 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Neural Decompilation
May 20, 2019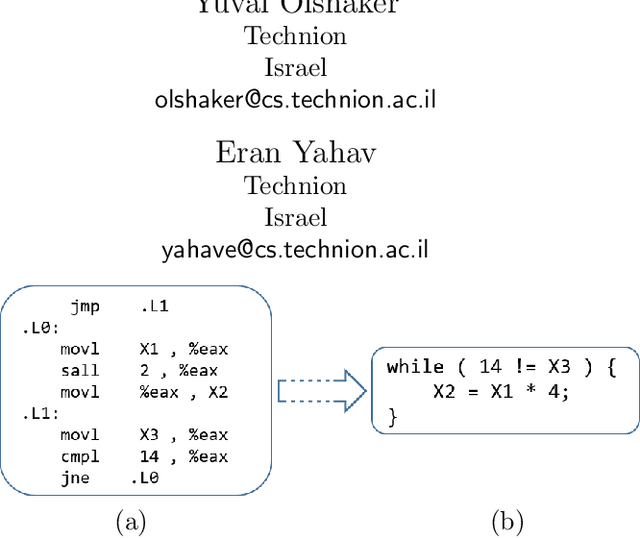

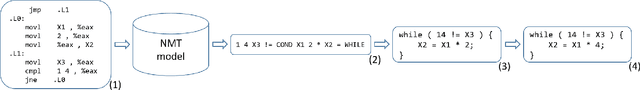

We address the problem of automatic decompilation, converting a program in low-level representation back to a higher-level human-readable programming language. The problem of decompilation is extremely important for security researchers. Finding vulnerabilities and understanding how malware operates is much easier when done over source code. The importance of decompilation has motivated the construction of hand-crafted rule-based decompilers. Such decompilers have been designed by experts to detect specific control-flow structures and idioms in low-level code and lift them to source level. The cost of supporting additional languages or new language features in these models is very high. We present a novel approach to decompilation based on neural machine translation. The main idea is to automatically learn a decompiler from a given compiler. Given a compiler from a source language S to a target language T , our approach automatically trains a decompiler that can translate (decompile) T back to S . We used our framework to decompile both LLVM IR and x86 assembly to C code with high success rates. Using our LLVM and x86 instantiations, we were able to successfully decompile over 97% and 88% of our benchmarks respectively.
Step-by-Step: Separating Planning from Realization in Neural Data-to-Text Generation
May 01, 2019
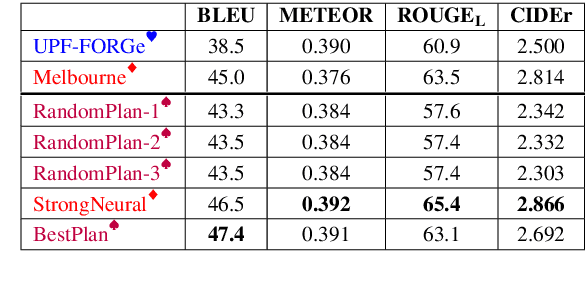

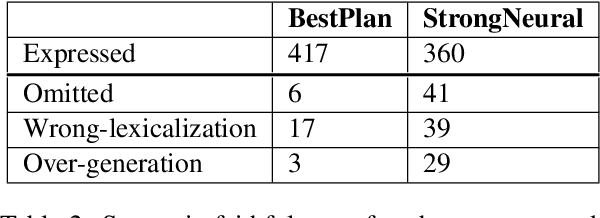
Data-to-text generation can be conceptually divided into two parts: ordering and structuring the information (planning), and generating fluent language describing the information (realization). Modern neural generation systems conflate these two steps into a single end-to-end differentiable system. We propose to split the generation process into a symbolic text-planning stage that is faithful to the input, followed by a neural generation stage that focuses only on realization. For training a plan-to-text generator, we present a method for matching reference texts to their corresponding text plans. For inference time, we describe a method for selecting high-quality text plans for new inputs. We implement and evaluate our approach on the WebNLG benchmark. Our results demonstrate that decoupling text planning from neural realization indeed improves the system's reliability and adequacy while maintaining fluent output. We observe improvements both in BLEU scores and in manual evaluations. Another benefit of our approach is the ability to output diverse realizations of the same input, paving the way to explicit control over the generated text structure.
