 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDescription and Discussion on DCASE 2022 Challenge Task 2: Unsupervised Anomalous Sound Detection for Machine Condition Monitoring Applying Domain Generalization Techniques
Jun 13, 2022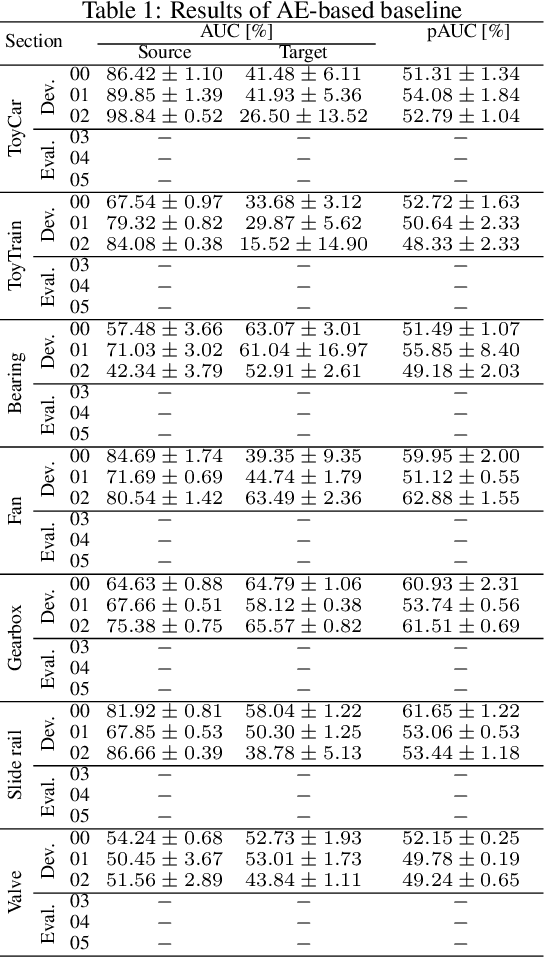
We present the task description of the Detection and Classification of Acoustic Scenes and Events (DCASE) 2022 Challenge Task 2: "Unsupervised anomalous sound detection (ASD) for machine condition monitoring applying domain generalization techniques". Domain shifts are a critical problem for the application of ASD systems. Because domain shifts can change the acoustic characteristics of data, a model trained in a source domain performs poorly for a target domain. In DCASE 2021 Challenge Task 2, we organized an ASD task for handling domain shifts. In this task, it was assumed that the occurrences of domain shifts are known. However, in practice, the domain of each sample may not be given, and the domain shifts can occur implicitly. In 2022 Task 2, we focus on domain generalization techniques that detects anomalies regardless of the domain shifts. Specifically, the domain of each sample is not given in the test data and only one threshold is allowed for all domains. We will add challenge results and analysis of the submissions after the challenge submission deadline.
Hierarchical Conditional Variational Autoencoder Based Acoustic Anomaly Detection
Jun 11, 2022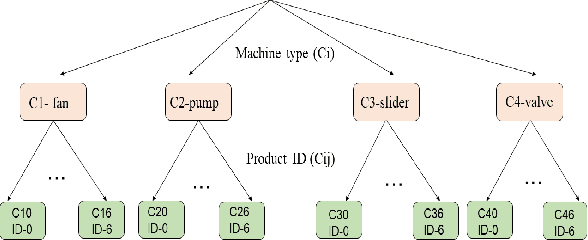
