 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrecise Affordance Annotation for Egocentric Action Video Datasets
Jun 11, 2022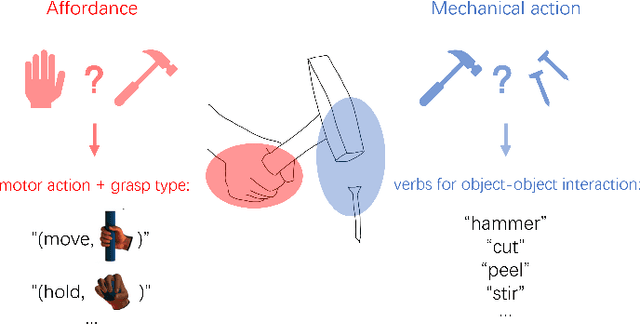


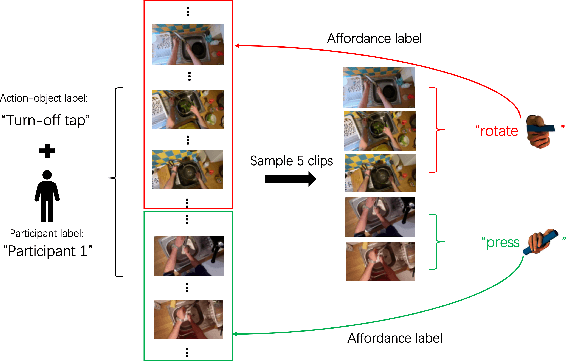
Object affordance is an important concept in human-object interaction, providing information on action possibilities based on human motor capacity and objects' physical property thus benefiting tasks such as action anticipation and robot imitation learning. However, existing datasets often: 1) mix up affordance with object functionality; 2) confuse affordance with goal-related action; and 3) ignore human motor capacity. This paper proposes an efficient annotation scheme to address these issues by combining goal-irrelevant motor actions and grasp types as affordance labels and introducing the concept of mechanical action to represent the action possibilities between two objects. We provide new annotations by applying this scheme to the EPIC-KITCHENS dataset and test our annotation with tasks such as affordance recognition. We qualitatively verify that models trained with our annotation can distinguish affordance and mechanical actions.
Object Instance Identification in Dynamic Environments
Jun 10, 2022
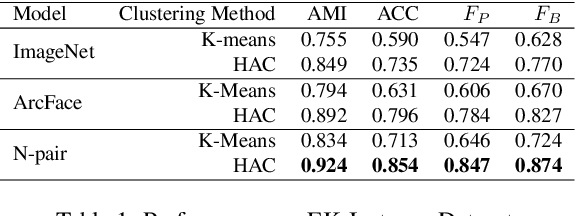
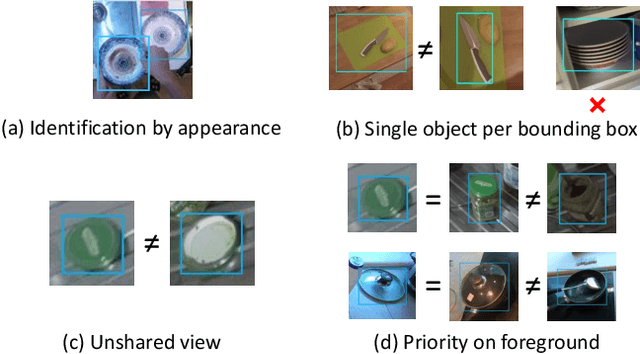

We study the problem of identifying object instances in a dynamic environment where people interact with the objects. In such an environment, objects' appearance changes dynamically by interaction with other entities, occlusion by hands, background change, etc. This leads to a larger intra-instance variation of appearance than in static environments. To discover the challenges in this setting, we newly built a benchmark of more than 1,500 instances built on the EPIC-KITCHENS dataset which includes natural activities and conducted an extensive analysis of it. Experimental results suggest that (i) robustness against instance-specific appearance change (ii) integration of low-level (e.g., color, texture) and high-level (e.g., object category) features (iii) foreground feature selection on overlapping objects are required for further improvement.
