 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVerbosity Bias in Preference Labeling by Large Language Models
Oct 16, 2023



In recent years, Large Language Models (LLMs) have witnessed a remarkable surge in prevalence, altering the landscape of natural language processing and machine learning. One key factor in improving the performance of LLMs is alignment with humans achieved with Reinforcement Learning from Human Feedback (RLHF), as for many LLMs such as GPT-4, Bard, etc. In addition, recent studies are investigating the replacement of human feedback with feedback from other LLMs named Reinforcement Learning from AI Feedback (RLAIF). We examine the biases that come along with evaluating LLMs with other LLMs and take a closer look into verbosity bias -- a bias where LLMs sometimes prefer more verbose answers even if they have similar qualities. We see that in our problem setting, GPT-4 prefers longer answers more than humans. We also propose a metric to measure this bias.
Statistically Significant Concept-based Explanation of Image Classifiers via Model Knockoffs
May 31, 2023



A concept-based classifier can explain the decision process of a deep learning model by human-understandable concepts in image classification problems. However, sometimes concept-based explanations may cause false positives, which misregards unrelated concepts as important for the prediction task. Our goal is to find the statistically significant concept for classification to prevent misinterpretation. In this study, we propose a method using a deep learning model to learn the image concept and then using the Knockoff samples to select the important concepts for prediction by controlling the False Discovery Rate (FDR) under a certain value. We evaluate the proposed method in our synthetic and real data experiments. Also, it shows that our method can control the FDR properly while selecting highly interpretable concepts to improve the trustworthiness of the model.
CMA-ES with Learning Rate Adaptation: Can CMA-ES with Default Population Size Solve Multimodal and Noisy Problems?
Apr 16, 2023The covariance matrix adaptation evolution strategy (CMA-ES) is one of the most successful methods for solving black-box continuous optimization problems. One practically useful aspect of the CMA-ES is that it can be used without hyperparameter tuning. However, the hyperparameter settings still have a considerable impact, especially for difficult tasks such as solving multimodal or noisy problems. In this study, we investigate whether the CMA-ES with default population size can solve multimodal and noisy problems. To perform this investigation, we develop a novel learning rate adaptation mechanism for the CMA-ES, such that the learning rate is adapted so as to maintain a constant signal-to-noise ratio. We investigate the behavior of the CMA-ES with the proposed learning rate adaptation mechanism through numerical experiments, and compare the results with those obtained for the CMA-ES with a fixed learning rate. The results demonstrate that, when the proposed learning rate adaptation is used, the CMA-ES with default population size works well on multimodal and/or noisy problems, without the need for extremely expensive learning rate tuning.
Covariance Matrix Adaptation Evolutionary Strategy with Worst-Case Ranking Approximation for Min--Max Optimization and its Application to Berthing Control Tasks
Mar 28, 2023



In this study, we consider a continuous min--max optimization problem $\min_{x \in \mathbb{X} \max_{y \in \mathbb{Y}}}f(x,y)$ whose objective function is a black-box. We propose a novel approach to minimize the worst-case objective function $F(x) = \max_{y} f(x,y)$ directly using a covariance matrix adaptation evolution strategy (CMA-ES) in which the rankings of solution candidates are approximated by our proposed worst-case ranking approximation (WRA) mechanism. We develop two variants of WRA combined with CMA-ES and approximate gradient ascent as numerical solvers for the inner maximization problem. Numerical experiments show that our proposed approach outperforms several existing approaches when the objective function is a smooth strongly convex--concave function and the interaction between $x$ and $y$ is strong. We investigate the advantages of the proposed approach for problems where the objective function is not limited to smooth strongly convex--concave functions. The effectiveness of the proposed approach is demonstrated in the robust berthing control problem with uncertainty.ngly convex--concave functions. The effectiveness of the proposed approach is demonstrated in the robust berthing control problem with uncertainty.
Few-Shot Image-to-Semantics Translation for Policy Transfer in Reinforcement Learning
Jan 31, 2023We investigate policy transfer using image-to-semantics translation to mitigate learning difficulties in vision-based robotics control agents. This problem assumes two environments: a simulator environment with semantics, that is, low-dimensional and essential information, as the state space, and a real-world environment with images as the state space. By learning mapping from images to semantics, we can transfer a policy, pre-trained in the simulator, to the real world, thereby eliminating real-world on-policy agent interactions to learn, which are costly and risky. In addition, using image-to-semantics mapping is advantageous in terms of the computational efficiency to train the policy and the interpretability of the obtained policy over other types of sim-to-real transfer strategies. To tackle the main difficulty in learning image-to-semantics mapping, namely the human annotation cost for producing a training dataset, we propose two techniques: pair augmentation with the transition function in the simulator environment and active learning. We observed a reduction in the annotation cost without a decline in the performance of the transfer, and the proposed approach outperformed the existing approach without annotation.
