 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConSteer-RL: Steering Reasoning Capabilities in Large Language Models via Confidence-Aware Reinforcement Learning
Jun 06, 2026Reinforcement Learning from Verifiable Rewards (RLVR) has recently become a key paradigm for improving the reasoning abilities of Large Language Models (LLMs), yet it remains limited by sparse binary rewards and its ignorance of model-internal uncertainty. In this paper, we propose ConSteer-RL, a simple yet effective framework that integrates token-level confidence signals derived from model log-probabilities into RLVR training. Specifically, building upon the Group Relative Policy Optimization (GRPO) framework, we construct a confidence-aware reward by aggregating per-token probabilities into a scalar confidence score and incorporating it into an awareness-based reward shaping mechanism that penalizes overconfident errors while reinforcing correct and confident reasoning. Experimental results demonstrate that ConSteer-RL consistently outperforms strong GRPO baselines, achieving average improvements of 2.3%-4.0% across different model scales.
FSCA-Net: Feature-Separated Cross-Attention Network for Robust Multi-Dataset Training
Feb 02, 2026Crowd counting plays a vital role in public safety, traffic regulation, and smart city management. However, despite the impressive progress achieved by CNN- and Transformer-based models, their performance often deteriorates when applied across diverse environments due to severe domain discrepancies. Direct joint training on multiple datasets, which intuitively should enhance generalization, instead results in negative transfer, as shared and domain-specific representations become entangled. To address this challenge, we propose the Feature Separation and Cross-Attention Network FSCA-Net, a unified framework that explicitly disentangles feature representations into domain-invariant and domain-specific components. A novel cross-attention fusion module adaptively models interactions between these components, ensuring effective knowledge transfer while preserving dataset-specific discriminability. Furthermore, a mutual information optimization objective is introduced to maximize consistency among domain-invariant features and minimize redundancy among domain-specific ones, promoting complementary shared-private representations. Extensive experiments on multiple crowd counting benchmarks demonstrate that FSCA-Net effectively mitigates negative transfer and achieves state-of-the-art cross-dataset generalization, providing a robust and scalable solution for real-world crowd analysis.
IA-LSTM: Interaction-Aware LSTM for Pedestrian Trajectory Prediction
Nov 26, 2023



Predicting the trajectory of pedestrians in crowd scenarios is indispensable in self-driving or autonomous mobile robot field because estimating the future locations of pedestrians around is beneficial for policy decision to avoid collision. It is a challenging issue because humans have different walking motions and the interactions between humans and objects in the current environment, especially between human themselves, are complex. Previous researches have focused on how to model the human-human interactions, however, neglecting the relative importance of interactions. In order to address this issue, we introduce a novel mechanism based on the correntropy, which not only can measure the relative importance of human-human interactions, but also can build personal space for each pedestrian. We further propose an Interaction Module including this data-driven mechanism that can effectively extract feature representations of dynamic human-human interactions in the scene and calculate corresponding weights to represent the importance of different interactions. To share such social messages among pedestrians, we design an interaction-aware architecture based on the Long Short-Term Memory (LSTM) network for trajectory prediction. We demonstrate the performance of our model on two public datasets and the experimental results demonstrate that our model can achieve better performance than several latest methods with good performance.
Learning Discriminative Features for Crowd Counting
Nov 08, 2023



Crowd counting models in highly congested areas confront two main challenges: weak localization ability and difficulty in differentiating between foreground and background, leading to inaccurate estimations. The reason is that objects in highly congested areas are normally small and high-level features extracted by convolutional neural networks are less discriminative to represent small objects. To address these problems, we propose a learning discriminative features framework for crowd counting, which is composed of a masked feature prediction module (MPM) and a supervised pixel-level contrastive learning module (CLM). The MPM randomly masks feature vectors in the feature map and then reconstructs them, allowing the model to learn about what is present in the masked regions and improving the model's ability to localize objects in high-density regions. The CLM pulls targets close to each other and pushes them far away from background in the feature space, enabling the model to discriminate foreground objects from background. Additionally, the proposed modules can be beneficial in various computer vision tasks, such as crowd counting and object detection, where dense scenes or cluttered environments pose challenges to accurate localization. The proposed two modules are plug-and-play, incorporating the proposed modules into existing models can potentially boost their performance in these scenarios.