Efficient Annotation and Learning for 3D Hand Pose Estimation: A Survey
Jun 07, 2022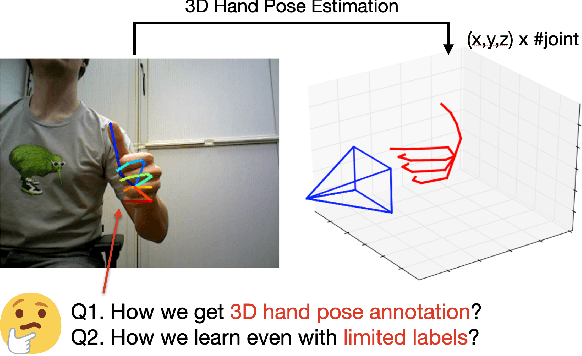
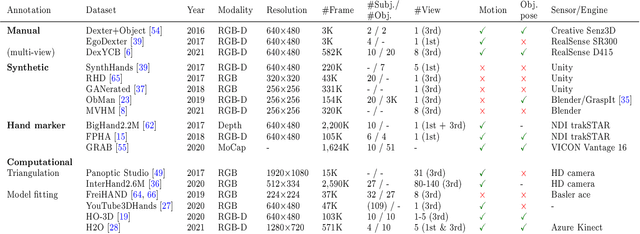
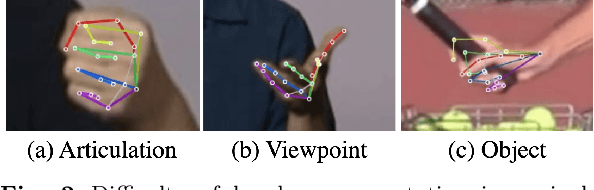
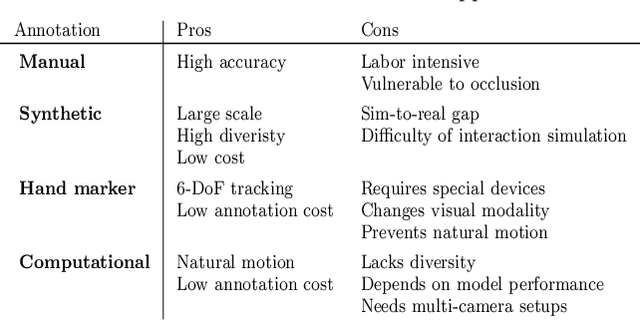
In this survey, we present comprehensive analysis of 3D hand pose estimation from the perspective of efficient annotation and learning. In particular, we study recent approaches for 3D hand pose annotation and learning methods with limited annotated data. In 3D hand pose estimation, collecting 3D hand pose annotation is a key step in developing hand pose estimators and their applications, such as video understanding, AR/VR, and robotics. However, acquiring annotated 3D hand poses is cumbersome, e.g., due to the difficulty of accessing 3D information and occlusion. Motivated by elucidating how recent works address the annotation issue, we investigated annotation methods classified as manual, synthetic-model-based, hand-sensor-based, and computational approaches. Since these annotation methods are not always available on a large scale, we examined methods of learning 3D hand poses when we do not have enough annotated data, namely self-supervised pre-training, semi-supervised learning, and domain adaptation. Based on the analysis of these efficient annotation and learning, we further discuss limitations and possible future directions of this field.