Studying the Inductive Biases of RNNs with Synthetic Variations of Natural Languages
Mar 26, 2019
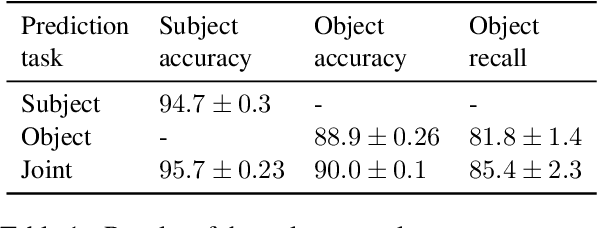
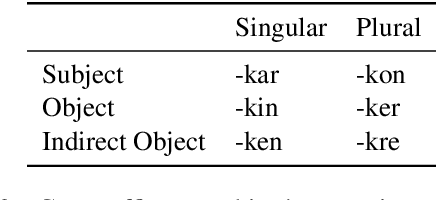
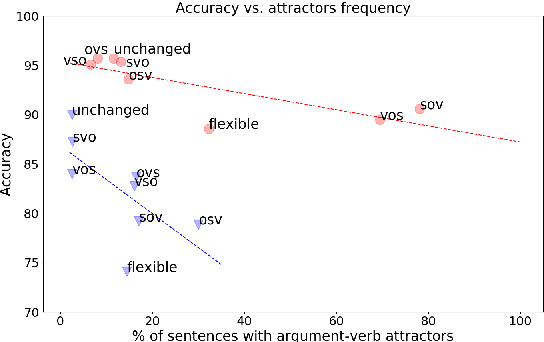
How do typological properties such as word order and morphological case marking affect the ability of neural sequence models to acquire the syntax of a language? Cross-linguistic comparisons of RNNs' syntactic performance (e.g., on subject-verb agreement prediction) are complicated by the fact that any two languages differ in multiple typological properties, as well as by differences in training corpus. We propose a paradigm that addresses these issues: we create synthetic versions of English, which differ from English in one or more typological parameters, and generate corpora for those languages based on a parsed English corpus. We report a series of experiments in which RNNs were trained to predict agreement features for verbs in each of those synthetic languages. Among other findings, (1) performance was higher in subject-verb-object order (as in English) than in subject-object-verb order (as in Japanese), suggesting that RNNs have a recency bias; (2) predicting agreement with both subject and object (polypersonal agreement) improves over predicting each separately, suggesting that underlying syntactic knowledge transfers across the two tasks; and (3) overt morphological case makes agreement prediction significantly easier, regardless of word order.
Aligning Vector-spaces with Noisy Supervised Lexicons
Mar 25, 2019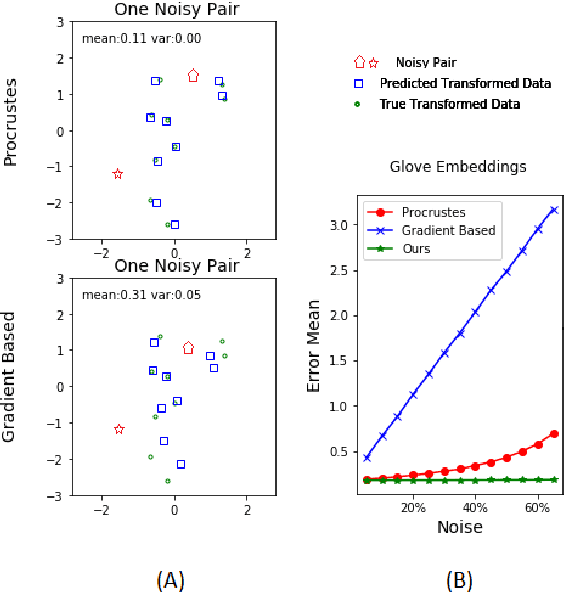

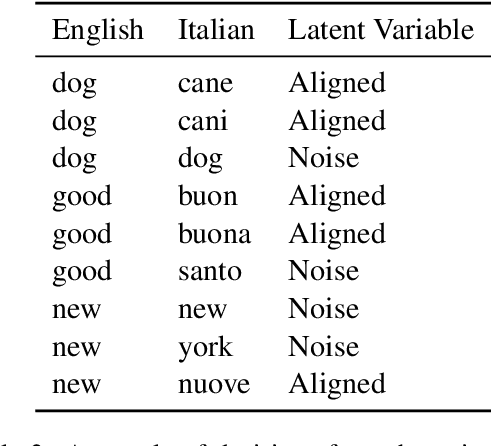
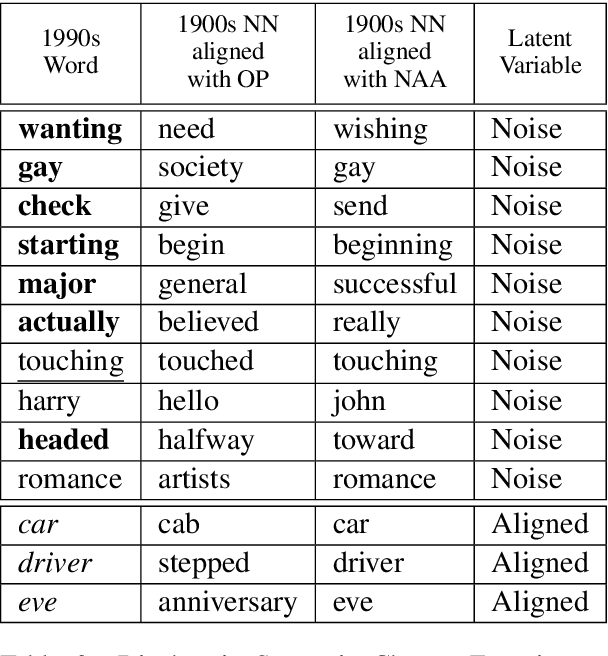
The problem of learning to translate between two vector spaces given a set of aligned points arises in several application areas of NLP. Current solutions assume that the lexicon which defines the alignment pairs is noise-free. We consider the case where the set of aligned points is allowed to contain an amount of noise, in the form of incorrect lexicon pairs and