Collision probability reduction method for tracking control in automatic docking / berthing using reinforcement learning
Dec 14, 2022Automation of berthing maneuvers in shipping is a pressing issue as the berthing maneuver is one of the most stressful tasks seafarers undertake. Berthing control problems are often tackled via tracking a predefined trajectory or path. Maintaining a tracking error of zero under an uncertain environment is impossible; the tracking controller is nonetheless required to bring vessels close to desired berths. The tracking controller must prioritize the avoidance of tracking errors that may cause collisions with obstacles. This paper proposes a training method based on reinforcement learning for a trajectory tracking controller that reduces the probability of collisions with static obstacles. Via numerical simulations, we show that the proposed method reduces the probability of collisions during berthing maneuvers. Furthermore, this paper shows the tracking performance in a model experiment.
Adaptive Scenario Subset Selection for Worst-Case Optimization and its Application to Well Placement Optimization
Nov 29, 2022



In this study, we consider simulation-based worst-case optimization problems with continuous design variables and a finite scenario set. To reduce the number of simulations required and increase the number of restarts for better local optimum solutions, we propose a new approach referred to as adaptive scenario subset selection (AS3). The proposed approach subsamples a scenario subset as a support to construct the worst-case function in a given neighborhood, and we introduce such a scenario subset. Moreover, we develop a new optimization algorithm by combining AS3 and the covariance matrix adaptation evolution strategy (CMA-ES), denoted AS3-CMA-ES. At each algorithmic iteration, a subset of support scenarios is selected, and CMA-ES attempts to optimize the worst-case objective computed only through a subset of the scenarios. The proposed algorithm reduces the number of simulations required by executing simulations on only a scenario subset, rather than on all scenarios. In numerical experiments, we verified that AS3-CMA-ES is more efficient in terms of the number of simulations than the brute-force approach and a surrogate-assisted approach lq-CMA-ES when the ratio of the number of support scenarios to the total number of scenarios is relatively small. In addition, the usefulness of AS3-CMA-ES was evaluated for well placement optimization for carbon dioxide capture and storage (CCS). In comparison with the brute-force approach and lq-CMA-ES, AS3-CMA-ES was able to find better solutions because of more frequent restarts.
Max-Min Off-Policy Actor-Critic Method Focusing on Worst-Case Robustness to Model Misspecification
Nov 07, 2022In the field of reinforcement learning, because of the high cost and risk of policy training in the real world, policies are trained in a simulation environment and transferred to the corresponding real-world environment. However, the simulation environment does not perfectly mimic the real-world environment, lead to model misspecification. Multiple studies report significant deterioration of policy performance in a real-world environment. In this study, we focus on scenarios involving a simulation environment with uncertainty parameters and the set of their possible values, called the uncertainty parameter set. The aim is to optimize the worst-case performance on the uncertainty parameter set to guarantee the performance in the corresponding real-world environment. To obtain a policy for the optimization, we propose an off-policy actor-critic approach called the Max-Min Twin Delayed Deep Deterministic Policy Gradient algorithm (M2TD3), which solves a max-min optimization problem using a simultaneous gradient ascent descent approach. Experiments in multi-joint dynamics with contact (MuJoCo) environments show that the proposed method exhibited a worst-case performance superior to several baseline approaches.