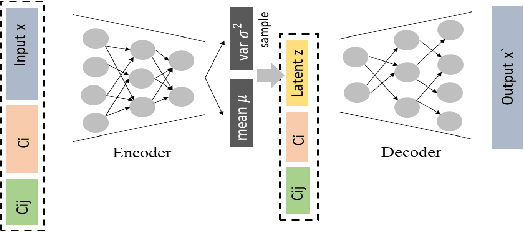
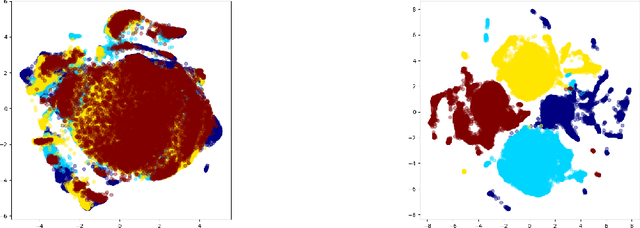
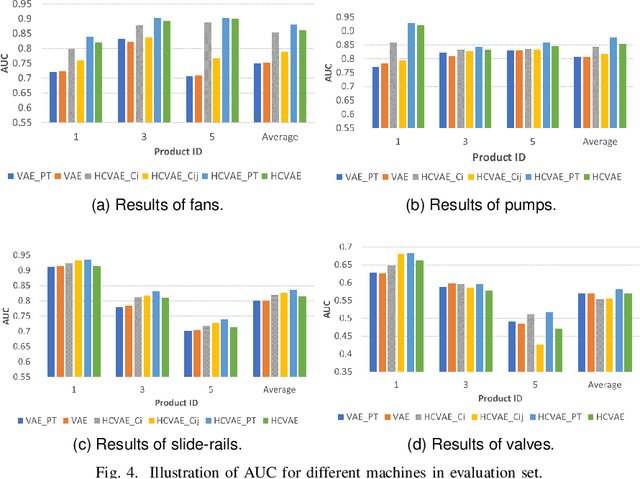
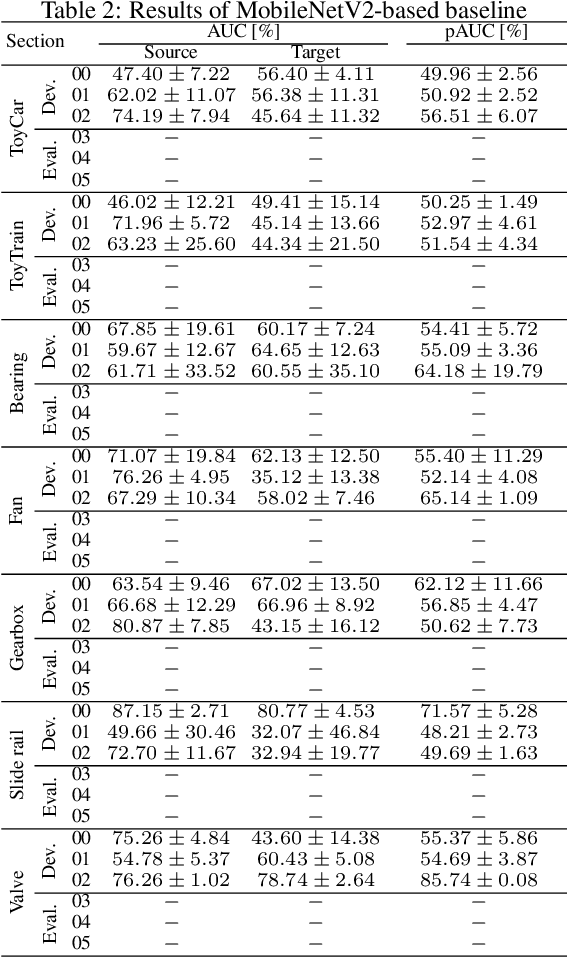
This paper aims to develop an acoustic signal-based unsupervised anomaly detection method for automatic machine monitoring. Existing approaches such as deep autoencoder (DAE), variational autoencoder (VAE), conditional variational autoencoder (CVAE) etc. have limited representation capabilities in the latent space and, hence, poor anomaly detection performance. Different models have to be trained for each different kind of machines to accurately perform the anomaly detection task. To solve this issue, we propose a new method named as hierarchical conditional variational autoencoder (HCVAE). This method utilizes available taxonomic hierarchical knowledge about industrial facility to refine the latent space representation. This knowledge helps model to improve the anomaly detection performance as well. We demonstrated the generalization capability of a single HCVAE model for different types of machines by using appropriate conditions. Additionally, to show the practicability of the proposed approach, (i) we evaluated HCVAE model on different domain and (ii) we checked the effect of partial hierarchical knowledge. Our results show that HCVAE method validates both of these points, and it outperforms the baseline system on anomaly detection task by utmost 15 % on the AUC score metric.
