 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePose Splatter: A 3D Gaussian Splatting Model for Quantifying Animal Pose and Appearance
May 23, 2025Accurate and scalable quantification of animal pose and appearance is crucial for studying behavior. Current 3D pose estimation techniques, such as keypoint- and mesh-based techniques, often face challenges including limited representational detail, labor-intensive annotation requirements, and expensive per-frame optimization. These limitations hinder the study of subtle movements and can make large-scale analyses impractical. We propose Pose Splatter, a novel framework leveraging shape carving and 3D Gaussian splatting to model the complete pose and appearance of laboratory animals without prior knowledge of animal geometry, per-frame optimization, or manual annotations. We also propose a novel rotation-invariant visual embedding technique for encoding pose and appearance, designed to be a plug-in replacement for 3D keypoint data in downstream behavioral analyses. Experiments on datasets of mice, rats, and zebra finches show Pose Splatter learns accurate 3D animal geometries. Notably, Pose Splatter represents subtle variations in pose, provides better low-dimensional pose embeddings over state-of-the-art as evaluated by humans, and generalizes to unseen data. By eliminating annotation and per-frame optimization bottlenecks, Pose Splatter enables analysis of large-scale, longitudinal behavior needed to map genotype, neural activity, and micro-behavior at unprecedented resolution.
Controllable Style Transfer via Test-time Training of Implicit Neural Representation
Oct 17, 2022
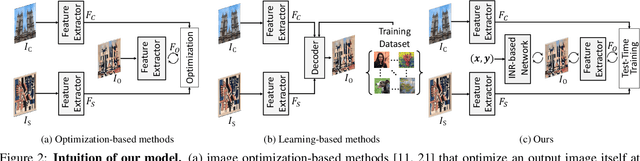
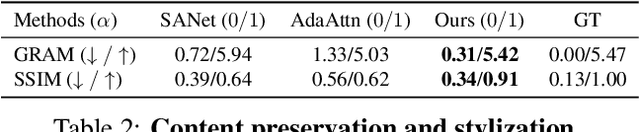

We propose a controllable style transfer framework based on Implicit Neural Representation that pixel-wisely controls the stylized output via test-time training. Unlike traditional image optimization methods that often suffer from unstable convergence and learning-based methods that require intensive training and have limited generalization ability, we present a model optimization framework that optimizes the neural networks during test-time with explicit loss functions for style transfer. After being test-time trained once, thanks to the flexibility of the INR-based model, our framework can precisely control the stylized images in a pixel-wise manner and freely adjust image resolution without further optimization or training. We demonstrate several applications.
ConMatch: Semi-Supervised Learning with Confidence-Guided Consistency Regularization
