 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasked LARk: Masked Learning, Aggregation and Reporting worKflow
Oct 27, 2021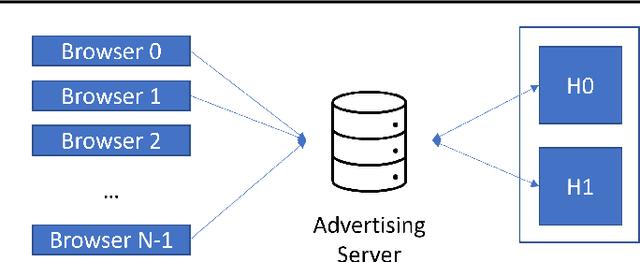
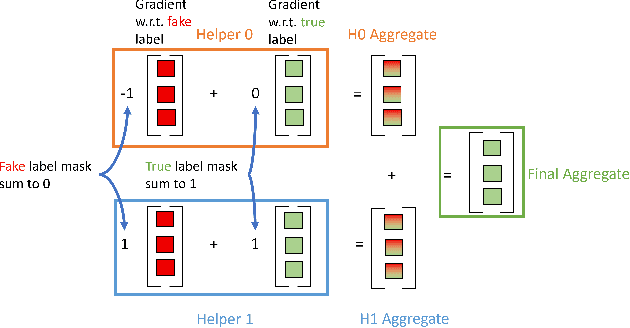
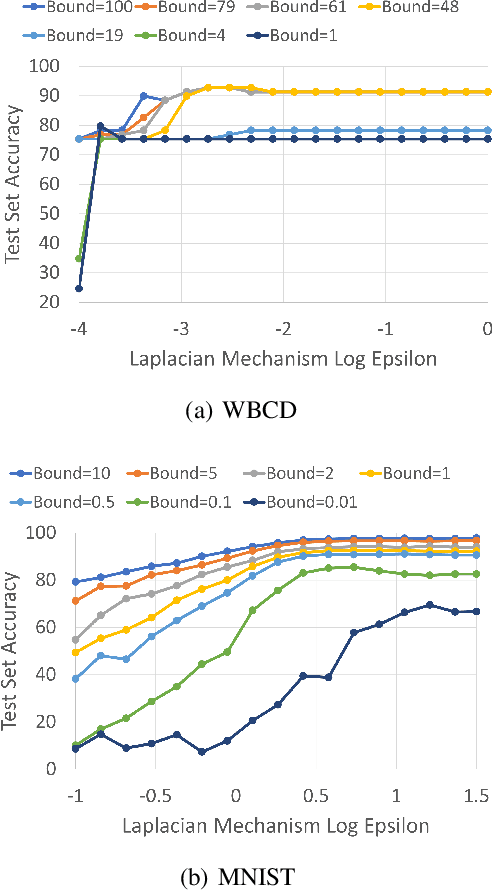
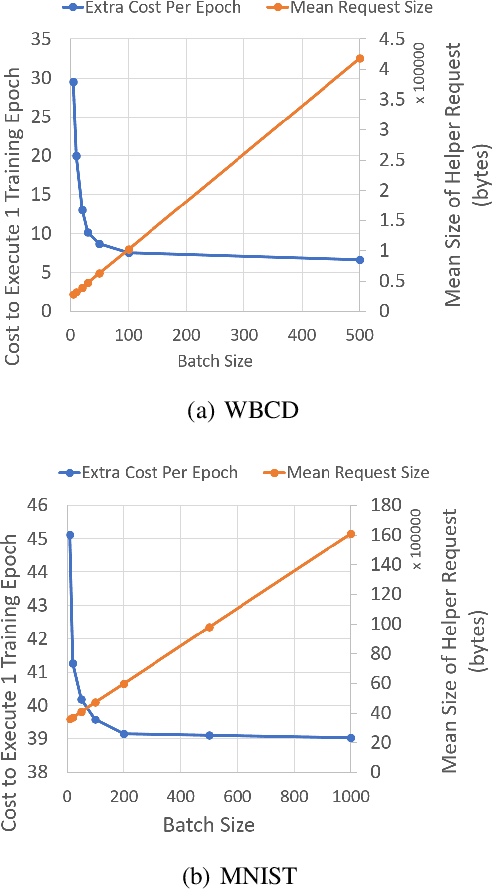
Today, many web advertising data flows involve passive cross-site tracking of users. Enabling such a mechanism through the usage of third party tracking cookies (3PC) exposes sensitive user data to a large number of parties, with little oversight on how that data can be used. Thus, most browsers are moving towards removal of 3PC in subsequent browser iterations. In order to substantially improve end-user privacy while allowing sites to continue to sustain their business through ad funding, new privacy-preserving primitives need to be introduced. In this paper, we discuss a new proposal, called Masked LARk, for aggregation of user engagement measurement and model training that prevents cross-site tracking, while remaining (a) flexible, for engineering development and maintenance, (b) secure, in the sense that cross-site tracking and tracing are blocked and (c) open for continued model development and training, allowing advertisers to serve relevant ads to interested users. We introduce a secure multi-party compute (MPC) protocol that utilizes "helper" parties to train models, so that once data leaves the browser, no downstream system can individually construct a complete picture of the user activity. For training, our key innovation is through the usage of masking, or the obfuscation of the true labels, while still allowing a gradient to be accurately computed in aggregate over a batch of data. Our protocol only utilizes light cryptography, at such a level that an interested yet inexperienced reader can understand the core algorithm. We develop helper endpoints that implement this system, and give example usage of training in PyTorch.