Online Neural Diarization of Unlimited Numbers of Speakers
Jun 06, 2022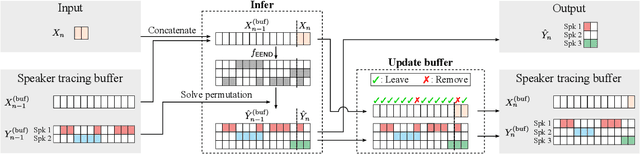
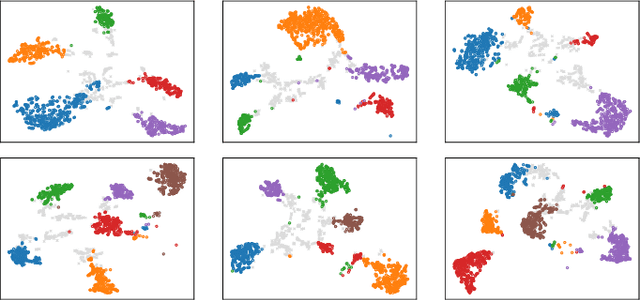
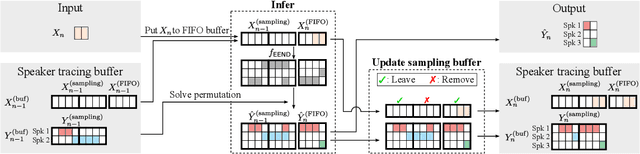
A method to perform offline and online speaker diarization for an unlimited number of speakers is described in this paper. End-to-end neural diarization (EEND) has achieved overlap-aware speaker diarization by formulating it as a multi-label classification problem. It has also been extended for a flexible number of speakers by introducing speaker-wise attractors. However, the output number of speakers of attractor-based EEND is empirically capped; it cannot deal with cases where the number of speakers appearing during inference is higher than that during training because its speaker counting is trained in a fully supervised manner. Our method, EEND-GLA, solves this problem by introducing unsupervised clustering into attractor-based EEND. In the method, the input audio is first divided into short blocks, then attractor-based diarization is performed for each block, and finally the results of each blocks are clustered on the basis of the similarity between locally-calculated attractors. While the number of output speakers is limited within each block, the total number of speakers estimated for the entire input can be higher than the limitation. To use EEND-GLA in an online manner, our method also extends the speaker-tracing buffer, which was originally proposed to enable online inference of conventional EEND. We introduces a block-wise buffer update to make the speaker-tracing buffer compatible with EEND-GLA. Finally, to improve online diarization, our method improves the buffer update method and revisits the variable chunk-size training of EEND. The experimental results demonstrate that EEND-GLA can perform speaker diarization of an unseen number of speakers in both offline and online inferences.
MIMII DG: Sound Dataset for Malfunctioning Industrial Machine Investigation and Inspection for Domain Generalization Task
May 27, 2022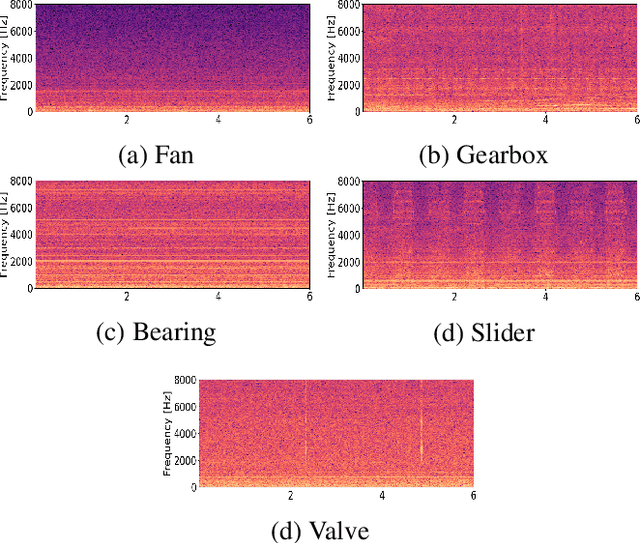

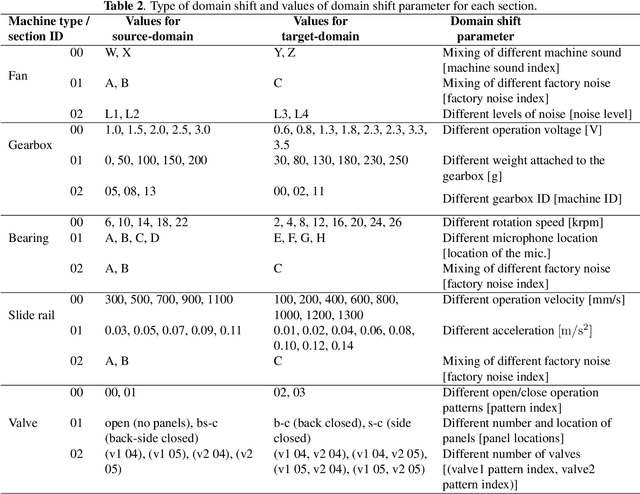
We present a machine sound dataset to benchmark domain generalization techniques for anomalous sound detection (ASD). To handle performance degradation caused by domain shifts that are difficult to detect or too frequent to adapt, domain generalization techniques are preferred. However, currently available datasets have difficulties in evaluating these techniques, such as limited number of values for parameters that cause domain shifts (domain shift parameters). In this paper, we present the first ASD dataset for the domain generalization techniques, called MIMII DG. The dataset consists of five machine types and three domain shift scenarios for each machine type. We prepared at least two values for the domain shift parameters in the source domain. Also, we introduced domain shifts that can be difficult to notice. Experimental results using two baseline systems indicate that the dataset reproduces the domain shift scenarios and is useful for benchmarking domain generalization techniques.
