 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCost-Minimized Label-Flipping Poisoning Attack to LLM Alignment
Nov 12, 2025Large language models (LLMs) are increasingly deployed in real-world systems, making it critical to understand their vulnerabilities. While data poisoning attacks during RLHF/DPO alignment have been studied empirically, their theoretical foundations remain unclear. We investigate the minimum-cost poisoning attack required to steer an LLM's policy toward an attacker's target by flipping preference labels during RLHF/DPO, without altering the compared outputs. We formulate this as a convex optimization problem with linear constraints, deriving lower and upper bounds on the minimum attack cost. As a byproduct of this theoretical analysis, we show that any existing label-flipping attack can be post-processed via our proposed method to reduce the number of label flips required while preserving the intended poisoning effect. Empirical results demonstrate that this cost-minimization post-processing can significantly reduce poisoning costs over baselines, particularly when the reward model's feature dimension is small relative to the dataset size. These findings highlight fundamental vulnerabilities in RLHF/DPO pipelines and provide tools to evaluate their robustness against low-cost poisoning attacks.
A Provable Approach for End-to-End Safe Reinforcement Learning
May 28, 2025A longstanding goal in safe reinforcement learning (RL) is a method to ensure the safety of a policy throughout the entire process, from learning to operation. However, existing safe RL paradigms inherently struggle to achieve this objective. We propose a method, called Provably Lifetime Safe RL (PLS), that integrates offline safe RL with safe policy deployment to address this challenge. Our proposed method learns a policy offline using return-conditioned supervised learning and then deploys the resulting policy while cautiously optimizing a limited set of parameters, known as target returns, using Gaussian processes (GPs). Theoretically, we justify the use of GPs by analyzing the mathematical relationship between target and actual returns. We then prove that PLS finds near-optimal target returns while guaranteeing safety with high probability. Empirically, we demonstrate that PLS outperforms baselines both in safety and reward performance, thereby achieving the longstanding goal to obtain high rewards while ensuring the safety of a policy throughout the lifetime from learning to operation.
Feature selection based on cluster assumption in PU learning
Apr 17, 2025Feature selection is essential for efficient data mining and sometimes encounters the positive-unlabeled (PU) learning scenario, where only a few positive labels are available, while most data remains unlabeled. In certain real-world PU learning tasks, data subjected to adequate feature selection often form clusters with concentrated positive labels. Conventional feature selection methods that treat unlabeled data as negative may fail to capture the statistical characteristics of positive data in such scenarios, leading to suboptimal performance. To address this, we propose a novel feature selection method based on the cluster assumption in PU learning, called FSCPU. FSCPU formulates the feature selection problem as a binary optimization task, with an objective function explicitly designed to incorporate the cluster assumption in the PU learning setting. Experiments on synthetic datasets demonstrate the effectiveness of FSCPU across various data conditions. Moreover, comparisons with 10 conventional algorithms on three open datasets show that FSCPU achieves competitive performance in downstream classification tasks, even when the cluster assumption does not strictly hold.
Challenges of Interaction in Optimizing Mixed Categorical-Continuous Variables
Apr 01, 2025Optimization of mixed categorical-continuous variables is prevalent in real-world applications of black-box optimization. Recently, CatCMA has been proposed as a method for optimizing such variables and has demonstrated success in hyper-parameter optimization problems. However, it encounters challenges when optimizing categorical variables in the presence of interaction between continuous and categorical variables in the objective function. In this paper, we focus on optimizing mixed binary-continuous variables as a special case and identify two types of variable interactions that make the problem particularly challenging for CatCMA. To address these difficulties, we propose two algorithmic components: a warm-starting strategy and a hyper-representation technique. We analyze their theoretical impact on test problems exhibiting these interaction properties. Empirical results demonstrate that the proposed components effectively address the identified challenges, and CatCMA enhanced with these components, named ICatCMA, outperforms the original CatCMA.
Vulnerability Mitigation for Safety-Aligned Language Models via Debiasing
Feb 04, 2025Safety alignment is an essential research topic for real-world AI applications. Despite the multifaceted nature of safety and trustworthiness in AI, current safety alignment methods often focus on a comprehensive notion of safety. By carefully assessing models from the existing safety-alignment methods, we found that, while they generally improved overall safety performance, they failed to ensure safety in specific categories. Our study first identified the difficulty of eliminating such vulnerabilities without sacrificing the model's helpfulness. We observed that, while smaller KL penalty parameters, increased training iterations, and dataset cleansing can enhance safety, they do not necessarily improve the trade-off between safety and helpfulness. We discovered that safety alignment could even induce undesired effects and result in a model that prefers generating negative tokens leading to rejective responses, regardless of the input context. To address this, we introduced a learning-free method, Token-level Safety-Debiased Inference (TSDI), to estimate and correct this bias during the generation process using randomly constructed prompts. Our experiments demonstrated that our method could enhance the model's helpfulness while maintaining safety, thus improving the trade-off Pareto-front.
Probabilistic Prediction of Ship Maneuvering Motion using Ensemble Learning with Feedforward Neural Networks
Nov 30, 2024

