 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTorus Graphs for Large Scale Neural Phase Analysis
May 30, 2026Oscillatory neural signals such as electroencephalography (EEG) and local field potentials (LFPs) show phase relationships that coordinate communication across brain regions. Modern recordings capture hundreds of channels across many frequency bins, yet standard phase analyses are restricted to only a few variables. The Torus Graph (TG) model, an exponential-family distribution over phases whose univariate and pairwise potentials generalize von Mises distributions, infers principled structure among oscillations but models only static, undirected dependencies and is limited to $\sim \! 100$ variables because its score matching inference scales as $\mathcal{O}(d^{6})$. We introduce a stochastic score matching procedure that reduces the per-iteration cost to $\mathcal{O}(d^{2})$, enabling inference on datasets with thousands of variables. This scalable foundation supports analyses of 1,860 frequency-phase features from multi-electrode LFPs and enables two extensions previously inaccessible to TGs or classical circular statistics: (i) a TG Hidden Markov Model capturing state-dependent phase-coupling changes (e.g., spindle-related states during sleep) and (ii) an autoregressive TG inferring directional interactions via transfer-entropy estimation. Applied to LFP recordings, these models reveal state-dependent phase-interaction patterns between wakefulness and NREM sleep. Together, they enable systematic, large-scale mapping of dynamic and directional phase relationships across brain and cognitive states.
HiPPO Zoo: Explicit Memory Mechanisms for Interpretable State Space Models
Feb 24, 2026Representing the past in a compressed, efficient, and informative manner is a central problem for systems trained on sequential data. The HiPPO framework, originally proposed by Gu & Dao et al., provides a principled approach to sequential compression by projecting signals onto orthogonal polynomial (OP) bases via structured linear ordinary differential equations. Subsequent works have embedded these dynamics in state space models (SSMs), where HiPPO structure serves as an initialization. Nonlinear successors of these SSM methods such as Mamba are state-of-the-art for many tasks with long-range dependencies, but the mechanisms by which they represent and prioritize history remain largely implicit. In this work, we revisit the HiPPO framework with the goal of making these mechanisms explicit. We show how polynomial representations of history can be extended to support capabilities of modern SSMs such as adaptive allocation of memory and associative memory while retaining direct interpretability in the OP basis. We introduce a unified framework comprising five such extensions, which we collectively refer to as a "HiPPO zoo." Each extension exposes a specific modeling capability through an explicit, interpretable modification of the HiPPO framework. The resulting models adapt their memory online and train in streaming settings with efficient updates. We illustrate the behaviors and modeling advantages of these extensions through a range of synthetic sequence modeling tasks, demonstrating that capabilities typically associated with modern SSMs can be realized through explicit, interpretable polynomial memory structures.
Pose Splatter: A 3D Gaussian Splatting Model for Quantifying Animal Pose and Appearance
May 23, 2025Accurate and scalable quantification of animal pose and appearance is crucial for studying behavior. Current 3D pose estimation techniques, such as keypoint- and mesh-based techniques, often face challenges including limited representational detail, labor-intensive annotation requirements, and expensive per-frame optimization. These limitations hinder the study of subtle movements and can make large-scale analyses impractical. We propose Pose Splatter, a novel framework leveraging shape carving and 3D Gaussian splatting to model the complete pose and appearance of laboratory animals without prior knowledge of animal geometry, per-frame optimization, or manual annotations. We also propose a novel rotation-invariant visual embedding technique for encoding pose and appearance, designed to be a plug-in replacement for 3D keypoint data in downstream behavioral analyses. Experiments on datasets of mice, rats, and zebra finches show Pose Splatter learns accurate 3D animal geometries. Notably, Pose Splatter represents subtle variations in pose, provides better low-dimensional pose embeddings over state-of-the-art as evaluated by humans, and generalizes to unseen data. By eliminating annotation and per-frame optimization bottlenecks, Pose Splatter enables analysis of large-scale, longitudinal behavior needed to map genotype, neural activity, and micro-behavior at unprecedented resolution.
Distillation Learning Guided by Image Reconstruction for One-Shot Medical Image Segmentation
Aug 07, 2024



Traditional one-shot medical image segmentation (MIS) methods use registration networks to propagate labels from a reference atlas or rely on comprehensive sampling strategies to generate synthetic labeled data for training. However, these methods often struggle with registration errors and low-quality synthetic images, leading to poor performance and generalization. To overcome this, we introduce a novel one-shot MIS framework based on knowledge distillation, which allows the network to directly 'see' real images through a distillation process guided by image reconstruction. It focuses on anatomical structures in a single labeled image and a few unlabeled ones. A registration-based data augmentation network creates realistic, labeled samples, while a feature distillation module helps the student network learn segmentation from these samples, guided by the teacher network. During inference, the streamlined student network accurately segments new images. Evaluations on three public datasets (OASIS for T1 brain MRI, BCV for abdomen CT, and VerSe for vertebrae CT) show superior segmentation performance and generalization across different medical image datasets and modalities compared to leading methods. Our code is available at https://github.com/NoviceFodder/OS-MedSeg.
