 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocalSUG: Geography-Aware LLM for Query Suggestion in Local-Life Services
Mar 05, 2026In local-life service platforms, the query suggestion module plays a crucial role in enhancing user experience by generating candidate queries based on user input prefixes, thus reducing user effort and accelerating search. Traditional multi-stage cascading systems rely heavily on historical top queries, limiting their ability to address long-tail demand. While LLMs offer strong semantic generalization, deploying them in local-life services introduces three key challenges: lack of geographic grounding, exposure bias in preference optimization, and online inference latency. To address these issues, we propose LocalSUG, an LLM-based query suggestion framework tailored for local-life service platforms. First, we introduce a city-aware candidate mining strategy based on term co-occurrence to inject geographic grounding into generation. Second, we propose a beam-search-driven GRPO algorithm that aligns training with inference-time decoding, reducing exposure bias in autoregressive generation. A multi-objective reward mechanism further optimizes both relevance and business-oriented metrics. Finally, we develop quality-aware beam acceleration and vocabulary pruning techniques that significantly reduce online latency while preserving generation quality. Extensive offline evaluations and large-scale online A/B testing demonstrate that LocalSUG improves click-through rate (CTR) by +0.35% and reduces the low/no-result rate by 2.56%, validating its effectiveness in real-world deployment.
Mingling Foresight with Imagination: Model-Based Cooperative Multi-Agent Reinforcement Learning
Apr 20, 2022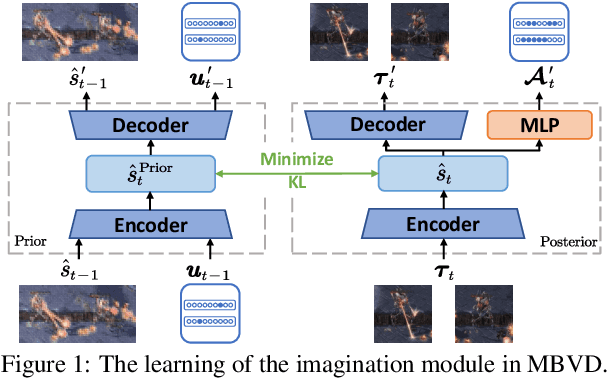
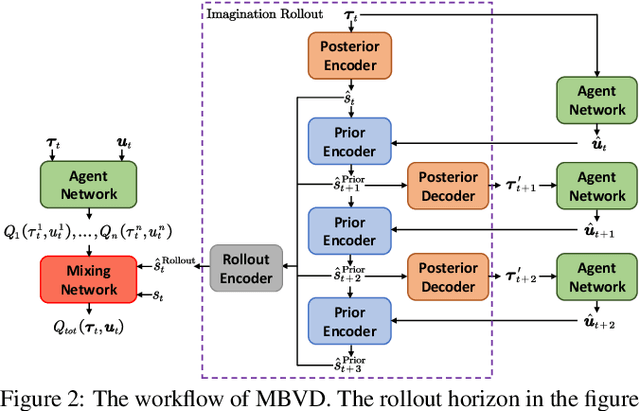
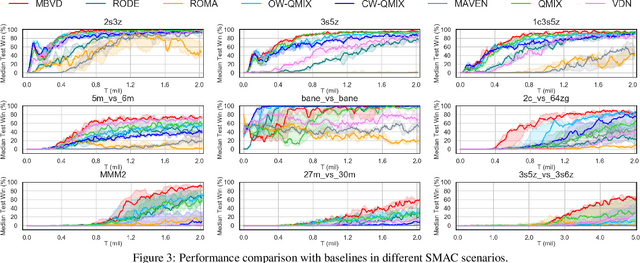

Recently, model-based agents have achieved better performance compared with model-free ones using the same computational budget and training time in single-agent environments. However, due to the complexity of multi-agent systems, it is very difficult to learn the model of the environment. When model-based methods are applied to multi-agent tasks, the significant compounding error may hinder the learning process. In this paper, we propose an implicit model-based multi-agent reinforcement learning method based on value decomposition methods. Under this method, agents can interact with the learned virtual environment and evaluate the current state value according to imagined future states, which makes agents have foresight. Our method can be applied to any multi-agent value decomposition method. The experimental results show that our method improves the sample efficiency in partially observable Markov decision process domains.