 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdverse Weather Image Translation with Asymmetric and Uncertainty-aware GAN
Dec 08, 2021
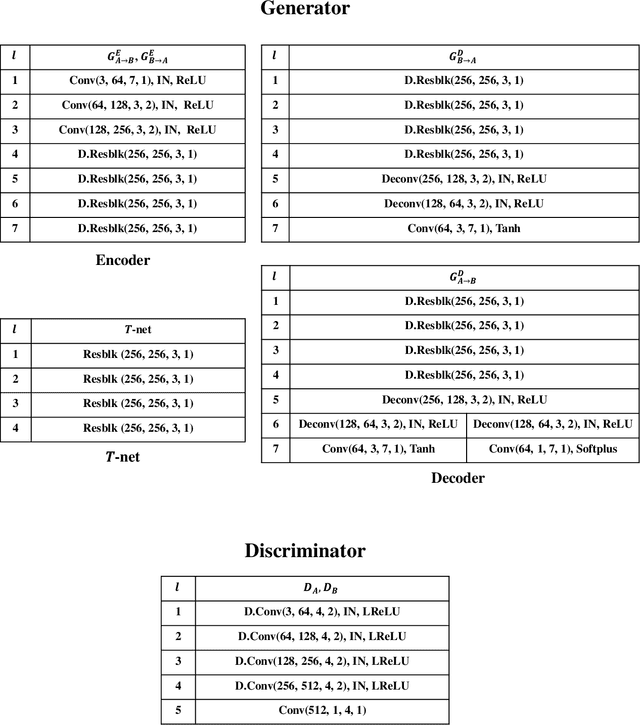


Adverse weather image translation belongs to the unsupervised image-to-image (I2I) translation task which aims to transfer adverse condition domain (eg, rainy night) to standard domain (eg, day). It is a challenging task because images from adverse domains have some artifacts and insufficient information. Recently, many studies employing Generative Adversarial Networks (GANs) have achieved notable success in I2I translation but there are still limitations in applying them to adverse weather enhancement. Symmetric architecture based on bidirectional cycle-consistency loss is adopted as a standard framework for unsupervised domain transfer methods. However, it can lead to inferior translation result if the two domains have imbalanced information. To address this issue, we propose a novel GAN model, i.e., AU-GAN, which has an asymmetric architecture for adverse domain translation. We insert a proposed feature transfer network (${T}$-net) in only a normal domain generator (i.e., rainy night-> day) to enhance encoded features of the adverse domain image. In addition, we introduce asymmetric feature matching for disentanglement of encoded features. Finally, we propose uncertainty-aware cycle-consistency loss to address the regional uncertainty of a cyclic reconstructed image. We demonstrate the effectiveness of our method by qualitative and quantitative comparisons with state-of-the-art models. Codes are available at https://github.com/jgkwak95/AU-GAN.
ModelPS: An Interactive and Collaborative Platform for Editing Pre-trained Models at Scale
May 26, 2021
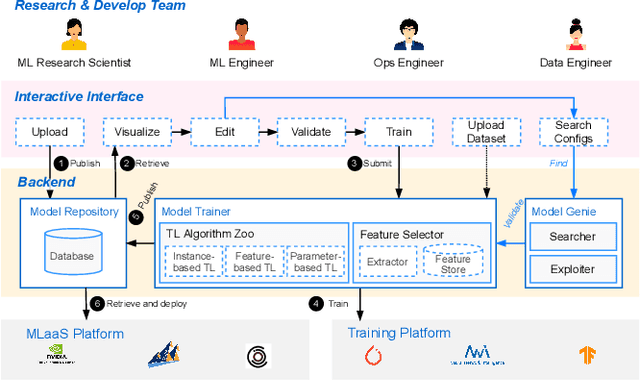
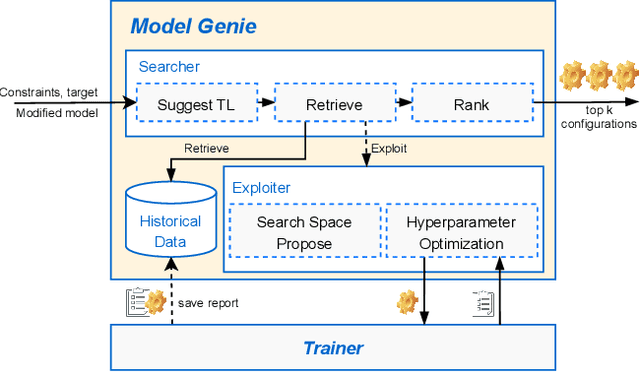
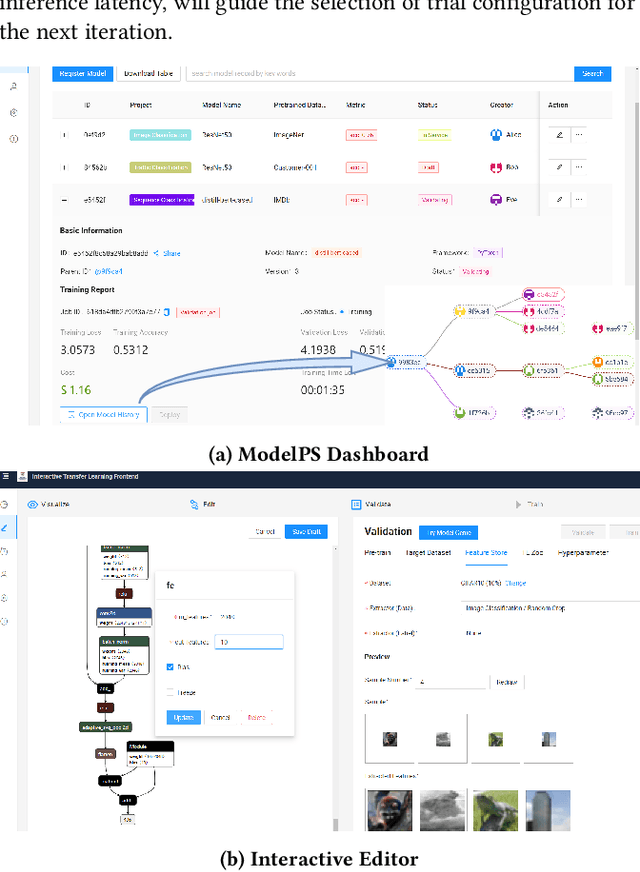
