 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncover the Ground-Truth Relations in Distant Supervision: A Neural Expectation-Maximization Framework
Sep 12, 2019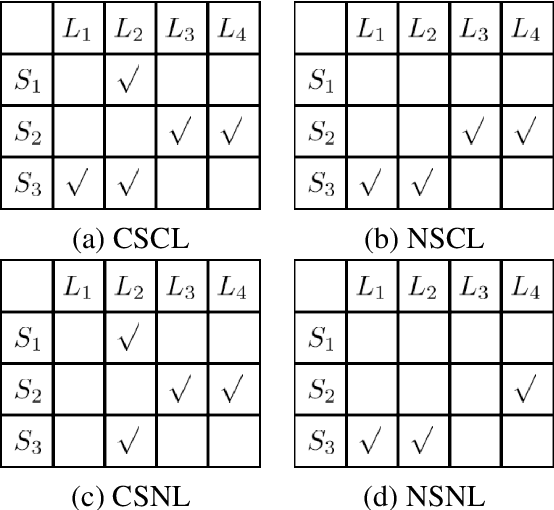

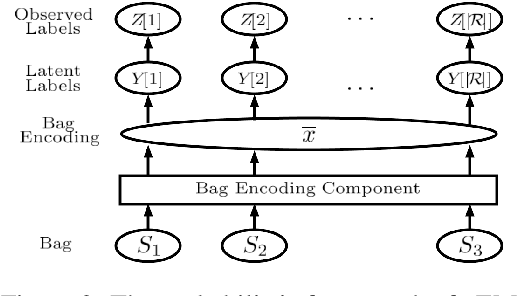
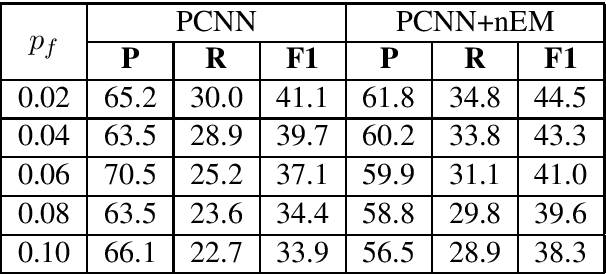
Distant supervision for relation extraction enables one to effectively acquire structured relations out of very large text corpora with less human efforts. Nevertheless, most of the prior-art models for such tasks assume that the given text can be noisy, but their corresponding labels are clean. Such unrealistic assumption is contradictory with the fact that the given labels are often noisy as well, thus leading to significant performance degradation of those models on real-world data. To cope with this challenge, we propose a novel label-denoising framework that combines neural network with probabilistic modelling, which naturally takes into account the noisy labels during learning. We empirically demonstrate that our approach significantly improves the current art in uncovering the ground-truth relation labels.
MixUp as Directional Adversarial Training
Jun 17, 2019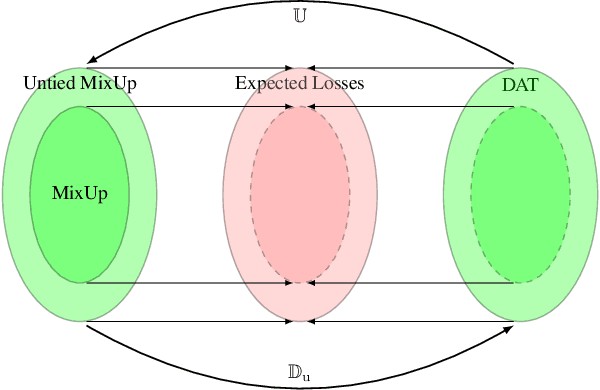
In this work, we explain the working mechanism of MixUp in terms of adversarial training. We introduce a new class of adversarial training schemes, which we refer to as directional adversarial training, or DAT. In a nutshell, a DAT scheme perturbs a training example in the direction of another example but keeps its original label as the training target. We prove that MixUp is equivalent to a special subclass of DAT, in that it has the same expected loss function and corresponds to the same optimization problem asymptotically. This understanding not only serves to explain the effectiveness of MixUp, but also reveals a more general family of MixUp schemes, which we call Untied MixUp. We prove that the family of Untied MixUp schemes is equivalent to the entire class of DAT schemes. We establish empirically the existence of Untied Mixup schemes which improve upon MixUp.