Anomalous Sound Detection Based on Machine Activity Detection
Apr 15, 2022
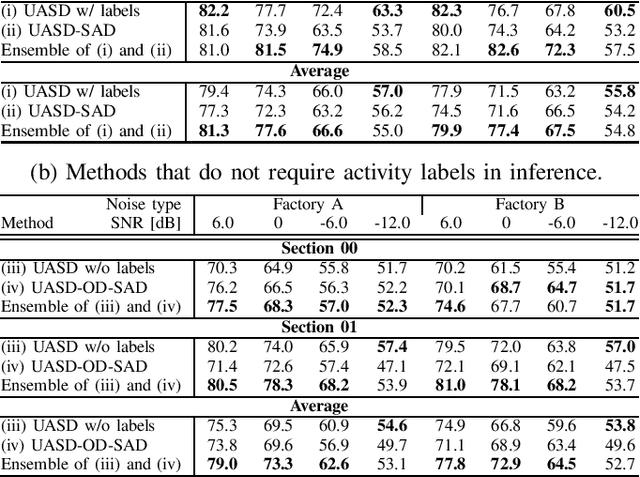
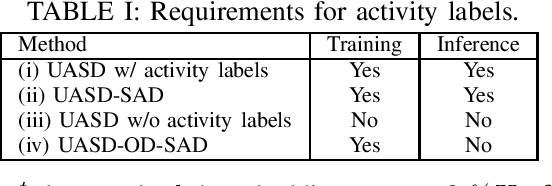
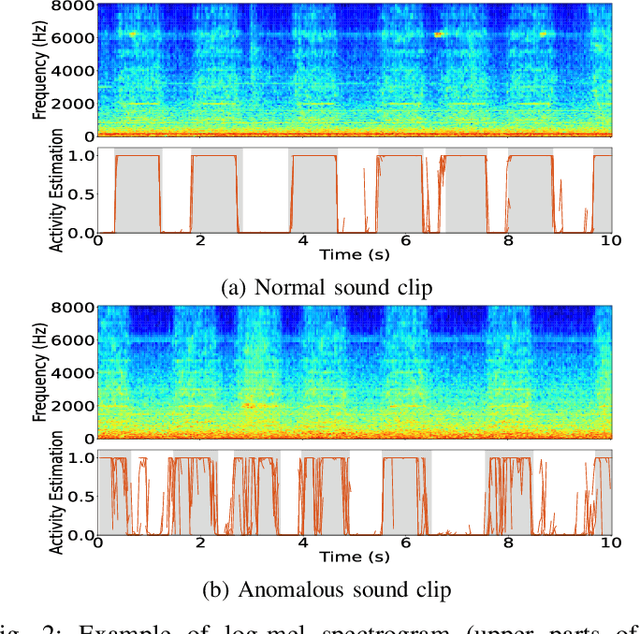
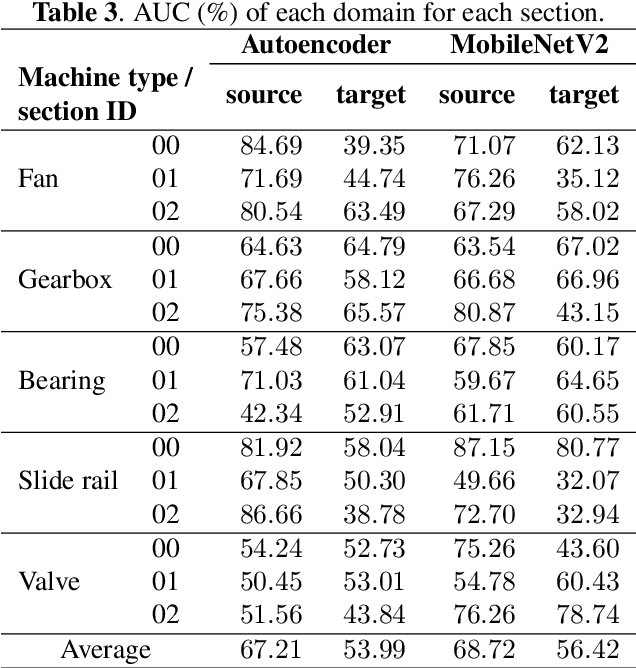
We have developed an unsupervised anomalous sound detection method for machine condition monitoring that utilizes an auxiliary task -- detecting when the target machine is active. First, we train a model that detects machine activity by using normal data with machine activity labels and then use the activity-detection error as the anomaly score for a given sound clip if we have access to the ground-truth activity labels in the inference phase. If these labels are not available, the anomaly score is calculated through outlier detection on the embedding vectors obtained by the activity-detection model. Solving this auxiliary task enables the model to learn the difference between the target machine sounds and similar background noise, which makes it possible to identify small deviations in the target sounds. Experimental results showed that the proposed method improves the anomaly-detection performance of the conventional method complementarily by means of an ensemble.