AI engineering has emerged as a crucial discipline to democratize deep neural network (DNN) models among software developers with a diverse background. In particular, altering these DNN models in the deployment stage posits a tremendous challenge. In this research, we propose and develop a low-code solution, ModelPS (an acronym for "Model Photoshop"), to enable and empower collaborative DNN model editing and intelligent model serving. The ModelPS solution embodies two transformative features: 1) a user-friendly web interface for a developer team to share and edit DNN models pictorially, in a low-code fashion, and 2) a model genie engine in the backend to aid developers in customizing model editing configurations for given deployment requirements or constraints. Our case studies with a wide range of deep learning (DL) models show that the system can tremendously reduce both development and communication overheads with improved productivity. The code has been released as an open-source package at GitHub.
Hysia: Serving DNN-Based Video-to-Retail Applications in Cloud
Jun 09, 2020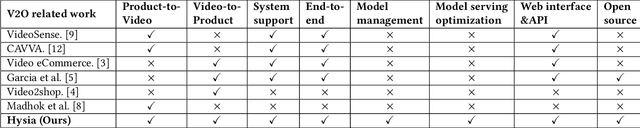
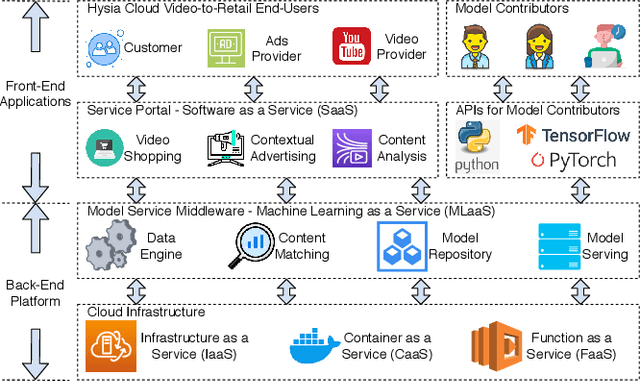
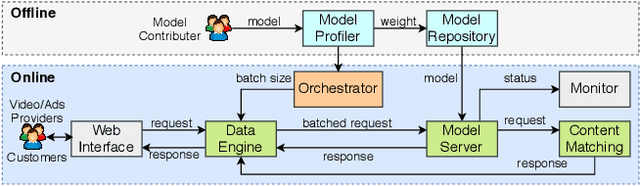
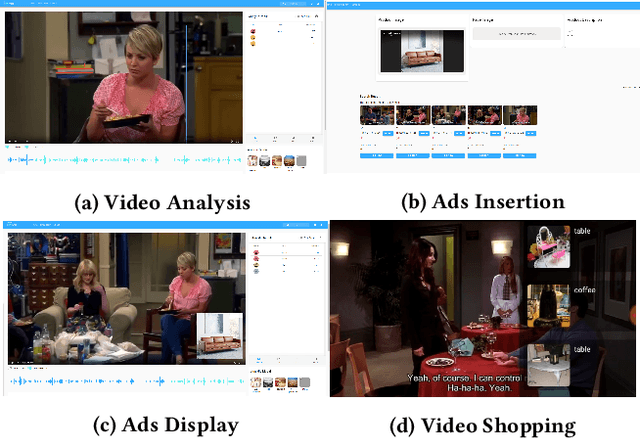
Combining \underline{v}ideo streaming and online \underline{r}etailing (V2R) has been a growing trend recently. In this paper, we provide practitioners and researchers in multimedia with a cloud-based platform named Hysia for easy development and deployment of V2R applications. The system consists of: 1) a back-end infrastructure providing optimized V2R related services including data engine, model repository, model serving and content matching; and 2) an application layer which enables rapid V2R application prototyping. Hysia addresses industry and academic needs in large-scale multimedia by: 1) seamlessly integrating state-of-the-art libraries including NVIDIA video SDK, Facebook faiss, and gRPC; 2) efficiently utilizing GPU