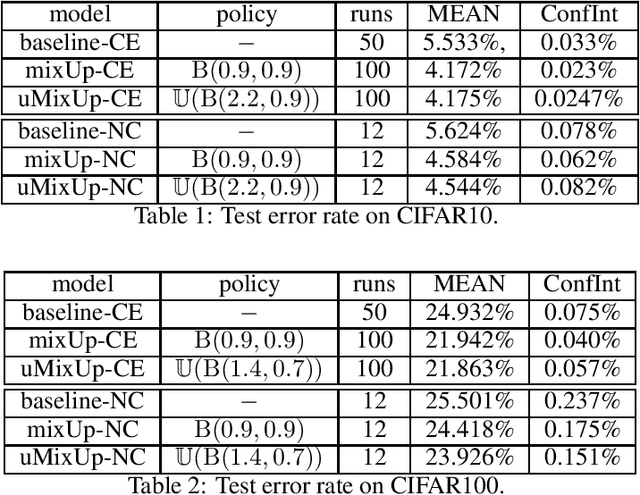
Augmenting Data with Mixup for Sentence Classification: An Empirical Study
May 22, 2019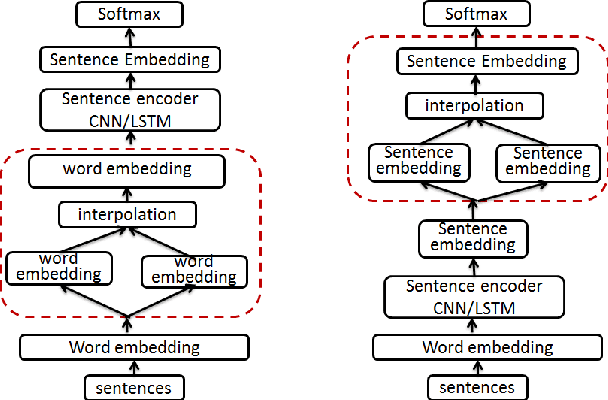
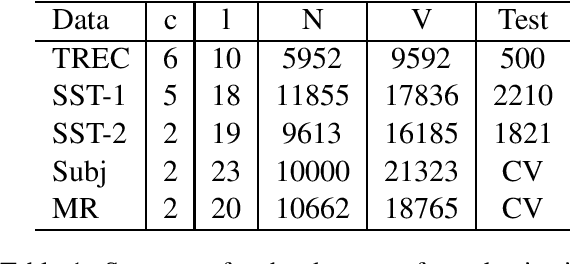

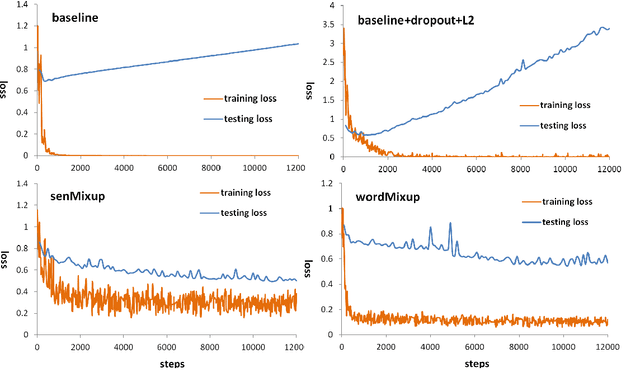
Mixup, a recent proposed data augmentation method through linearly interpolating inputs and modeling targets of random samples, has demonstrated its capability of significantly improving the predictive accuracy of the state-of-the-art networks for image classification. However, how this technique can be applied to and what is its effectiveness on natural language processing (NLP) tasks have not been investigated. In this paper, we propose two strategies for the adaption of Mixup on sentence classification: one performs interpolation on word embeddings and another on sentence embeddings. We conduct experiments to evaluate our methods using several benchmark datasets. Our studies show that such interpolation strategies serve as an effective, domain independent data augmentation approach for sentence classification, and can result in significant accuracy improvement for both CNN and LSTM models.