Convergence rate of the -evolution strategy on locally strongly convex functions with lipschitz continuous gradient and their monotonic transformations
Sep 27, 2022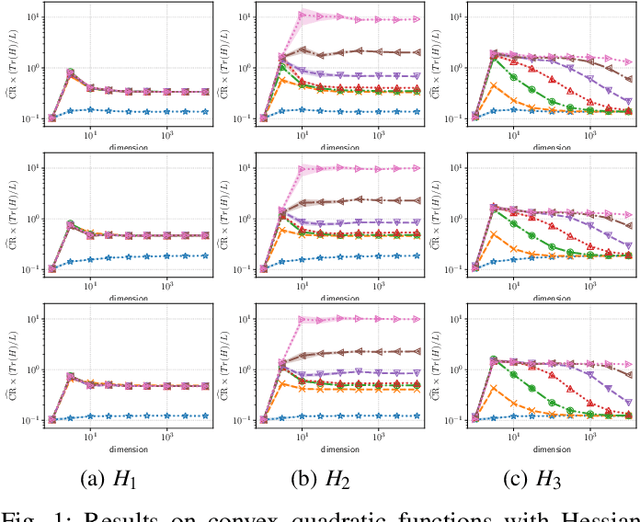
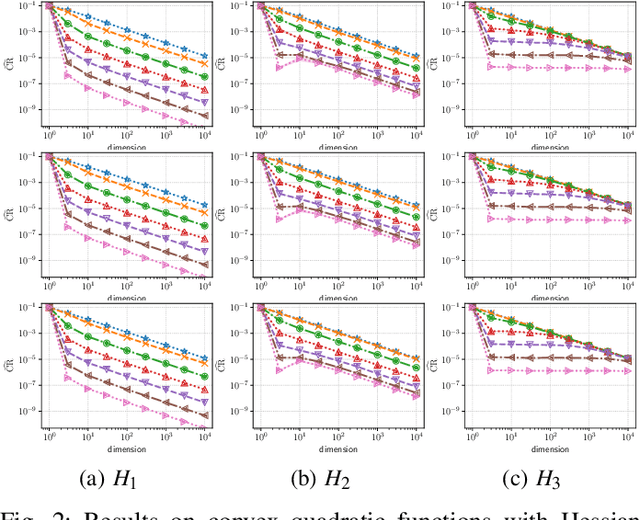
Evolution strategy (ES) is one of promising classes of algorithms for black-box continuous optimization. Despite its broad successes in applications, theoretical analysis on the speed of its convergence is limited on convex quadratic functions and their monotonic transformation. In this study, an upper bound and a lower bound of the rate of linear convergence of the (1+1)-ES on locally $L$-strongly convex functions with $U$-Lipschitz continuous gradient are derived as $\exp\left(-\Omega_{d\to\infty}\left(\frac{L}{d\cdot U}\right)\right)$ and $\exp\left(-\frac1d\right)$, respectively. Notably, any prior knowledge on the mathematical properties of the objective function such as Lipschitz constant is not given to the algorithm, whereas the existing analyses of derivative-free optimization algorithms require them.
CAMRI Loss: Improving Recall of a Specific Class without Sacrificing Accuracy
Sep 22, 2022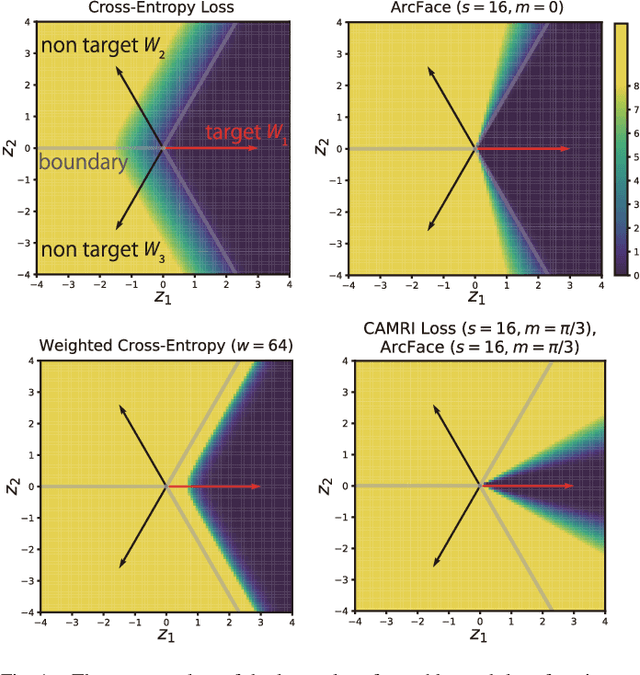
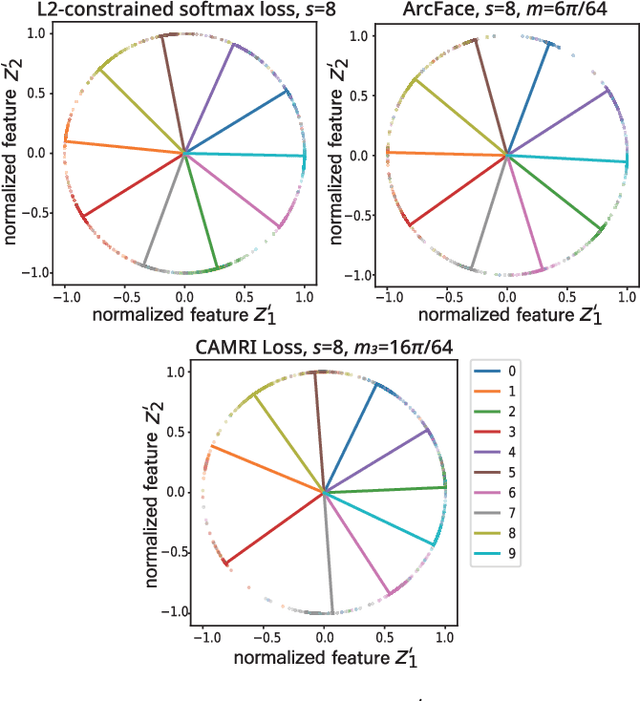
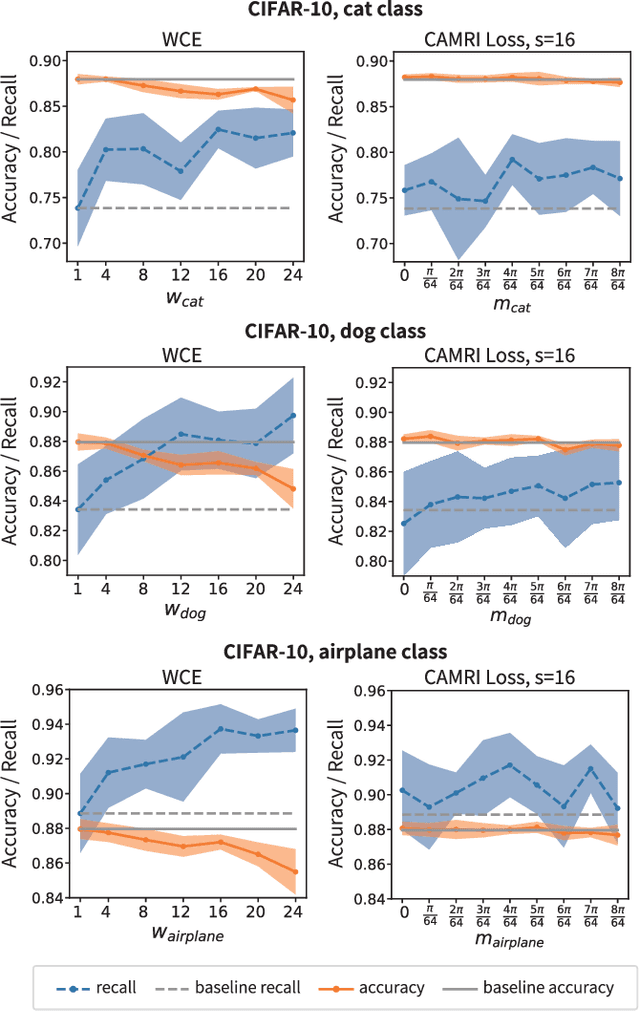
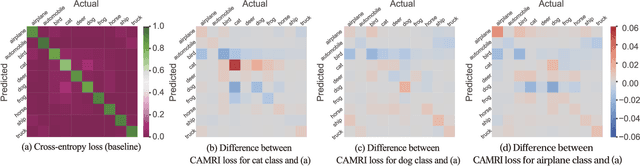
In real-world applications of multi-class classification models, misclassification in an important class (e.g., stop sign) can be significantly more harmful than in other classes (e.g., speed limit). In this paper, we propose a loss function that can improve the recall of an important class while maintaining the same level of accuracy as the case using cross-entropy loss. For our purpose, we need to make the separation of the important class better than the other classes. However, existing methods that give a class-sensitive penalty for cross-entropy loss do not improve the separation. On the other hand, the method that gives a margin to the angle between the feature vectors and the weight vectors of the last fully connected layer corresponding to each feature can improve the separation. Therefore, we propose a loss function that can improve the separation of the important class by setting the margin only for the important class, called Class-sensitive Additive Angular Margin Loss (CAMRI Loss). CAMRI loss is expected to reduce the variance of angles between features and weights of the important class relative to other classes due to the margin around the important class in the feature space by adding a penalty to the angle. In addition, concentrating the penalty only on the important classes hardly sacrifices the separation of the other classes. Experiments on CIFAR-10, GTSRB, and AwA2 showed that the proposed method could improve up to 9% recall improvement on cross-entropy loss without sacrificing accuracy.