Environmental Sound Extraction Using Onomatopoeia
Dec 02, 2021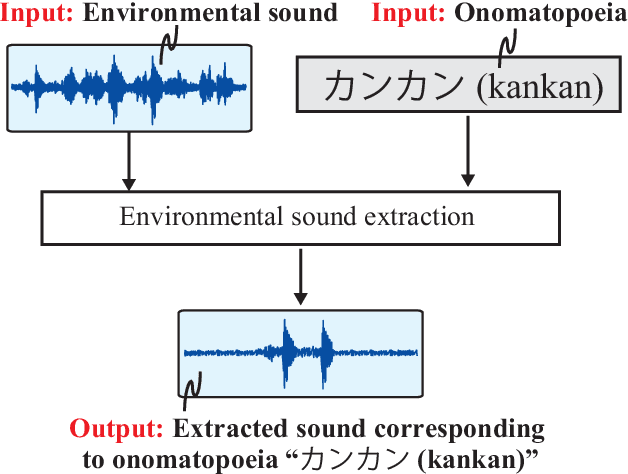
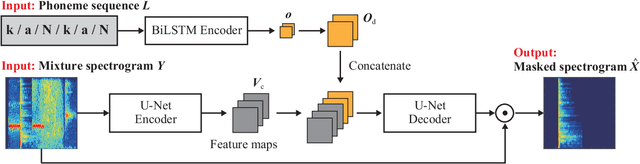
Onomatopoeia, which is a character sequence that phonetically imitates a sound, is effective in expressing characteristics of sound such as duration, pitch, and timbre. We propose an environmental-sound-extraction method using onomatopoeia to specify the target sound to be extracted. With this method, we estimate a time-frequency mask from an input mixture spectrogram and onomatopoeia by using U-Net architecture then extract the corresponding target sound by masking the spectrogram. Experimental results indicate that the proposed method can extract only the target sound corresponding to onomatopoeia and performs better than conventional methods that use sound-event classes to specify the target sound.
Disentangling Physical Parameters for Anomalous Sound Detection Under Domain Shifts
Nov 12, 2021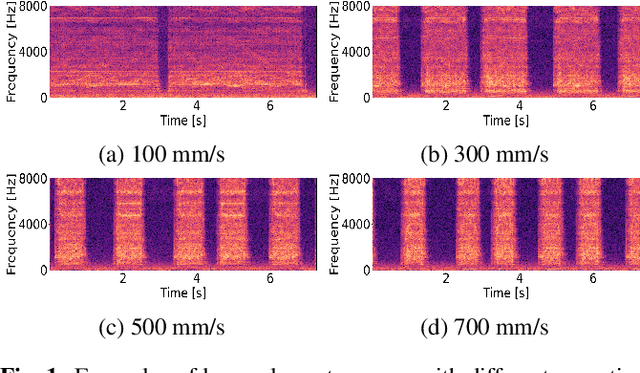
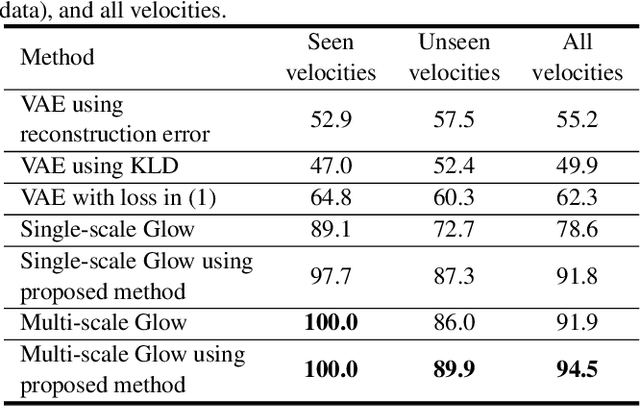
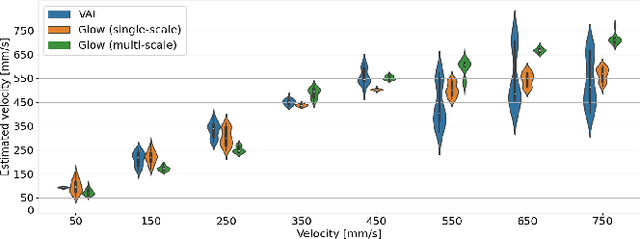
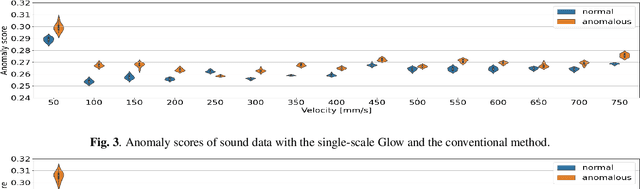
To develop a sound-monitoring system for machines, a method for detecting anomalous sound under domain shifts is proposed. A domain shift occurs when a machine's physical parameters change. Because a domain shift changes the distribution of normal sound data, conventional unsupervised anomaly detection methods can output false positives. To solve this problem, the proposed method constrains some latent variables of a normalizing flows (NF) model to represent physical parameters, which enables disentanglement of the factors of domain shifts and learning of a latent space that is invariant with respect to these domain shifts. Anomaly