 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTriage knowledge distillation for speaker verification
Jan 21, 2026Deploying speaker verification on resource-constrained devices remains challenging due to the computational cost of high-capacity models; knowledge distillation (KD) offers a remedy. Classical KD entangles target confidence with non-target structure in a Kullback-Leibler term, limiting the transfer of relational information. Decoupled KD separates these signals into target and non-target terms, yet treats non-targets uniformly and remains vulnerable to the long tail of low-probability classes in large-class settings. We introduce Triage KD (TRKD), a distillation scheme that operationalizes assess-prioritize-focus. TRKD introduces a cumulative-probability cutoff $τ$ to assess per-example difficulty and partition the teacher posterior into three groups: the target class, a high-probability non-target confusion-set, and a background-set. To prioritize informative signals, TRKD distills the confusion-set conditional distribution and discards the background. Concurrently, it transfers a three-mass (target/confusion/background) that capture sample difficulty and inter-class confusion. Finally, TRKD focuses learning via a curriculum on $τ$: training begins with a larger $τ$ to convey broad non-target context, then $τ$ is progressively decreased to shrink the confusion-set, concentrating supervision on the most confusable classes. In extensive experiments on VoxCeleb1 with both homogeneous and heterogeneous teacher-student pairs, TRKD was consistently superior to recent KD variants and attained the lowest EER across all protocols.
DAME: Duration-Aware Matryoshka Embedding for Duration-Robust Speaker Verification
Jan 20, 2026Short-utterance speaker verification remains challenging due to limited speaker-discriminative cues in short speech segments. While existing methods focus on enhancing speaker encoders, the embedding learning strategy still forces a single fixed-dimensional representation reused for utterances of any length, leaving capacity misaligned with the information available at different durations. We propose Duration-Aware Matryoshka Embedding (DAME), a model-agnostic framework that builds a nested hierarchy of sub-embeddings aligned to utterance durations: lower-dimensional representations capture compact speaker traits from short utterances, while higher dimensions encode richer details from longer speech. DAME supports both training from scratch and fine-tuning, and serves as a direct alternative to conventional large-margin fine-tuning, consistently improving performance across durations. On the VoxCeleb1-O/E/H and VOiCES evaluation sets, DAME consistently reduces the equal error rate on 1-s and other short-duration trials, while maintaining full-length performance with no additional inference cost. These gains generalize across various speaker encoder architectures under both general training and fine-tuning setups.
MATE: Matryoshka Audio-Text Embeddings for Open-Vocabulary Keyword Spotting
Jan 20, 2026Open-vocabulary keyword spotting (KWS) with text-based enrollment has emerged as a flexible alternative to fixed-phrase triggers. Prior utterance-level matching methods, from an embedding-learning standpoint, learn embeddings at a single fixed dimensionality. We depart from this design and propose Matryoshka Audio-Text Embeddings (MATE), a dual-encoder framework that encodes multiple embedding granularities within a single vector via nested sub-embeddings ("prefixes"). Specifically, we introduce a PCA-guided prefix alignment: PCA-compressed versions of the full text embedding for each prefix size serve as teacher targets to align both audio and text prefixes. This alignment concentrates salient keyword cues in lower-dimensional prefixes, while higher dimensions add detail. MATE is trained with standard deep metric learning objectives for audio-text KWS, and is loss-agnostic. To our knowledge, this is the first application of matryoshka-style embeddings to KWS, achieving state-of-the-art results on WSJ and LibriPhrase without any inference overhead.
Relational Proxy Loss for Audio-Text based Keyword Spotting
Jun 08, 2024



In recent years, there has been an increasing focus on user convenience, leading to increased interest in text-based keyword enrollment systems for keyword spotting (KWS). Since the system utilizes text input during the enrollment phase and audio input during actual usage, we call this task audio-text based KWS. To enable this task, both acoustic and text encoders are typically trained using deep metric learning loss functions, such as triplet- and proxy-based losses. This study aims to improve existing methods by leveraging the structural relations within acoustic embeddings and within text embeddings. Unlike previous studies that only compare acoustic and text embeddings on a point-to-point basis, our approach focuses on the relational structures within the embedding space by introducing the concept of Relational Proxy Loss (RPL). By incorporating RPL, we demonstrated improved performance on the Wall Street Journal (WSJ) corpus.