Domain Adaptive Hand Keypoint and Pixel Localization in the Wild
Mar 21, 2022
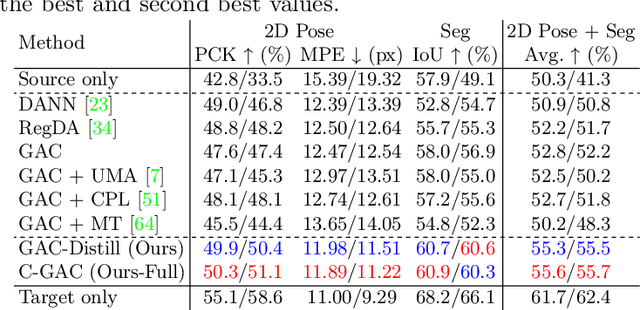
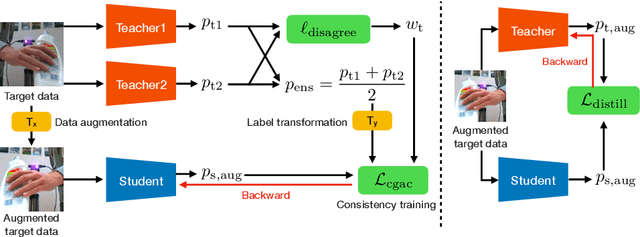
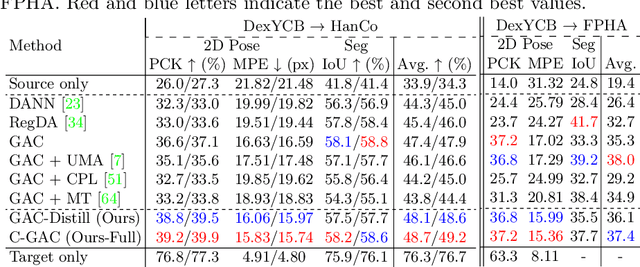
We aim to improve the performance of regressing hand keypoints and segmenting pixel-level hand masks under new imaging conditions (e.g., outdoors) when we only have labeled images taken under very different conditions (e.g., indoors). In the real world, it is important that the model trained for both tasks works under various imaging conditions. However, their variation covered by existing labeled hand datasets is limited. Thus, it is necessary to adapt the model trained on the labeled images (source) to unlabeled images (target) with unseen imaging conditions. While self-training domain adaptation methods (i.e., learning from the unlabeled target images in a self-supervised manner) have been developed for both tasks, their training may degrade performance when the predictions on the target images are noisy. To avoid this, it is crucial to assign a low importance (confidence) weight to the noisy predictions during self-training. In this paper, we propose to utilize the divergence of two predictions to estimate the confidence of the target image for both tasks. These predictions are given from two separate networks, and their divergence helps identify the noisy predictions. To integrate our proposed confidence estimation into self-training, we propose a teacher-student framework where the two networks (teachers) provide supervision to a network (student) for self-training, and the teachers are learned from the student by knowledge distillation. Our experiments show its superiority over state-of-the-art methods in adaptation settings with different lighting, grasping objects, backgrounds, and camera viewpoints. Our method improves by 4% the multi-task score on HO3D compared to the latest adversarial adaptation method. We also validate our method on Ego4D, egocentric videos with rapid changes in imaging conditions outdoors.
Background Mixup Data Augmentation for Hand and Object-in-Contact Detection
Mar 01, 2022

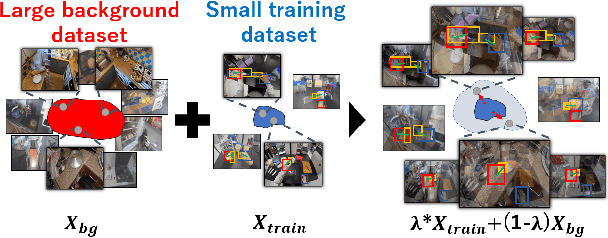
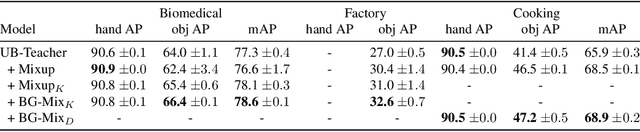
Detecting the positions of human hands and objects-in-contact (hand-object detection) in each video frame is vital for understanding human activities from videos. For training an object detector, a method called Mixup, which overlays two training images to mitigate data bias, has been empirically shown to be effective for data augmentation. However, in hand-object detection, mixing two hand-manipulation images produces unintended biases, e.g., the concentration of hands and objects in a specific region degrades the ability of the hand-object detector to identify object boundaries. We propose a data-augmentation method called Background Mixup that leverages data-mixing regularization while reducing the unintended effects in hand-object detection. Instead of mixing two images where a hand and an object in contact appear, we mix a target training image with background images without hands and objects-in-contact extracted from external image sources, and use the mixed images for training the detector. Our experiments demonstrated that the proposed method can effectively reduce false positives and improve the performance of hand-object detection in both supervised and semi-supervised learning settings.