Understanding Feature Selection and Feature Memorization in Recurrent Neural Networks
Mar 03, 2019
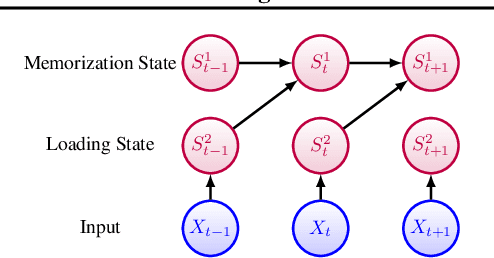

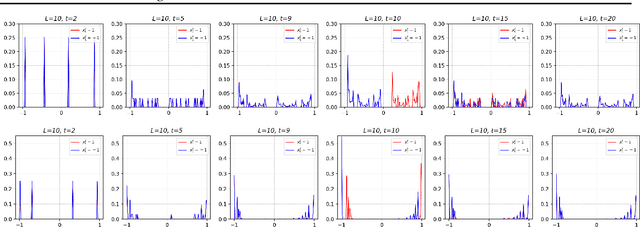
In this paper, we propose a test, called Flagged-1-Bit (F1B) test, to study the intrinsic capability of recurrent neural networks in sequence learning. Four different recurrent network models are studied both analytically and experimentally using this test. Our results suggest that in general there exists a conflict between feature selection and feature memorization in sequence learning. Such a conflict can be resolved either using a gating mechanism as in LSTM, or by increasing the state dimension as in Vanilla RNN. Gated models resolve this conflict by adaptively adjusting their state-update equations, whereas Vanilla RNN resolves this conflict by assigning different dimensions different tasks. Insights into feature selection and memorization in recurrent networks are given.
MixUp as Locally Linear Out-Of-Manifold Regularization
Oct 14, 2018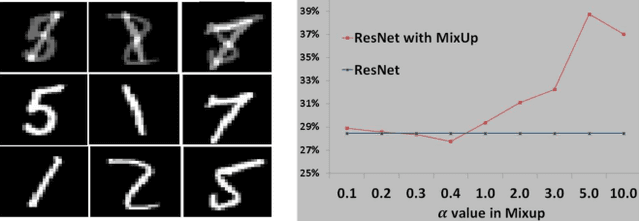
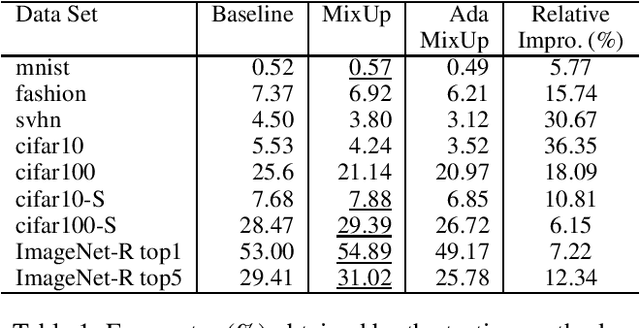
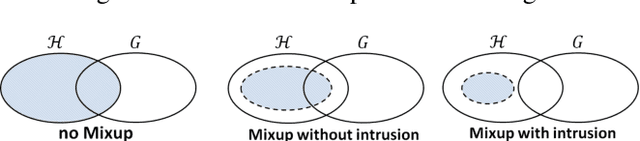
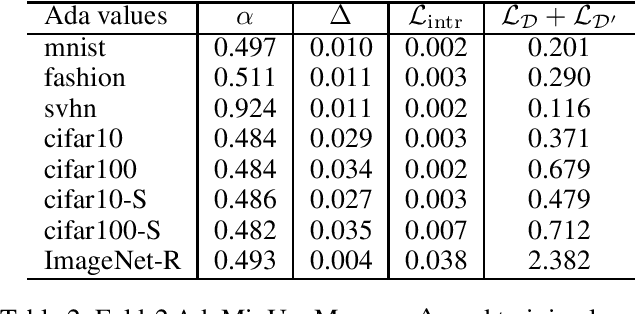
MixUp, a data augmentation approach through mixing random samples, has been shown to be able to significantly improve the predictive accuracy of the current art of deep neural networks. The power of MixUp, however, is mostly established empirically and its working and effectiveness have not been explained in any depth. In this paper, we develop a theoretical understanding for MixUp as a form of out-of-manifold regularization, which constrains the model on the input space beyond the data manifold. This analytical study also enables us to identify MixUp's limitation caused by manifold intrusion, where synthetic samples collide with real examples of the manifold. Such intrusion gives rise to over regularization and thereby under-fitting. To address this issue, we further propose a novel regularizer, where mixing policies are adaptively learned from the data and a manifold intrusion loss is embraced as to avoid collision with the data manifold. We empirically show, using several benchmark datasets, our regularizer's effectiveness in terms of over regularization avoiding and accuracy improvement upon current art of deep classification models and MixUp.