On Target Shift in Adversarial Domain Adaptation
Mar 15, 2019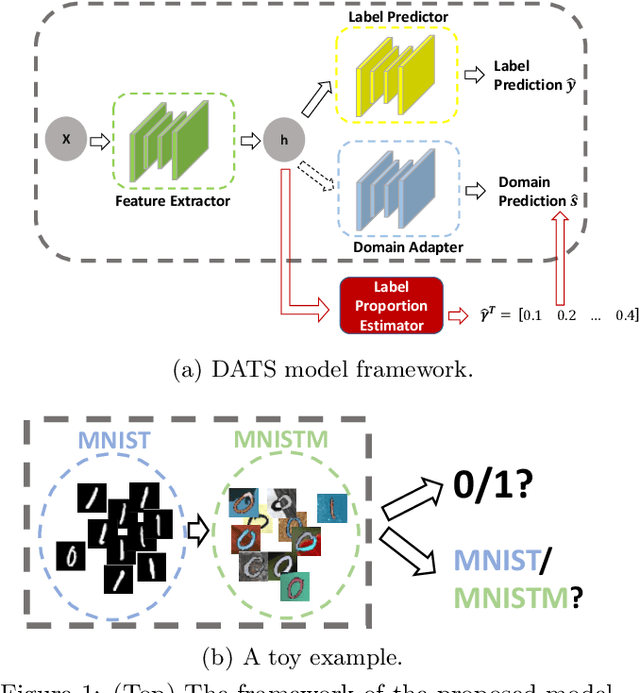
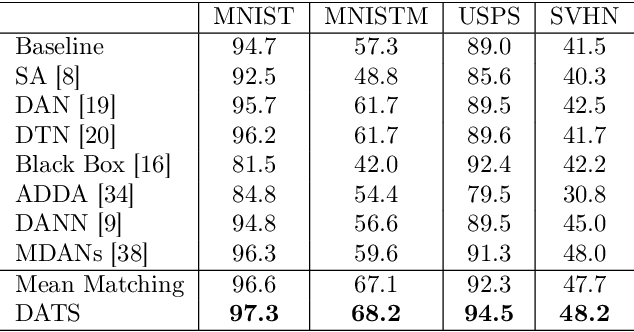
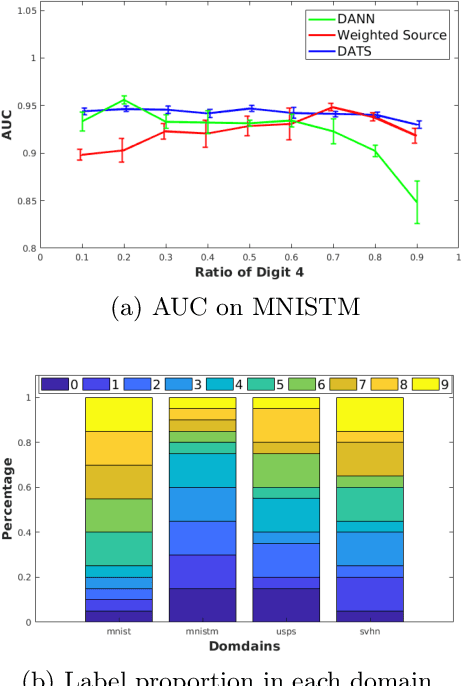
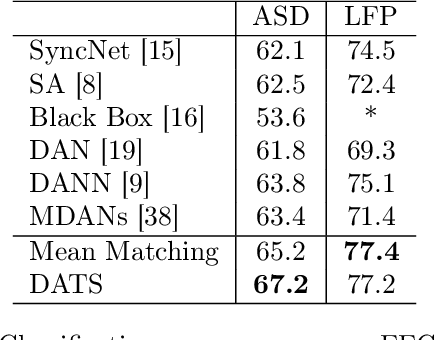
Discrepancy between training and testing domains is a fundamental problem in the generalization of machine learning techniques. Recently, several approaches have been proposed to learn domain invariant feature representations through adversarial deep learning. However, label shift, where the percentage of data in each class is different between domains, has received less attention. Label shift naturally arises in many contexts, especially in behavioral studies where the behaviors are freely chosen. In this work, we propose a method called Domain Adversarial nets for Target Shift (DATS) to address label shift while learning a domain invariant representation. This is accomplished by using distribution matching to estimate label proportions in a blind test set. We extend this framework to handle multiple domains by developing a scheme to upweight source domains most similar to the target domain. Empirical results show that this framework performs well under large label shift in synthetic and real experiments, demonstrating the practical importance.