Improving Transformer-based End-to-End Speaker Diarization by Assigning Auxiliary Losses to Attention Heads
Mar 02, 2023Transformer-based end-to-end neural speaker diarization (EEND) models utilize the multi-head self-attention (SA) mechanism to enable accurate speaker label prediction in overlapped speech regions. In this study, to enhance the training effectiveness of SA-EEND models, we propose the use of auxiliary losses for the SA heads of the transformer layers. Specifically, we assume that the attention weight matrices of an SA layer are redundant if their patterns are similar to those of the identity matrix. We then explicitly constrain such matrices to exhibit specific speaker activity patterns relevant to voice activity detection or overlapped speech detection tasks. Consequently, we expect the proposed auxiliary losses to guide the transformer layers to exhibit more diverse patterns in the attention weights, thereby reducing the assumed redundancies in the SA heads. The effectiveness of the proposed method is demonstrated using the simulated and CALLHOME datasets for two-speaker diarization tasks, reducing the diarization error rate of the conventional SA-EEND model by 32.58% and 17.11%, respectively.
Task-specific Optimization of Virtual Channel Linear Prediction-based Speech Dereverberation Front-End for Far-Field Speaker Verification
Dec 27, 2021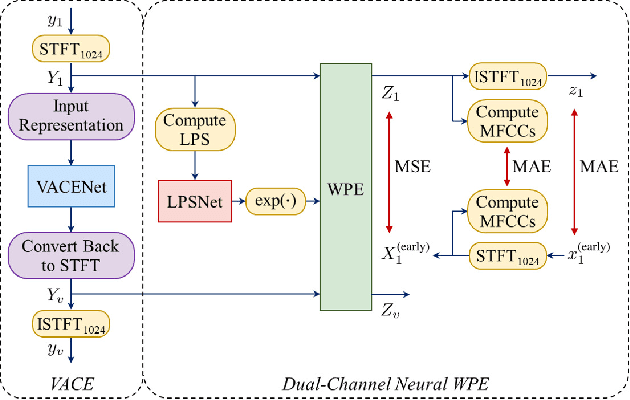
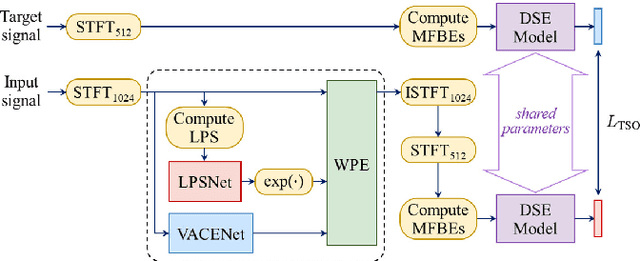
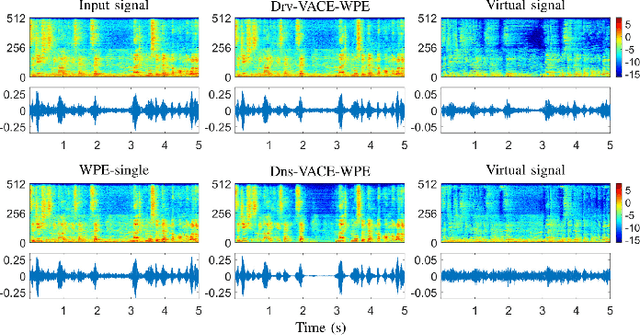
Developing a single-microphone speech denoising or dereverberation front-end for robust automatic speaker verification (ASV) in noisy far-field speaking scenarios is challenging. To address this problem, we present a novel front-end design that involves a recently proposed extension of the weighted prediction error (WPE) speech dereverberation algorithm, the virtual acoustic channel expansion (VACE)-WPE. It is demonstrated experimentally in this study that unlike the conventional WPE algorithm, the VACE-WPE can be explicitly trained to cancel out both late reverberation and background noise. To build the front-end, the VACE-WPE is first independently (pre)trained to produce "noisy" dereverberated signals. Subsequently, given a pretrained speaker embedding model, the VACE-WPE is additionally fine-tuned within a task-specific optimization (TSO) framework, causing the speaker embedding extracted from the processed signal to be similar to that extracted from the "noise-free" target signal. Moreover, to extend the application of the proposed front-end to more general, unconstrained "in-the-wild" ASV scenarios beyond controlled far-field conditions, we propose a distortion regularization method for the VACE-WPE within the TSO framework. The effectiveness of the proposed approach is verified on both far-field and in-the-wild ASV benchmarks, demonstrating its superiority over fully neural front-ends and other TSO methods in various cases.