scores calculated from this domain-shift-invariant latent space are unaffected by such shifts, which reduces false positives and improves the detection performance. Experiments were conducted with sound data from a slide rail under different operation velocities. The results show that the proposed method disentangled the velocity to obtain a latent space that was invariant with respect to domain shifts, which improved the AUC by 13.2% for Glow with a single block and 2.6% for Glow with multiple blocks.
Multi-Channel End-to-End Neural Diarization with Distributed Microphones
Oct 10, 2021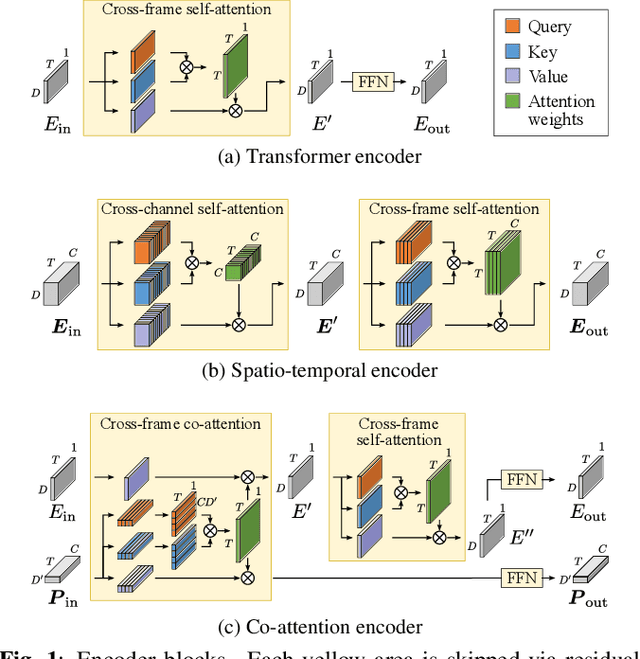
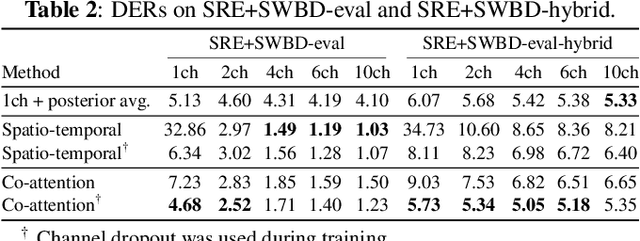
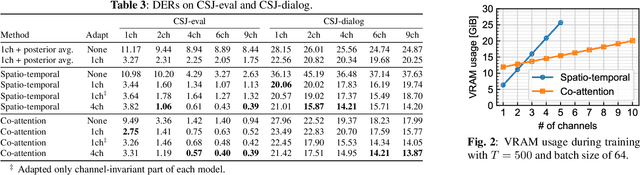
Recent progress on end-to-end neural diarization (EEND) has enabled overlap-aware speaker diarization with a single neural network. This paper proposes to enhance EEND by using multi-channel signals from distributed microphones. We replace Transformer encoders in EEND with two types of encoders that process a multi-channel input: spatio-temporal and co-attention encoders. Both are independent of the number and geometry of microphones and suitable for distributed microphone settings. We also propose a model adaptation method using only single-channel recordings. With simulated and real-recorded datasets, we demonstrated that the proposed method outperformed conventional EEND when a multi-channel input was given while maintaining comparable performance with a single-channel input. We also showed that the proposed method performed well even when spatial information is inoperative given multi-channel inputs, such as in hybrid meetings in which the utterances of multiple remote participants are played back from the same loudspeaker.