computation; and 3) allowing developers to bind new models easily to meet the rapidly changing deep learning (DL) techniques. On top of that, we implement an orchestrator for further optimizing DL model serving performance. Hysia has been released as an open source project on GitHub, and attracted considerable attention. We have published Hysia to DockerHub as an official image for seamless integration and deployment in current cloud environments.
MLModelCI: An Automatic Cloud Platform for Efficient MLaaS
Jun 09, 2020
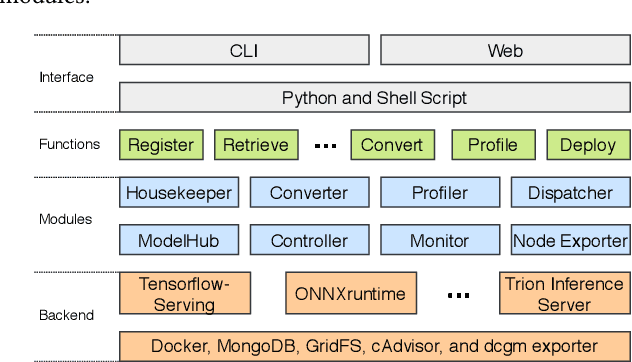
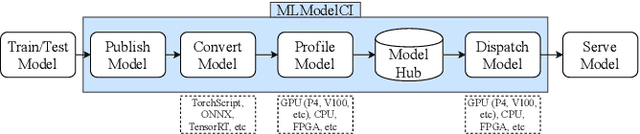
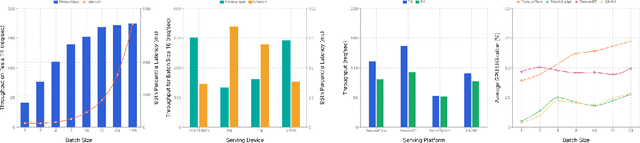
MLModelCI provides multimedia researchers and developers with a one-stop platform for efficient machine learning (ML) services. The system leverages DevOps techniques to optimize, test, and manage models. It also containerizes and deploys these optimized and validated models as cloud services (MLaaS). In its essence, MLModelCI serves as a housekeeper to help users publish models. The models are first automatically converted to optimized formats for production purpose and then profiled under different settings (e.g., batch size and hardware). The profiling information can be used as guidelines for balancing the trade-off between performance and cost of MLaaS. Finally, the system dockerizes the models for ease of deployment to cloud environments. A key feature of MLModelCI is the implementation of a controller, which allows elastic evaluation which only utilizes idle workers while maintaining online service quality. Our system bridges the gap between current ML training and serving systems and thus free developers from manual and tedious work often associated with service deployment. We release the platform as an open-source project on GitHub under Apache 2.0 license, with the aim that it will facilitate and streamline more large-scale ML applications and research projects.