Inferring Multiplex Diffusion Network via Multivariate Marked Hawkes Process
Aug 24, 2018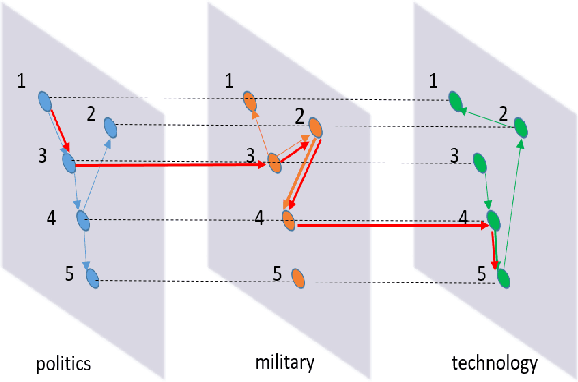

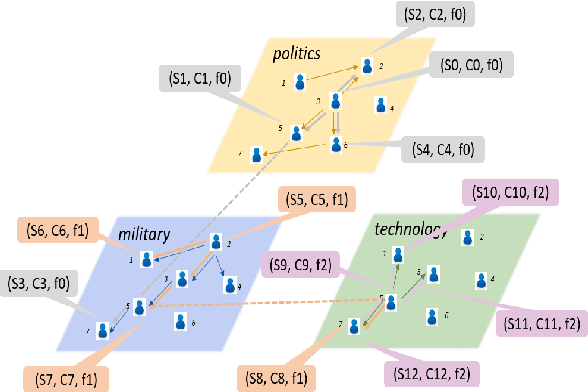
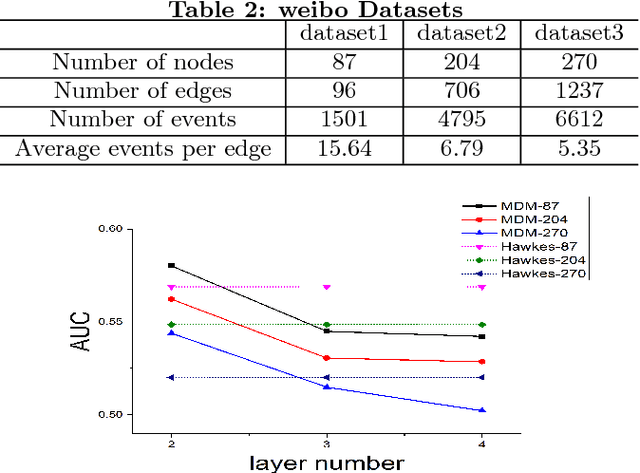
Understanding the diffusion in social network is an important task. However, this task is challenging since (1) the network structure is usually hidden with only observations of events like "post" or "repost" associated with each node, and (2) the interactions between nodes encompass multiple distinct patterns which in turn affect the diffusion patterns. For instance, social interactions seldom develop on a single channel, and multiple relationships can bind pairs of people due to their various common interests. Most previous work considers only one of these two challenges which is apparently unrealistic. In this paper, we study the problem of \emph{inferring multiplex network} in social networks. We propose the Multiplex Diffusion Model (MDM) which incorporates the multivariate marked Hawkes process and topic model to infer the multiplex structure of social network. A MCMC based algorithm is developed to infer the latent multiplex structure and to estimate the node-related parameters. We evaluate our model based on both synthetic and real-world datasets. The results show that our model is more effective in terms of uncovering the multiplex network structure.