Aug 18, 2022
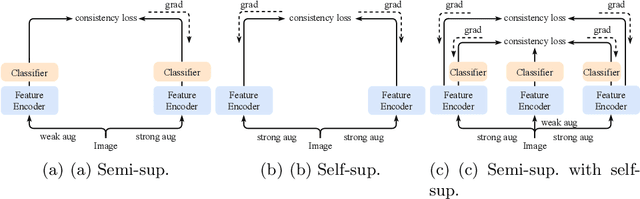
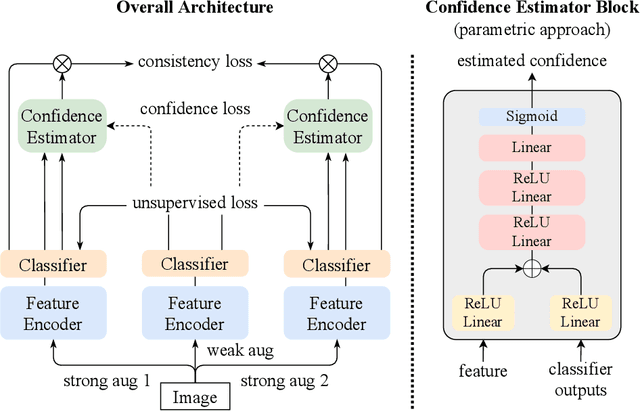
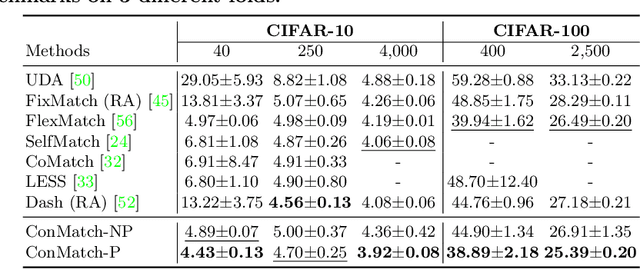
We present a novel semi-supervised learning framework that intelligently leverages the consistency regularization between the model's predictions from two strongly-augmented views of an image, weighted by a confidence of pseudo-label, dubbed ConMatch. While the latest semi-supervised learning methods use weakly- and strongly-augmented views of an image to define a directional consistency loss, how to define such direction for the consistency regularization between two strongly-augmented views remains unexplored. To account for this, we present novel confidence measures for pseudo-labels from strongly-augmented views by means of weakly-augmented view as an anchor in non-parametric and parametric approaches. Especially, in parametric approach, we present, for the first time, to learn the confidence of pseudo-label within the networks, which is learned with backbone model in an end-to-end manner. In addition, we also present a stage-wise training to boost the convergence of training. When incorporated in existing semi-supervised learners, ConMatch consistently boosts the performance. We conduct experiments to demonstrate the effectiveness of our ConMatch over the latest methods and provide extensive ablation studies. Code has been made publicly available at https://github.com/JiwonCocoder/ConMatch.
Joint Learning of Feature Extraction and Cost Aggregation for Semantic Correspondence
Apr 19, 2022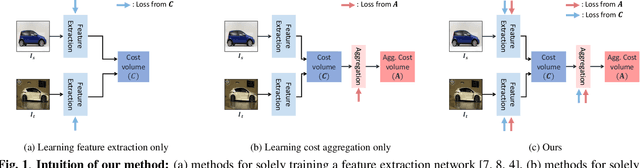
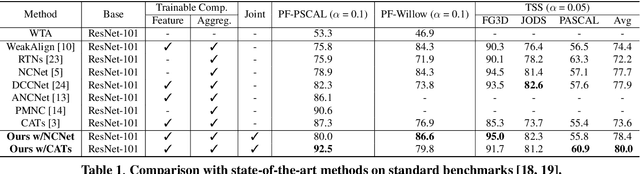

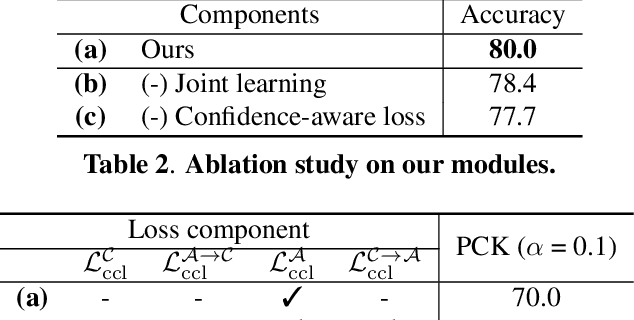
Establishing dense correspondences across semantically similar images is one of the challenging tasks due to the significant intra-class variations and background clutters. To solve these problems, numerous methods have been proposed, focused on learning feature extractor or cost aggregation independently, which yields sub-optimal performance. In this paper, we propose a novel framework for jointly learning feature extraction and cost aggregation for semantic correspondence. By exploiting the pseudo labels from each module, the networks consisting of feature extraction and cost aggregation modules are simultaneously learned in a boosting fashion. Moreover, to ignore unreliable pseudo labels, we present a confidence-aware contrastive loss function for learning the networks in a weakly-supervised manner. We demonstrate our competitive results on standard benchmarks for semantic correspondence.