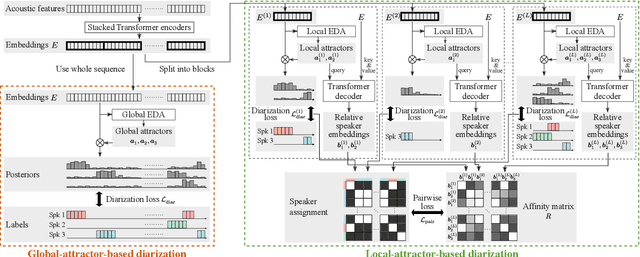
Towards Neural Diarization for Unlimited Numbers of Speakers Using Global and Local Attractors
Jul 04, 2021
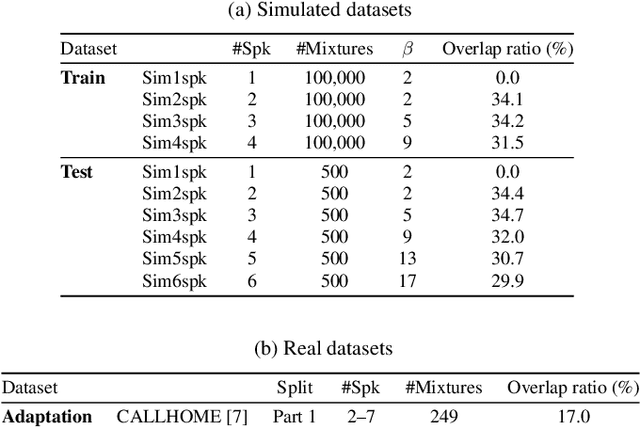
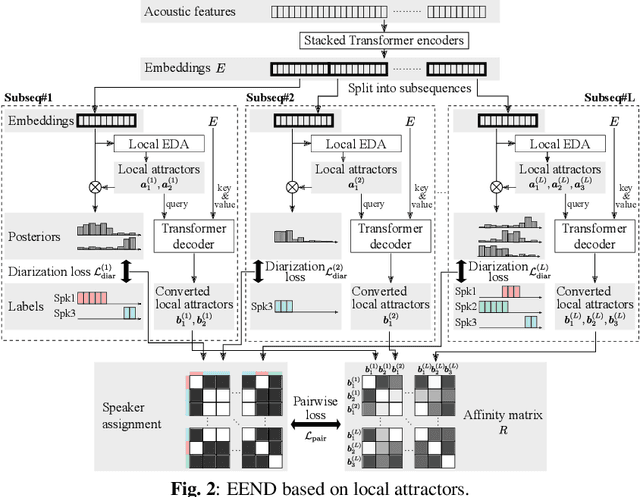
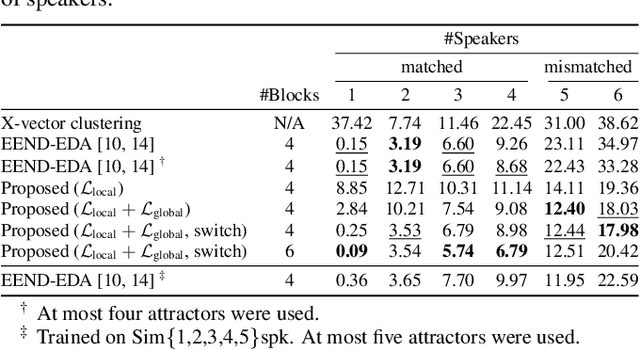
Attractor-based end-to-end diarization is achieving comparable accuracy to the carefully tuned conventional clustering-based methods on challenging datasets. However, the main drawback is that it cannot deal with the case where the number of speakers is larger than the one observed during training. This is because its speaker counting relies on supervised learning. In this work, we introduce an unsupervised clustering process embedded in the attractor-based end-to-end diarization. We first split a sequence of frame-wise embeddings into short subsequences and then perform attractor-based diarization for each subsequence. Given subsequence-wise diarization results, inter-subsequence speaker correspondence is obtained by unsupervised clustering of the vectors computed from the attractors from all the subsequences. This makes it possible to produce diarization results of a large number of speakers for the whole recording even if the number of output speakers for each subsequence is limited. Experimental results showed that our method could produce accurate diarization results of an unseen number of speakers. Our method achieved 11.84 %, 28.33 %, and 19.49 % on the CALLHOME, DIHARD II, and DIHARD III datasets, respectively, each of which is better than the conventional end-to-end diarization methods.
