 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparsity-Aware Voxel Attention and Foreground Modulation for 3D Semantic Scene Completion
Apr 07, 2026Monocular Semantic Scene Completion (SSC) aims to reconstruct complete 3D semantic scenes from a single RGB image, offering a cost-effective solution for autonomous driving and robotics. However, the inherently imbalanced nature of voxel distributions, where over 93% of voxels are empty and foreground classes are rare, poses significant challenges. Existing methods often suffer from redundant emphasis on uninformative voxels and poor generalization to long-tailed categories. To address these issues, we propose VoxSAMNet (Voxel Sparsity-Aware Modulation Network), a unified framework that explicitly models voxel sparsity and semantic imbalance. Our approach introduces: (1) a Dummy Shortcut for Feature Refinement (DSFR) module that bypasses empty voxels via a shared dummy node while refining occupied ones with deformable attention; and (2) a Foreground Modulation Strategy combining Foreground Dropout (FD) and Text-Guided Image Filter (TGIF) to alleviate overfitting and enhance class-relevant features. Extensive experiments on the public benchmarks SemanticKITTI and SSCBench-KITTI-360 demonstrate that VoxSAMNet achieves state-of-the-art performance, surpassing prior monocular and stereo baselines with mIoU scores of 18.2% and 20.2%, respectively. Our results highlight the importance of sparsity-aware and semantics-guided design for efficient and accurate 3D scene completion, offering a promising direction for future research.
Unified Regularity Measures for Sample-wise Learning and Generalization
Aug 09, 2021

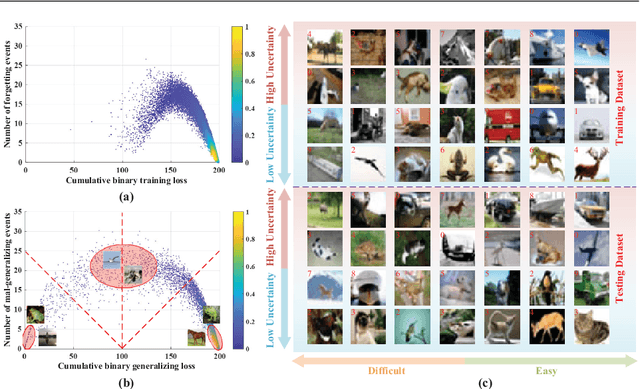
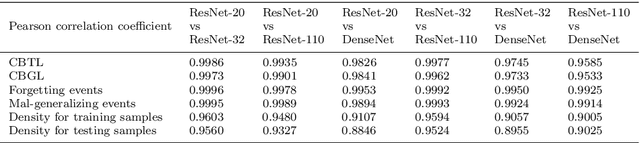
Fundamental machine learning theory shows that different samples contribute unequally both in learning and testing processes. Contemporary studies on DNN imply that such sample di?erence is rooted on the distribution of intrinsic pattern information, namely sample regularity. Motivated by the recent discovery on network memorization and generalization, we proposed a pair of sample regularity measures for both processes with a formulation-consistent representation. Specifically, cumulative binary training/generalizing loss (CBTL/CBGL), the cumulative number of correct classi?cations of the training/testing sample within training stage, is proposed to quantize the stability in memorization-generalization process; while forgetting/mal-generalizing events, i.e., the mis-classification of previously learned or generalized sample, are utilized to represent the uncertainty of sample regularity with respect to optimization dynamics. Experiments validated the effectiveness and robustness of the proposed approaches for mini-batch SGD optimization. Further applications on training/testing sample selection show the proposed measures sharing the uni?ed computing procedure could benefit for both tasks.