Aggregated Learning: A Vector Quantization Approach to Learning with Neural Networks
Aug 15, 2018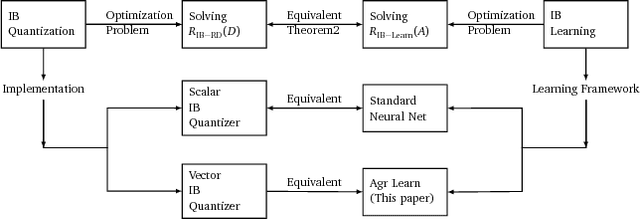
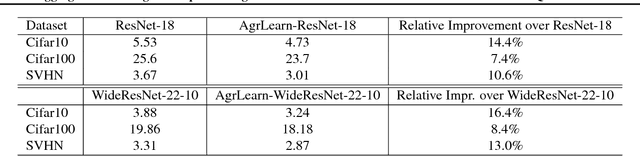
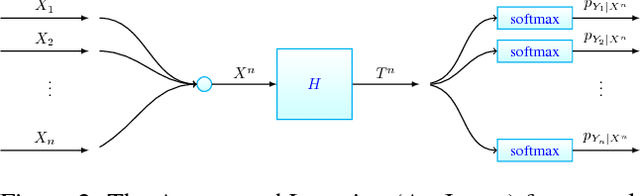

We establish an equivalence between information bottleneck (IB) learning and an unconventional quantization problem, `IB quantization'. Under this equivalence, standard neural network models correspond to scalar IB quantizers. We prove a coding theorem for IB quantization, which implies that scalar IB quantizers are in general inferior to vector IB quantizers. This inspires us to develop a learning framework for neural networks, AgrLearn, that corresponds to vector IB quantizers. We experimentally verify that AgrLearn applied to some deep network models of current art improves upon them, while requiring less training data. With a heuristic smoothing, AgrLearn further improves its performance, resulting in new state of the art in image classification on Cifar10.
Prototypical Recurrent Unit
Feb 09, 2018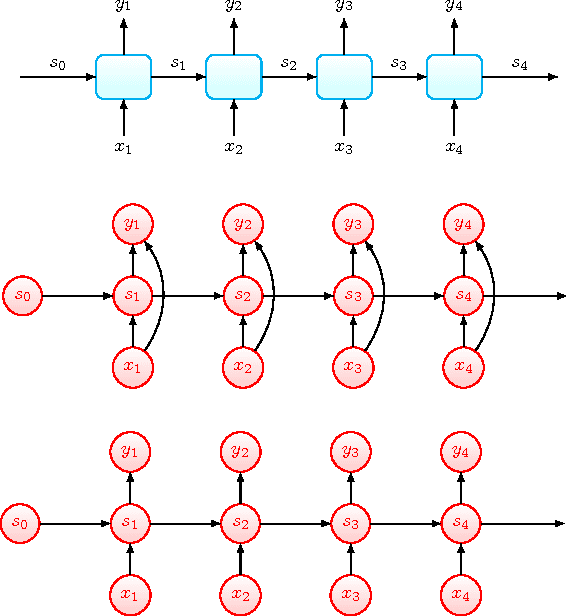
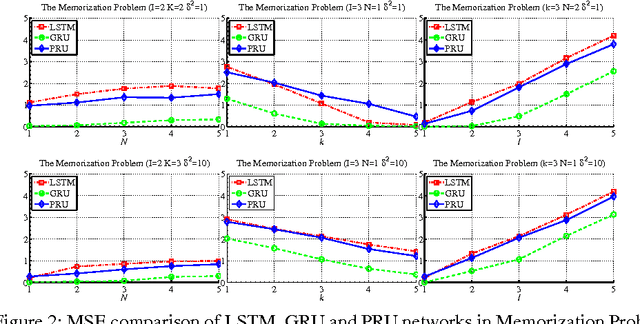
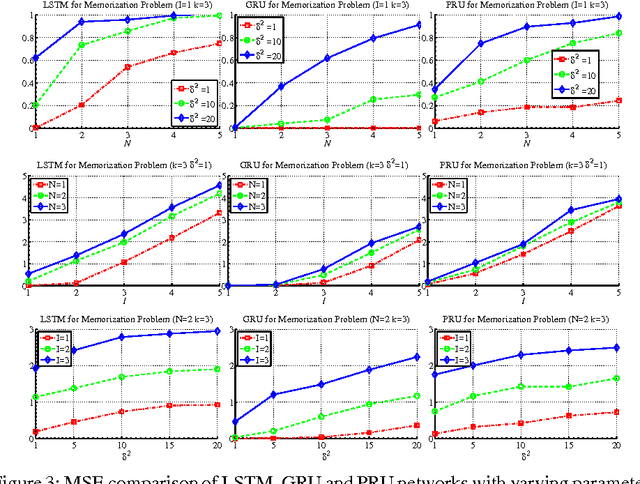
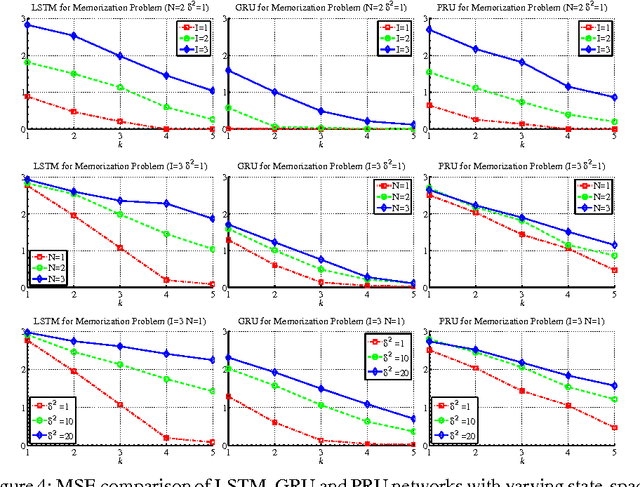
Despite the great successes of deep learning, the effectiveness of deep neural networks has not been understood at any theoretical depth. This work is motivated by the thrust of developing a deeper understanding of recurrent neural networks, particularly LSTM/GRU-like networks. As the highly complex structure of the recurrent unit in LSTM and GRU networks makes them difficult to analyze, our methodology in this research theme is to construct an alternative recurrent unit that is as simple as possible and yet also captures the key components of LSTM/GRU recurrent units. Such a unit can then be used for the study of recurrent networks and its structural simplicity may allow easier analysis. Towards that goal, we take a system-theoretic perspective to design a new recurrent unit, which we call the prototypical