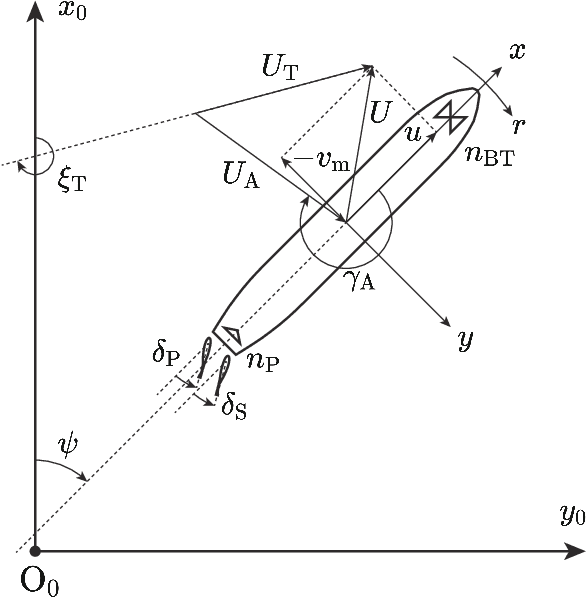

In the field of Maritime Autonomous Surface Ships (MASS), the accurate modeling of ship maneuvering motion for harbor maneuvers is a crucial technology. Non-parametric system identification (SI) methods, which do not require prior knowledge of the target ship, have the potential to produce accurate maneuvering models using observed data. However, the modeling accuracy significantly depends on the distribution of the available data. To address these issues, we propose a probabilistic prediction method of maneuvering motion that incorporates ensemble learning into a non-parametric SI using feedforward neural networks. This approach captures the epistemic uncertainty caused by insufficient or unevenly distributed data. In this paper, we show the prediction accuracy and uncertainty prediction results for various unknown scenarios, including port navigation, zigzag, turning, and random control maneuvers, assuming that only port navigation data is available. Furthermore, this paper demonstrates the utility of the proposed method as a maneuvering simulator for assessing heading-keeping PD control. As a result, it was confirmed that the proposed method can achieve high accuracy if training data with similar state distributions is provided, and that it can also predict high uncertainty for states that deviate from the training data distribution. In the performance evaluation of PD control, it was confirmed that considering worst-case scenarios reduces the possibility of overestimating performance compared to the true system. Finally, we show the results of applying the proposed method to full-scale ship data, demonstrating its applicability to full-scale ships.
Conceptual Design on the Field of View of Celestial Navigation Systems for Maritime Autonomous Surface Ships
Aug 28, 2024



