 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGID-Net: Detecting Human-Object Interaction with Global and Instance Dependency
Mar 11, 2020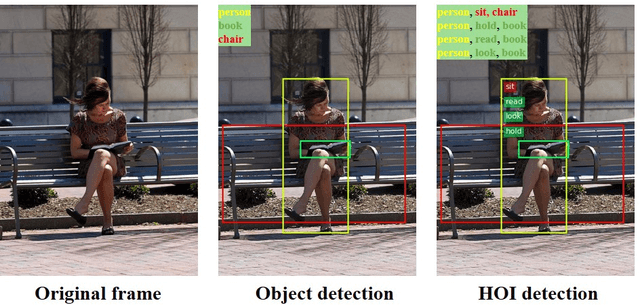
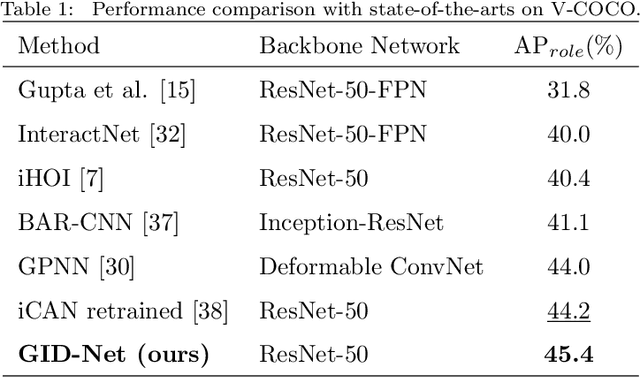
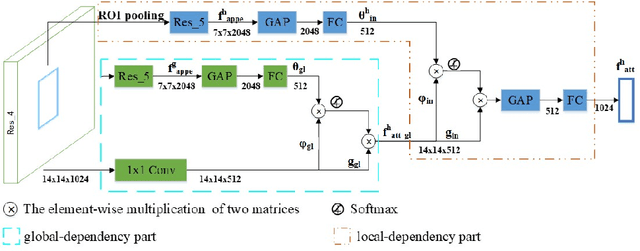
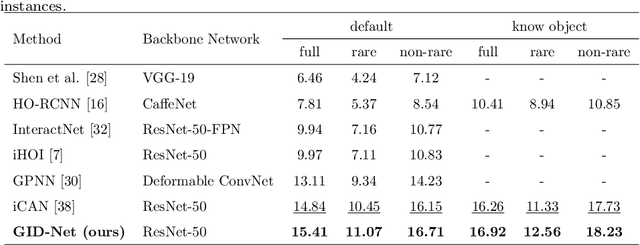
Since detecting and recognizing individual human or object are not adequate to understand the visual world, learning how humans interact with surrounding objects becomes a core technology. However, convolution operations are weak in depicting visual interactions between the instances since they only build blocks that process one local neighborhood at a time. To address this problem, we learn from human perception in observing HOIs to introduce a two-stage trainable reasoning mechanism, referred to as GID block. GID block breaks through the local neighborhoods and captures long-range dependency of pixels both in global-level and instance-level from the scene to help detecting interactions between instances. Furthermore, we conduct a multi-stream network called GID-Net, which is a human-object interaction detection framework consisting of a human branch, an object branch and an interaction branch. Semantic information in global-level and local-level are efficiently reasoned and aggregated in each of the branches. We have compared our proposed GID-Net with existing state-of-the-art methods on two public benchmarks, including V-COCO and HICO-DET. The results have showed that GID-Net outperforms the existing best-performing methods on both the above two benchmarks, validating its efficacy in detecting human-object interactions.
C-RPNs: Promoting Object Detection in real world via a Cascade Structure of Region Proposal Networks
Aug 19, 2019
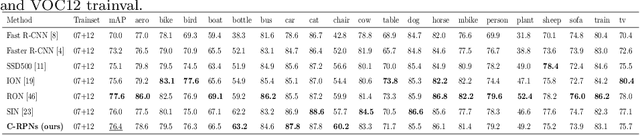
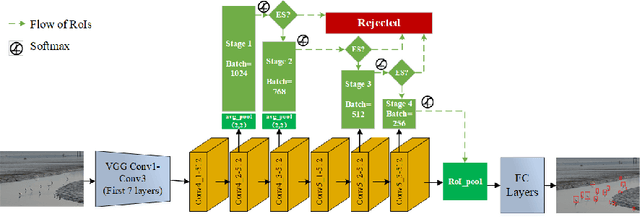

Recently, significant progresses have been made in object detection on common benchmarks (i.e., Pascal VOC). However, object detection in real world is still challenging due to the serious data imbalance. Images in real world are dominated by easy samples like the wide range of background and some easily recognizable objects, for example. Although two-stage detectors like Faster R-CNN achieved big successes in object detection due to the strategy of extracting region proposals by region proposal network, they show their poor adaption in real-world object detection as a result of without considering mining hard samples during extracting region proposals. To address this issue, we propose a Cascade framework of Region Proposal Networks, referred to as C-RPNs. The essence of C-RPNs is adopting multiple stages to mine hard samples while extracting region proposals and learn stronger classifiers. Meanwhile, a feature chain and a score chain are proposed to help learning more discriminative representations for proposals. Moreover, a loss function of cascade stages is designed to train cascade classifiers through backpropagation. Our proposed method has been evaluated on Pascal VOC and several challenging datasets like BSBDV 2017, CityPersons, etc. Our method achieves competitive results compared with the current state-of-the-arts and all-sided improvements in error analysis, validating its efficacy for detection in real world.