recurrent unit (PRU). Not only having minimal complexity, PRU is demonstrated experimentally to have comparable performance to GRU and LSTM unit. This establishes PRU networks as a prototype for future study of LSTM/GRU-like recurrent networks. This paper also studies the memorization abilities of LSTM, GRU and PRU networks, motivated by the folk belief that such networks possess long-term memory. For this purpose, we design a simple and controllable task, called ``memorization problem'', where the networks are trained to memorize certain targeted information. We show that the memorization performance of all three networks depends on the amount of targeted information, the amount of ``interfering" information, and the state space dimension of the recurrent unit. Experiments are also performed for another controllable task, the adding problem, and similar conclusions are obtained.
On the representation and embedding of knowledge bases beyond binary relations
Apr 28, 2016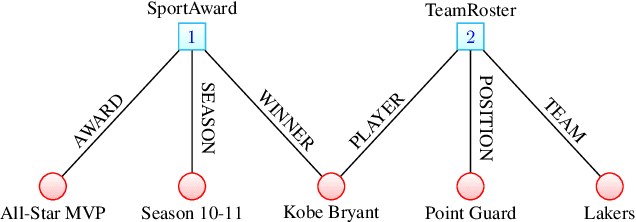

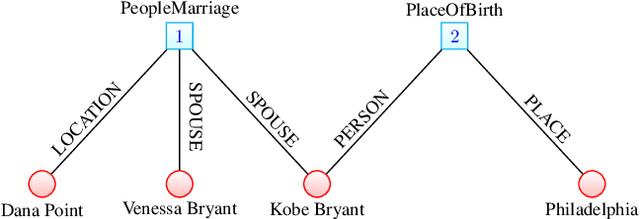
The models developed to date for knowledge base embedding are all based on the assumption that the relations contained in knowledge bases are binary. For the training and testing of these embedding models, multi-fold (or n-ary) relational data are converted to triples (e.g., in FB15K dataset) and interpreted as instances of binary relations. This paper presents a canonical representation of knowledge bases containing multi-fold relations. We show that the existing embedding models on the popular FB15K datasets correspond to a sub-optimal modelling framework, resulting in a loss of structural information. We advocate a novel modelling framework, which models multi-fold relations directly using this canonical representation. Using this framework, the existing TransH model is generalized to a new model, m-TransH. We demonstrate experimentally that m-TransH outperforms TransH by a large margin, thereby establishing a new state of the art.