Unbiased Estimation of the Value of an Optimized Policy
Jun 07, 2018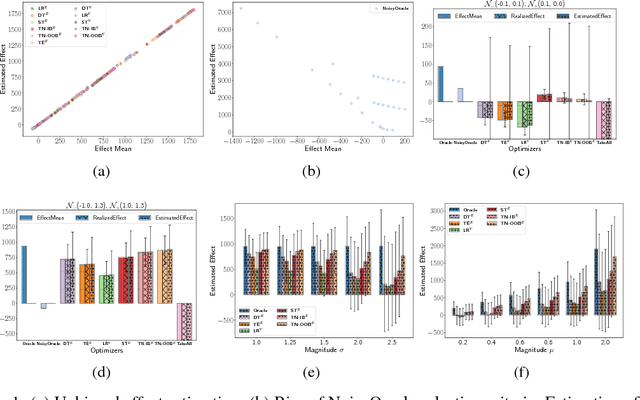
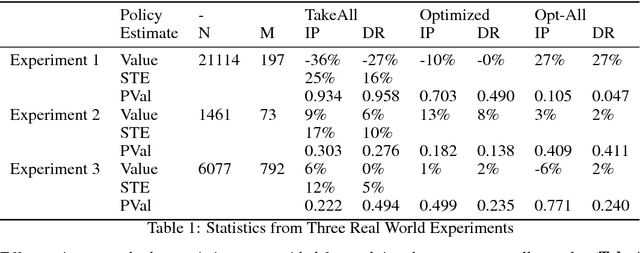
Randomized trials, also known as A/B tests, are used to select between two policies: a control and a treatment. Given a corresponding set of features, we can ideally learn an optimized policy P that maps the A/B test data features to action space and optimizes reward. However, although A/B testing provides an unbiased estimator for the value of deploying B (i.e., switching from policy A to B), direct application of those samples to learn the the optimized policy P generally does not provide an unbiased estimator of the value of P as the samples were observed when constructing P. In situations where the cost and risks associated of deploying a policy are high, such an unbiased estimator is highly desirable. We present a procedure for learning optimized policies and getting unbiased estimates for the value of deploying them. We wrap any policy learning procedure with a bagging process and obtain out-of-bag policy inclusion decisions for each sample. We then prove that inverse-propensity-weighting effect estimator is unbiased when applied to the optimized subset. Likewise, we apply the same idea to obtain out-of-bag unbiased per-sample value estimate of the measurement that is independent of the randomized treatment, and use these estimates to build an unbiased doubly-robust effect estimator. Lastly, we empirically shown that even when the average treatment effect is negative we can find a positive optimized policy.