Stacked Temporal Attention: Improving First-person Action Recognition by Emphasizing Discriminative Clips
Dec 02, 2021

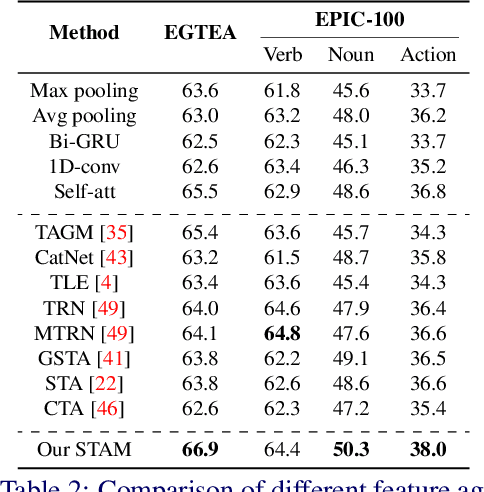
First-person action recognition is a challenging task in video understanding. Because of strong ego-motion and a limited field of view, many backgrounds or noisy frames in a first-person video can distract an action recognition model during its learning process. To encode more discriminative features, the model needs to have the ability to focus on the most relevant part of the video for action recognition. Previous works explored to address this problem by applying temporal attention but failed to consider the global context of the full video, which is critical for determining the relatively significant parts. In this work, we propose a simple yet effective Stacked Temporal Attention Module (STAM) to compute temporal attention based on the global knowledge across clips for emphasizing the most discriminative features. We achieve this by stacking multiple self-attention layers. Instead of naive stacking, which is experimentally proven to be ineffective, we carefully design the input to each self-attention layer so that both the local and global context of the video is considered during generating the temporal attention weights. Experiments demonstrate that our proposed STAM can be built on top of most existing backbones and boost the performance in various datasets.
Leveraging Human Selective Attention for Medical Image Analysis with Limited Training Data
Dec 02, 2021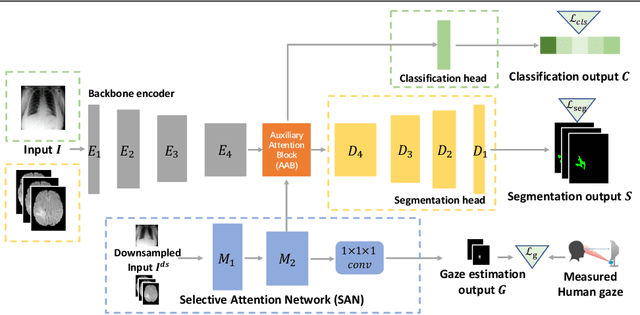
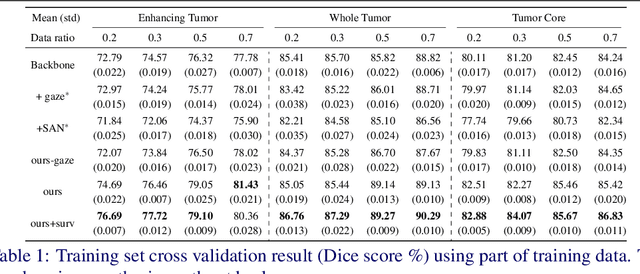
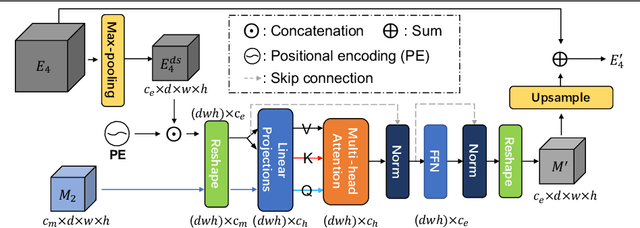

The human gaze is a cost-efficient physiological data that reveals human underlying attentional patterns. The selective attention mechanism helps the cognition system focus on task-relevant visual clues by ignoring the presence of distractors. Thanks to this ability, human beings can efficiently learn from a very limited number of training samples. Inspired by this mechanism, we aim to leverage gaze for medical image analysis tasks with small training data. Our proposed framework includes a backbone encoder and a Selective Attention Network (SAN) that simulates the underlying attention. The