VACE-WPE: Virtual Acoustic Channel Expansion Based On Neural Networks for Weighted Prediction Error-Based Speech Dereverberation
Feb 10, 2021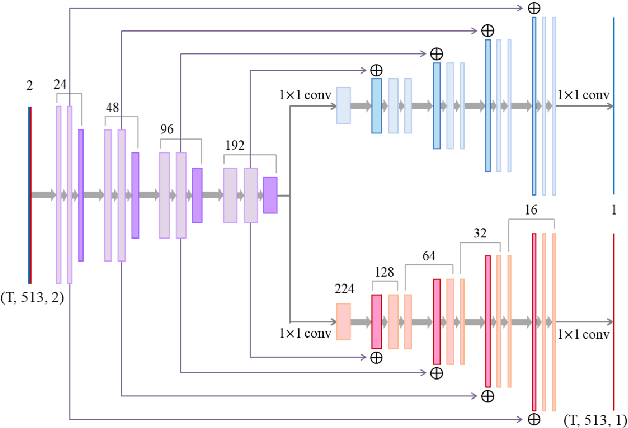

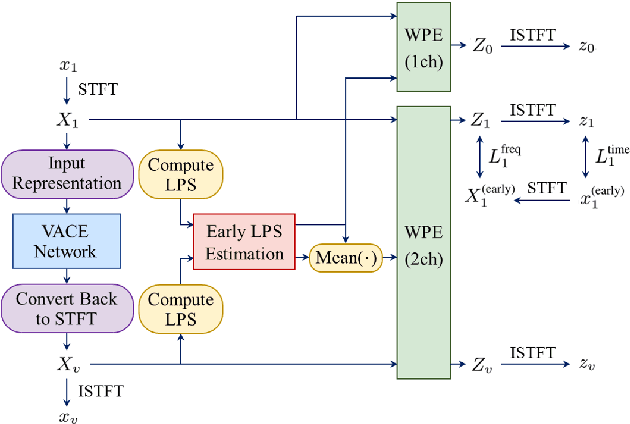
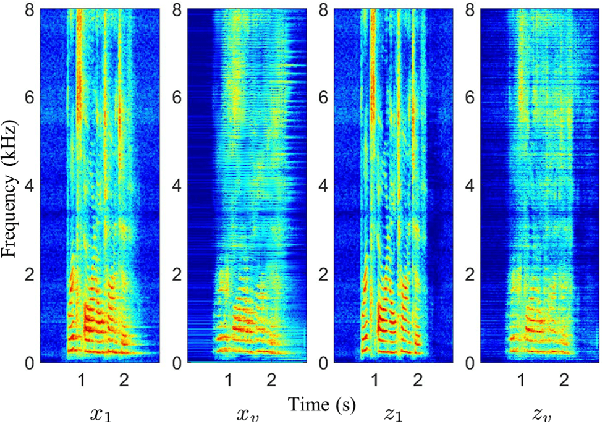
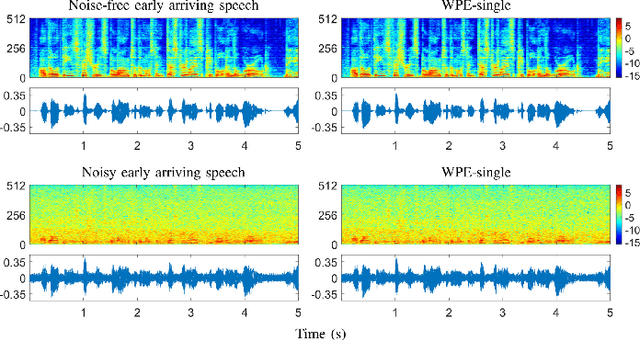
Speech dereverberation is an important issue for many real-world speech processing applications. Among the techniques developed, the weighted prediction error (WPE) algorithm has been widely adopted and advanced over the last decade, which blindly cancels out the late reverberation component from the reverberant mixture of microphone signals. In this study, we extend the neural-network-based virtual acoustic channel expansion (VACE) framework for the WPE-based speech dereverberation, a variant of the WPE that we recently proposed to enable the use of dual-channel WPE algorithm in a single-microphone speech dereverberation scenario. Based on the previous study, some ablation studies are conducted regarding the constituents of the VACE-WPE in an offline processing scenario. These studies help understand the dynamics of the system, thereby simplifying the architecture and leading to the introduction of new strategies for training the neural network for the VACE. Experimental results in noisy reverberant environments reveal that VACE-WPE considerably outperforms its single-channel counterpart in terms of objective speech quality and is complementary to the single-channel WPE when employed as the front-end for the far-field automatic speech recognizer.