Description and Discussion on DCASE 2021 Challenge Task 2: Unsupervised Anomalous Sound Detection for Machine Condition Monitoring under Domain Shifted Conditions
Jun 08, 2021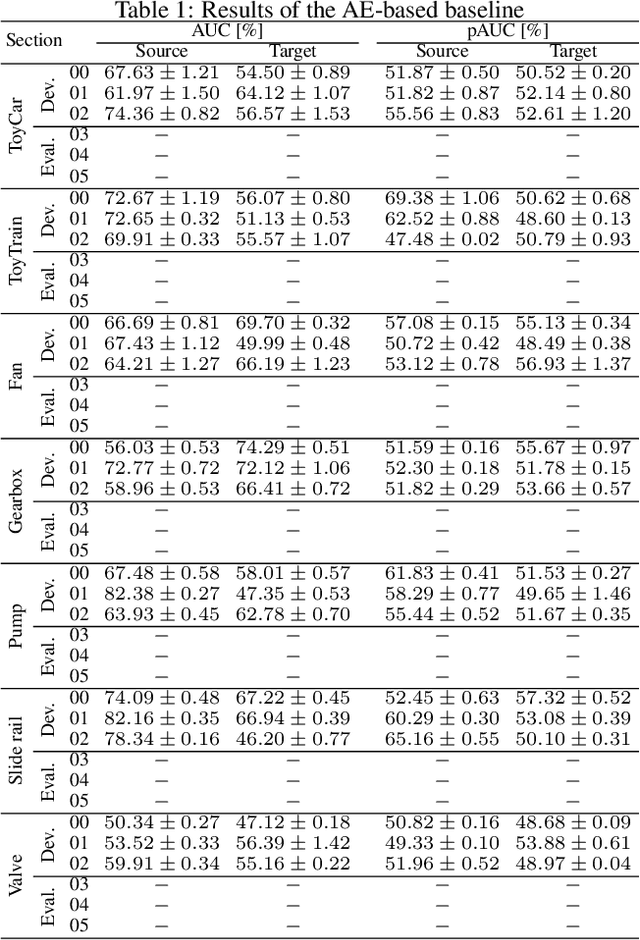
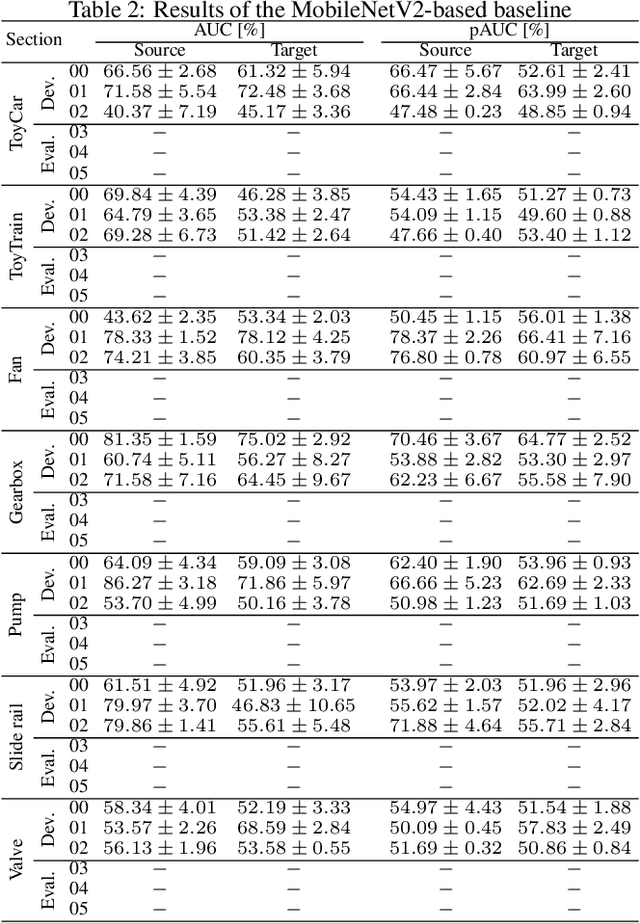
We present the task description and discussion on the results of the DCASE 2021 Challenge Task 2. Last year, we organized unsupervised anomalous sound detection (ASD) task; identifying whether the given sound is normal or anomalous without anomalous training data. In this year, we organize an advanced unsupervised ASD task under domain-shift conditions which focuses on the inevitable problem for the practical use of ASD systems. The main challenge of this task is to detect unknown anomalous sounds where the acoustic characteristics of the training and testing samples are different, i.e. domain-shifted. This problem is frequently occurs due to changes in seasons, manufactured products, and/or environmental noise. After the challenge submission deadline, we will add challenge results and analysis of the submissions.