Point Annotation Probability Map: Towards Dense Object Counting by Tolerating Annotation Noise
Jul 29, 2023Counting objects in crowded scenes remains a challenge to computer vision. The current deep learning based approach often formulate it as a Gaussian density regression problem. Such a brute-force regression, though effective, may not consider the annotation noise properly which arises from the human annotation process and may lead to different distributions. We conjecture that it would be beneficial to consider the annotation noise in the dense object counting task. To obtain strong robustness against annotation noise, generalized Gaussian distribution (GGD) function with a tunable bandwidth and shape parameter is exploited to form the learning target point annotation probability map, PAPM. Specifically, we first present a hand-designed PAPM method (HD-PAPM), in which we design a function based on GGD to tolerate the annotation noise. For end-to-end training, the hand-designed PAPM may not be optimal for the particular network and dataset. An adaptively learned PAPM method (AL-PAPM) is proposed. To improve the robustness to annotation noise, we design an effective transport cost function based on GGD. With such transport cost constraints, a better PAPM presentation could be adaptively learned with an optimal transport framework from point annotation in an end-to-end manner. Extensive experiments show the superiority of our proposed methods.
Counting Varying Density Crowds Through Density Guided Adaptive Selection CNN and Transformer Estimation
Jun 21, 2022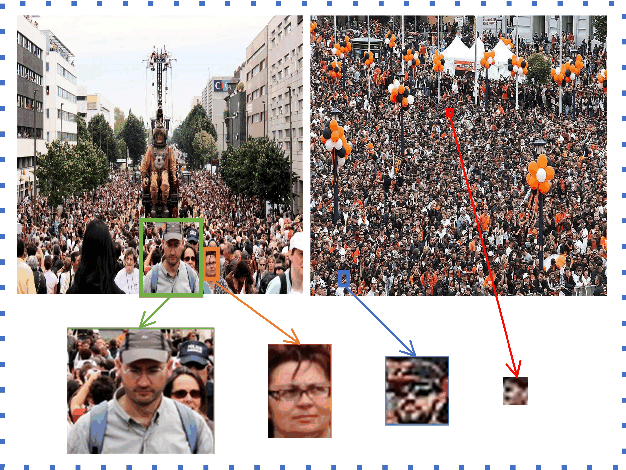

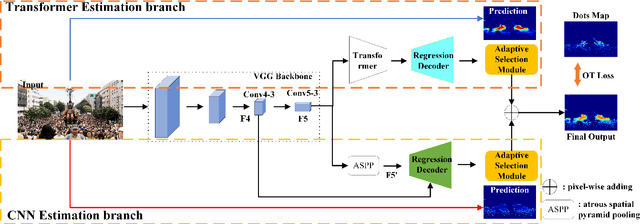
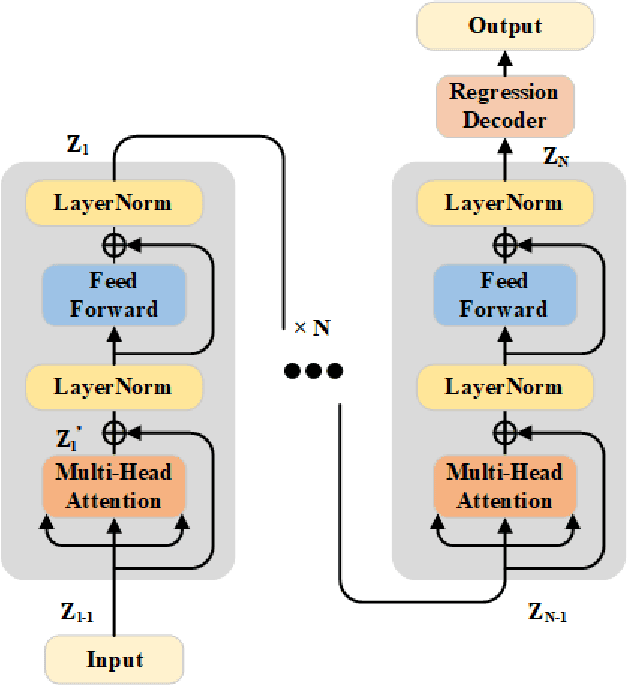
In real-world crowd counting applications, the crowd densities in an image vary greatly. When facing with density variation, human tend to locate and count the target in low-density regions, and reason the number in high-density regions. We observe that CNN focus on the local information correlation using a fixed-size convolution kernel and the Transformer could effectively extract the semantic crowd information by using the global self-attention mechanism. Thus, CNN could locate and estimate crowd accurately in low-density regions, while it is hard to properly perceive density in high-density regions. On the contrary, Transformer, has a high reliability in high-density regions, but fails to locate the target in sparse regions. Neither CNN or Transformer can well deal with this kind of density variations. To address this problem, we propose a CNN and Transformer Adaptive Selection Network (CTASNet) which can adaptively select the appropriate counting branch for different density regions. Firstly, CTASNet generates the prediction results of CNN and Transformer. Then, considering that CNN/Transformer are appropriate for low/high-density regions, a density guided Adaptive Selection Module is designed to automatically combine the predictions of CNN and Transformer. Moreover, to reduce the influences of annotation noise, we introduce a Correntropy based Optimal Transport loss. Extensive experiments on four challenging crowd counting datasets have validated the proposed method.
