 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrowdDriven: A New Challenging Dataset for Outdoor Visual Localization
Sep 09, 2021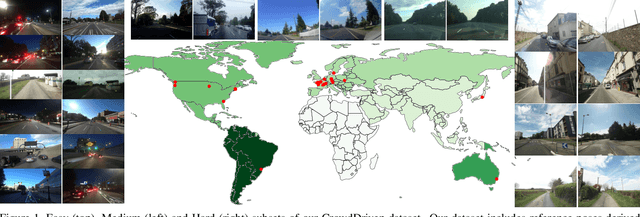


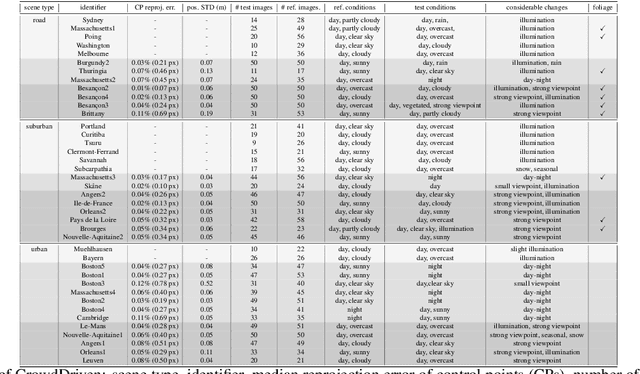
Visual localization is the problem of estimating the position and orientation from which a given image (or a sequence of images) is taken in a known scene. It is an important part of a wide range of computer vision and robotics applications, from self-driving cars to augmented/virtual reality systems. Visual localization techniques should work reliably and robustly under a wide range of conditions, including seasonal, weather, illumination and man-made changes. Recent benchmarking efforts model this by providing images under different conditions, and the community has made rapid progress on these datasets since their inception. However, they are limited to a few geographical regions and often recorded with a single device. We propose a new benchmark for visual localization in outdoor scenes, using crowd-sourced data to cover a wide range of geographical regions and camera devices with a focus on the failure cases of current algorithms. Experiments with state-of-the-art localization approaches show that our dataset is very challenging, with all evaluated methods failing on its hardest parts. As part of the dataset release, we provide the tooling used to generate it, enabling efficient and effective 2D correspondence annotation to obtain reference poses.
Traffic Sign Detection and Classification around the World
Sep 10, 2019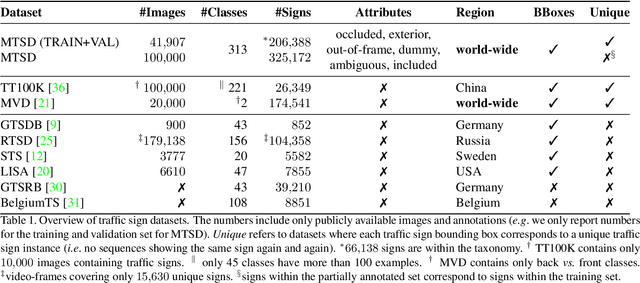
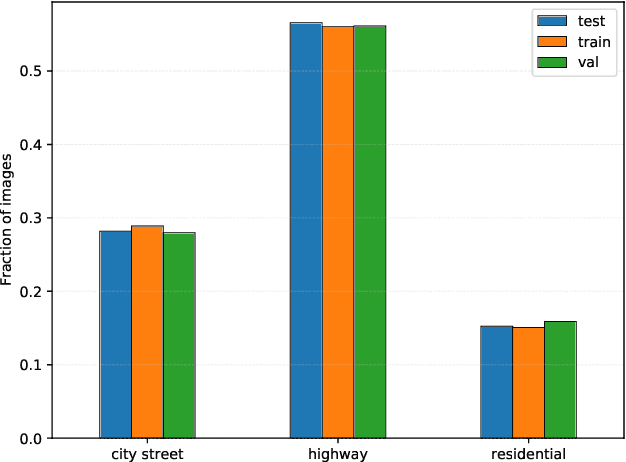
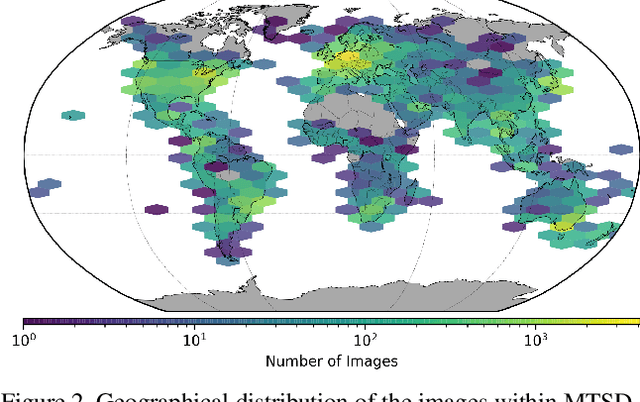
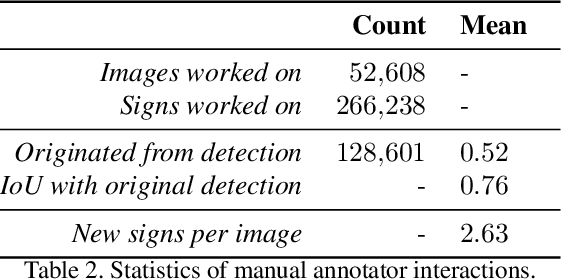
Traffic signs are essential map features globally in the era of autonomous driving and smart cities. To develop accurate and robust algorithms for traffic sign detection and classification, a large-scale and diverse benchmark dataset is required. In this paper, we introduce a traffic sign benchmark dataset of 100K street-level images around the world that encapsulates diverse scenes, wide coverage of geographical locations, and varying weather and lighting conditions and covers more than 300 manually annotated traffic sign classes. The dataset includes 52K images that are fully annotated and 48K images that are partially annotated. This is the largest and the most diverse traffic sign dataset consisting of images from all over world with fine-grained annotations of traffic sign classes. We have run extensive experiments to establish strong baselines for both the detection and the classification tasks. In addition, we have verified that the diversity of this dataset enables effective transfer learning for existing large-scale benchmark datasets on traffic sign detection and classification. The dataset is freely available for academic research: https://www.mapillary.com/dataset/trafficsign.