details since the object boundary label is ignored in the network training. To tackle this problem, we introduce a double branch fully convolutional neural network, which separates the learning of the desirable semantic class labeling with mask-level object proposals guided by relabeled boundaries. This network, called object boundary guided FCN (OBG-FCN), is able to integrate the distinct properties of object shape and class features elegantly in a fully convolutional way with a designed masking architecture. We conduct experiments on the PASCAL VOC segmentation benchmark, and show that the end-to-end trainable OBG-FCN system offers great improvement in optimizing the target semantic segmentation quality.