Convolutional Factor Graphs as Probabilistic Models
Jul 11, 2012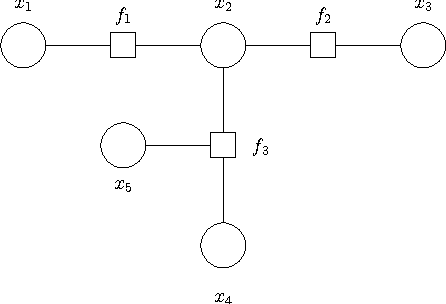
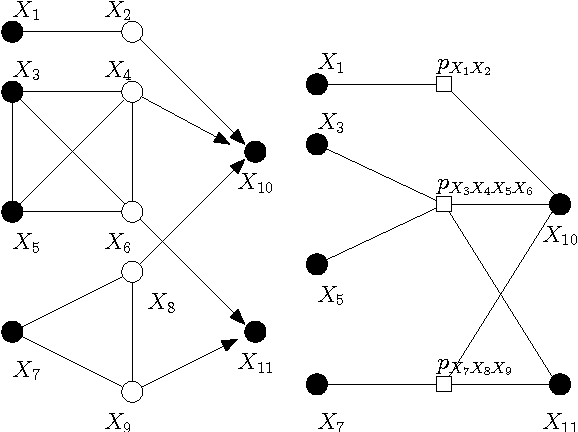
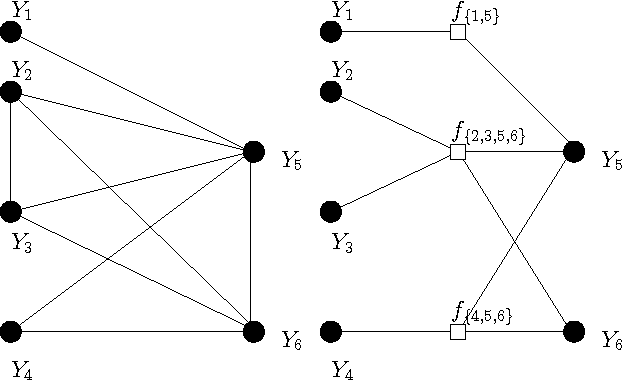
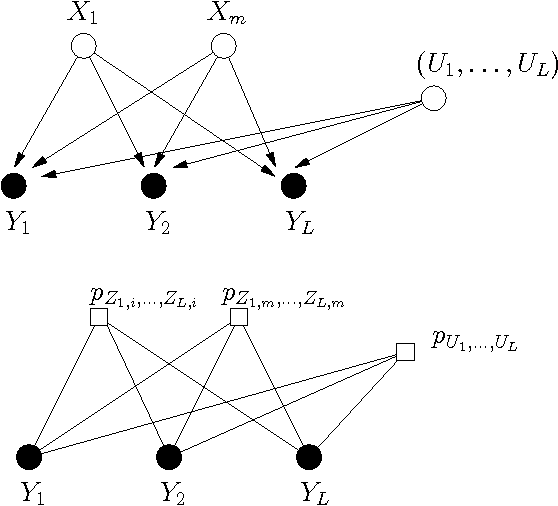
Based on a recent development in the area of error control coding, we introduce the notion of convolutional factor graphs (CFGs) as a new class of probabilistic graphical models. In this context, the conventional factor graphs are referred to as multiplicative factor graphs (MFGs). This paper shows that CFGs are natural models for probability functions when summation of independent latent random variables is involved. In particular, CFGs capture a large class of linear models, where the linearity is in the sense that the observed variables are obtained as a linear ransformation of the latent variables taking arbitrary distributions. We use Gaussian models and independent factor models as examples to emonstrate the use of CFGs. The requirement of a linear transformation between latent variables (with certain independence restriction) and the bserved variables, to an extent, limits the modelling flexibility of CFGs. This structural restriction however provides a powerful analytic tool to the framework of CFGs; that is, upon taking the Fourier transform of the function represented by the CFG, the resulting function is represented by a FG with identical structure. This Fourier transform duality allows inference problems on a CFG to be solved on the corresponding dual MFG.