 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Federated Learning: A Survey through the Lens of Different FL Paradigms
May 27, 2025Multimodal Federated Learning (MFL) lies at the intersection of two pivotal research areas: leveraging complementary information from multiple modalities to improve downstream inference performance and enabling distributed training to enhance efficiency and preserve privacy. Despite the growing interest in MFL, there is currently no comprehensive taxonomy that organizes MFL through the lens of different Federated Learning (FL) paradigms. This perspective is important because multimodal data introduces distinct challenges across various FL settings. These challenges, including modality heterogeneity, privacy heterogeneity, and communication inefficiency, are fundamentally different from those encountered in traditional unimodal or non-FL scenarios. In this paper, we systematically examine MFL within the context of three major FL paradigms: horizontal FL (HFL), vertical FL (VFL), and hybrid FL. For each paradigm, we present the problem formulation, review representative training algorithms, and highlight the most prominent challenge introduced by multimodal data in distributed settings. We also discuss open challenges and provide insights for future research. By establishing this taxonomy, we aim to uncover the novel challenges posed by multimodal data from the perspective of different FL paradigms and to offer a new lens through which to understand and advance the development of MFL.
A Survey on Parameter-Efficient Fine-Tuning for Foundation Models in Federated Learning
Apr 29, 2025



Foundation models have revolutionized artificial intelligence by providing robust, versatile architectures pre-trained on large-scale datasets. However, adapting these massive models to specific downstream tasks requires fine-tuning, which can be prohibitively expensive in computational resources. Parameter-Efficient Fine-Tuning (PEFT) methods address this challenge by selectively updating only a small subset of parameters. Meanwhile, Federated Learning (FL) enables collaborative model training across distributed clients without sharing raw data, making it ideal for privacy-sensitive applications. This survey provides a comprehensive review of the integration of PEFT techniques within federated learning environments. We systematically categorize existing approaches into three main groups: Additive PEFT (which introduces new trainable parameters), Selective PEFT (which fine-tunes only subsets of existing parameters), and Reparameterized PEFT (which transforms model architectures to enable efficient updates). For each category, we analyze how these methods address the unique challenges of federated settings, including data heterogeneity, communication efficiency, computational constraints, and privacy concerns. We further organize the literature based on application domains, covering both natural language processing and computer vision tasks. Finally, we discuss promising research directions, including scaling to larger foundation models, theoretical analysis of federated PEFT methods, and sustainable approaches for resource-constrained environments.
FedMM: Federated Multi-Modal Learning with Modality Heterogeneity in Computational Pathology
Feb 24, 2024The fusion of complementary multimodal information is crucial in computational pathology for accurate diagnostics. However, existing multimodal learning approaches necessitate access to users' raw data, posing substantial privacy risks. While Federated Learning (FL) serves as a privacy-preserving alternative, it falls short in addressing the challenges posed by heterogeneous (yet possibly overlapped) modalities data across various hospitals. To bridge this gap, we propose a Federated Multi-Modal (FedMM) learning framework that federatedly trains multiple single-modal feature extractors to enhance subsequent classification performance instead of existing FL that aims to train a unified multimodal fusion model. Any participating hospital, even with small-scale datasets or limited devices, can leverage these federated trained extractors to perform local downstream tasks (e.g., classification) while ensuring data privacy. Through comprehensive evaluations of two publicly available datasets, we demonstrate that FedMM notably outperforms two baselines in accuracy and AUC metrics.
A Survey on Modern Recommendation System based on Big Data
May 31, 2022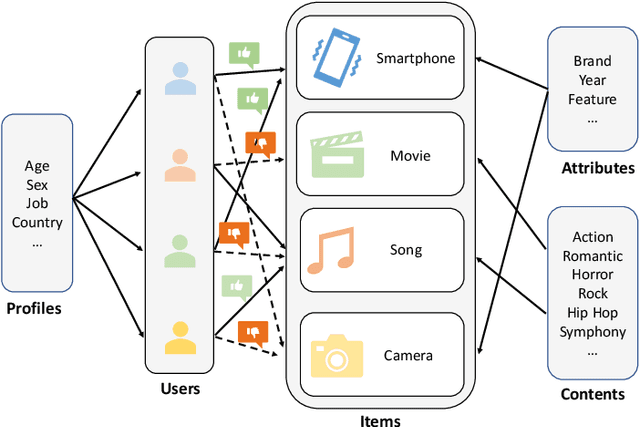
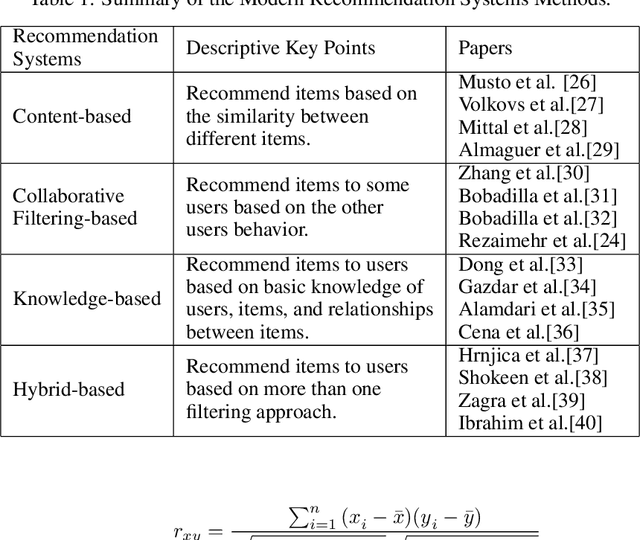
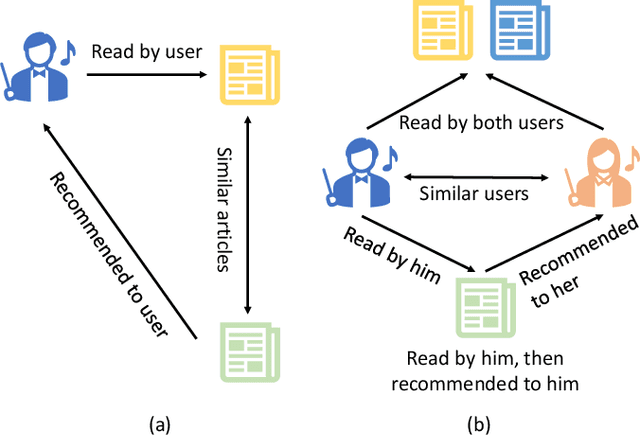

Recommendation systems have become very popular in recent years and are used in various web applications. Modern recommendation systems aim at providing users with personalized recommendations of online products or services. Various recommendation techniques, such as content-based, collaborative filtering-based, knowledge-based, and hybrid-based recommendation systems, have been developed to fulfill the needs in different scenarios. This paper presents a comprehensive review of historical and recent state-of-the-art recommendation approaches, followed by an in-depth analysis of groundbreaking advances in modern recommendation systems based on big data. Furthermore, this paper reviews the issues faced in modern recommendation systems such as sparsity, scalability, and diversity and illustrates how these challenges can be transformed into prolific future research avenues.