SAN implicitly encodes information such as suspicious regions that is relevant to the medical diagnose tasks by estimating the actual human gaze. Then we design a novel Auxiliary Attention Block (AAB) to allow information from SAN to be utilized by the backbone encoder to focus on selective areas. Specifically, this block uses a modified version of a multi-head attention layer to simulate the human visual search procedure. Note that the SAN and AAB can be plugged into different backbones, and the framework can be used for multiple medical image analysis tasks when equipped with task-specific heads. Our method is demonstrated to achieve superior performance on both 3D tumor segmentation and 2D chest X-ray classification tasks. We also show that the estimated gaze probability map of the SAN is consistent with an actual gaze fixation map obtained by board-certified doctors.
Hand-Object Contact Prediction via Motion-Based Pseudo-Labeling and Guided Progressive Label Correction
Oct 19, 2021
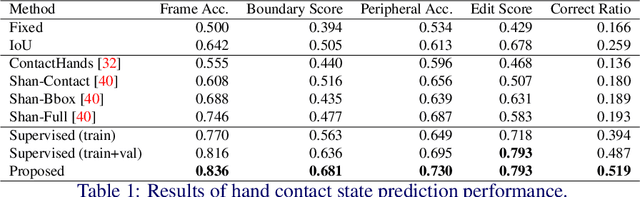

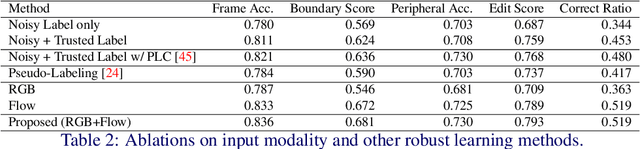
Every hand-object interaction begins with contact. Despite predicting the contact state between hands and objects is useful in understanding hand-object interactions, prior methods on hand-object analysis have assumed that the interacting hands and objects are known, and were not studied in detail. In this study, we introduce a video-based method for predicting contact between a hand and an object. Specifically, given a video and a pair of hand and object tracks, we predict a binary contact state (contact or no-contact) for each frame. However, annotating a large number of hand-object tracks and contact labels is costly. To overcome the difficulty, we propose a semi-supervised framework consisting of (i) automatic collection of training data with motion-based pseudo-labels and (ii) guided progressive label correction (gPLC), which corrects noisy pseudo-labels with a small amount of trusted data. We validated our framework's effectiveness on a newly built benchmark dataset for hand-object contact prediction and showed superior performance against existing baseline methods. Code and data are available at https://github.com/takumayagi/hand_object_contact_prediction.