In order to understand the appropriate field of view (FOV) size of celestial automatic navigation systems for surface ships, we investigate the variations of measurement accuracy of star position and probability of successful star identification with respect to FOV, focusing on the decreasing number of observable star magnitudes and the presence of physically covered stars in marine environments. The results revealed that, although a larger FOV reduces the measurement accuracy of star positions, it increases the number of observable objects and thus improves the probability of star identification using subgraph isomorphism-based methods. It was also found that, although at least four objects need to be observed for accurate identification, four objects may not be sufficient for wider FOVs. On the other hand, from the point of view of celestial navigation systems, a decrease in the measurement accuracy leads to a decrease in positioning accuracy. Therefore, it was found that maximizing the FOV is required for celestial automatic navigation systems as long as the desired positioning accuracy can be ensured. Furthermore, it was found that algorithms incorporating more than four observed celestial objects are required to achieve highly accurate star identification over a wider FOV.
Tail Bounds on the Runtime of Categorical Compact Genetic Algorithm
Jul 10, 2024



The majority of theoretical analyses of evolutionary algorithms in the discrete domain focus on binary optimization algorithms, even though black-box optimization on the categorical domain has a lot of practical applications. In this paper, we consider a probabilistic model-based algorithm using the family of categorical distributions as its underlying distribution and set the sample size as two. We term this specific algorithm the categorical compact genetic algorithm (ccGA). The ccGA can be considered as an extension of the compact genetic algorithm (cGA), which is an efficient binary optimization algorithm. We theoretically analyze the dependency of the number of possible categories $K$, the number of dimensions $D$, and the learning rate $\eta$ on the runtime. We investigate the tail bound of the runtime on two typical linear functions on the categorical domain: categorical OneMax (COM) and KVal. We derive that the runtimes on COM and KVal are $O(\sqrt{D} \ln (DK) / \eta)$ and $\Theta(D \ln K/ \eta)$ with high probability, respectively. Our analysis is a generalization for that of the cGA on the binary domain.
CMA-ES with Learning Rate Adaptation
Jan 29, 2024



The covariance matrix adaptation evolution strategy (CMA-ES) is one of the most successful methods for solving continuous black-box optimization problems. A practically useful aspect of the CMA-ES is that it can be used without hyperparameter tuning. However, the hyperparameter settings still have a considerable impact on performance, especially for difficult tasks, such as solving multimodal or noisy problems. This study comprehensively explores the impact of learning rate on the CMA-ES performance and demonstrates the necessity of a small learning rate by considering ordinary differential equations. Thereafter, it discusses the setting of an ideal learning rate. Based on these discussions, we develop a novel learning rate adaptation mechanism for the CMA-ES that maintains a constant signal-to-noise ratio. Additionally, we investigate the behavior of the CMA-ES with the proposed learning rate adaptation mechanism through numerical experiments, and compare the results with those obtained for the CMA-ES with a fixed learning rate and with population size adaptation. The results show that the CMA-ES with the proposed learning rate adaptation works well for multimodal and/or noisy problems without extremely expensive learning rate tuning.
Theoretical Analysis of Explicit Averaging and Novel Sign Averaging in Comparison-Based Search
Jan 25, 2024In black-box optimization, noise in the objective function is inevitable. Noise disrupts the ranking of candidate solutions in comparison-based optimization, possibly deteriorating the search performance compared with a noiseless scenario. Explicit averaging takes the sample average of noisy objective function values and is widely used as a simple and versatile noise-handling technique. Although it is suitable for various applications, it is ineffective if the mean is not finite. We theoretically reveal that explicit averaging has a negative effect on the estimation of ground-truth rankings when assuming stably distributed noise without a finite mean. Alternatively, sign averaging is proposed as a simple but robust noise-handling technique. We theoretically prove that the sign averaging estimates the order of the medians of the noisy objective function values of a pair of points with arbitrarily high probability as the number of samples increases. Its advantages over explicit averaging and its robustness are also confirmed through numerical experiments.