Region-Aware Network: Model Human's Top-Down Visual Perception Mechanism for Crowd Counting
Jun 23, 2021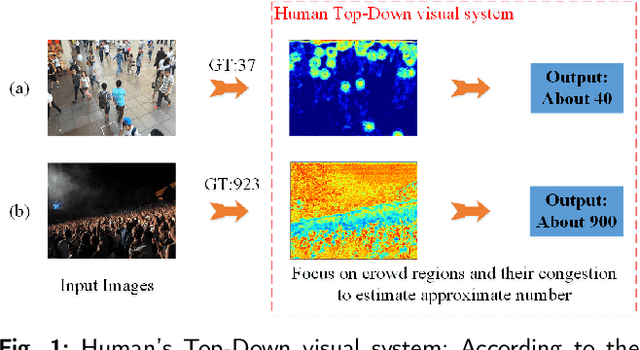

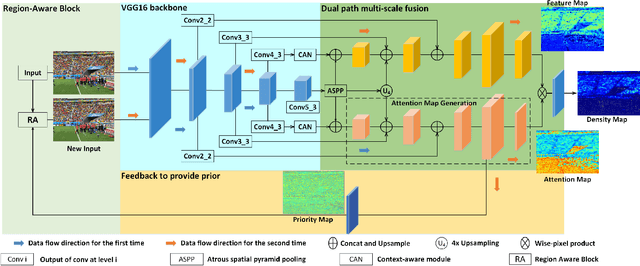
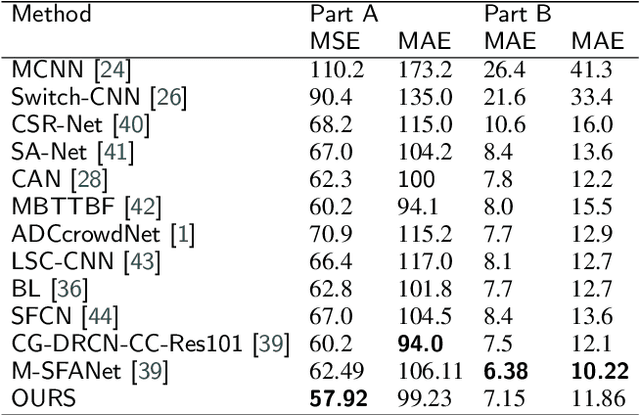
Background noise and scale variation are common problems that have been long recognized in crowd counting. Humans glance at a crowd image and instantly know the approximate number of human and where they are through attention the crowd regions and the congestion degree of crowd regions with a global receptive filed. Hence, in this paper, we propose a novel feedback network with Region-Aware block called RANet by modeling human's Top-Down visual perception mechanism. Firstly, we introduce a feedback architecture to generate priority maps that provide prior about candidate crowd regions in input images. The prior enables the RANet pay more attention to crowd regions. Then we design Region-Aware block that could adaptively encode the contextual information into input images through global receptive field. More specifically, we scan the whole input images and its priority maps in the form of column vector to obtain a relevance matrix estimating their similarity. The relevance matrix obtained would be utilized to build global relationships between pixels. Our method outperforms state-of-the-art crowd counting methods on several public datasets.