Ego4D: Around the World in 3,000 Hours of Egocentric Video
Oct 13, 2021



We introduce Ego4D, a massive-scale egocentric video dataset and benchmark suite. It offers 3,025 hours of daily-life activity video spanning hundreds of scenarios (household, outdoor, workplace, leisure, etc.) captured by 855 unique camera wearers from 74 worldwide locations and 9 different countries. The approach to collection is designed to uphold rigorous privacy and ethics standards with consenting participants and robust de-identification procedures where relevant. Ego4D dramatically expands the volume of diverse egocentric video footage publicly available to the research community. Portions of the video are accompanied by audio, 3D meshes of the environment, eye gaze, stereo, and/or synchronized videos from multiple egocentric cameras at the same event. Furthermore, we present a host of new benchmark challenges centered around understanding the first-person visual experience in the past (querying an episodic memory), present (analyzing hand-object manipulation, audio-visual conversation, and social interactions), and future (forecasting activities). By publicly sharing this massive annotated dataset and benchmark suite, we aim to push the frontier of first-person perception. Project page: https://ego4d-data.org/
Spatio-Temporal Perturbations for Video Attribution
Sep 01, 2021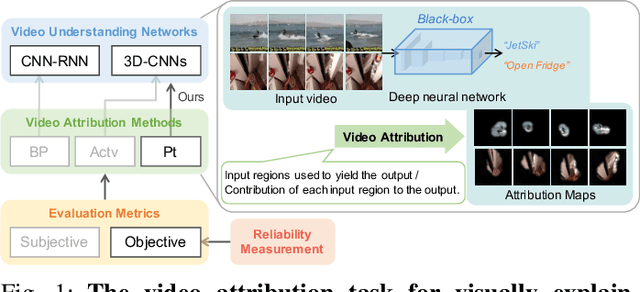

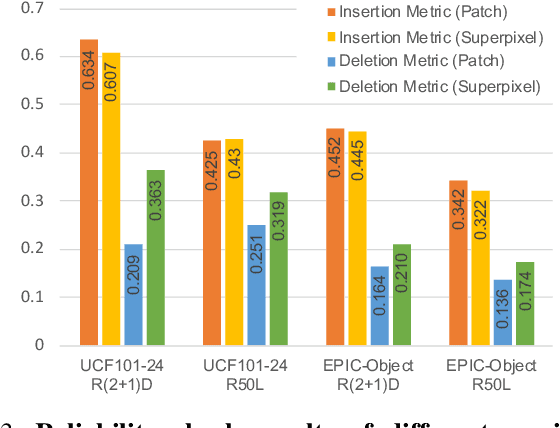
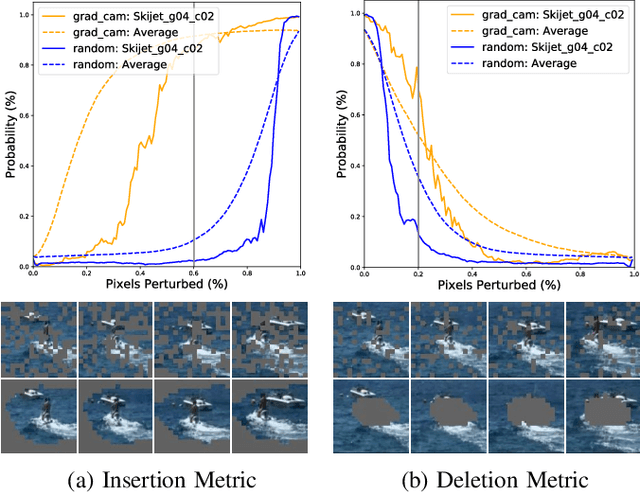
The attribution method provides a direction for interpreting opaque neural networks in a visual way by identifying and visualizing the input regions/pixels that dominate the output of a network. Regarding the attribution method for visually explaining video understanding networks, it is challenging because of the unique spatiotemporal dependencies existing in video inputs and the special 3D convolutional or recurrent structures of video understanding networks. However, most existing attribution methods focus on explaining networks taking a single image as input and a few works specifically devised for video attribution come short of dealing with diversified structures of video understanding networks. In this paper, we investigate a generic perturbation-based attribution method that is compatible with diversified video understanding networks. Besides, we propose a novel regularization term to enhance the method by constraining the smoothness of its attribution results in both spatial and temporal dimensions. In order to assess the effectiveness of different video attribution methods without relying on manual judgement, we introduce reliable objective metrics which are checked by a newly proposed reliability measurement. We verified the effectiveness of our method by both subjective and objective evaluation and comparison with multiple significant attribution methods.