show that this arises in practice by analyzing the edited dictionaries after the cleaning process. We demonstrate that such noise substantially degrades the accuracy of the learned translation when using current methods. We propose a model that accounts for noisy pairs. This is achieved by introducing a generative model with a compatible iterative EM algorithm. The algorithm jointly learns the noise level in the lexicon, finds the set of noisy pairs, and learns the mapping between the spaces. We demonstrate the effectiveness of our proposed algorithm on two alignment problems: bilingual word embedding translation, and mapping between diachronic embedding spaces for recovering the semantic shifts of words across time periods.
Lipstick on a Pig: Debiasing Methods Cover up Systematic Gender Biases in Word Embeddings But do not Remove Them
Mar 09, 2019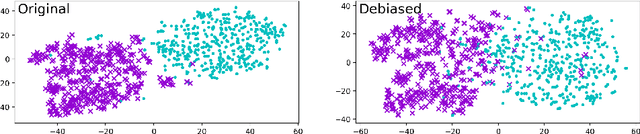
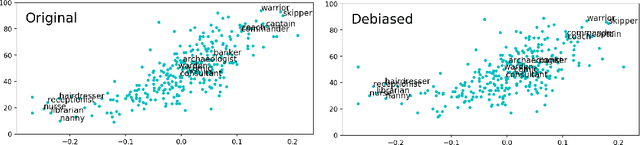
Word embeddings are widely used in NLP for a vast range of tasks. It was shown that word embeddings derived from text corpora reflect gender biases in society. This phenomenon is pervasive and consistent across different word embedding models, causing serious concern. Several recent works tackle this problem, and propose methods for significantly reducing this gender bias in word embeddings, demonstrating convincing results. However, we argue that this removal is superficial. While the bias is indeed substantially reduced according to the provided bias definition, the actual effect is mostly hiding the bias, not removing it. The gender bias information is still reflected in the distances between "gender-neutralized" words in the debiased embeddings, and can be recovered from them. We present a series of experiments to support this claim, for two debiasing methods. We conclude that existing bias removal techniques are insufficient, and should not be trusted for providing gender-neutral modeling.
Filling Gender & Number Gaps in Neural Machine Translation with Black-box Context Injection
Mar 08, 2019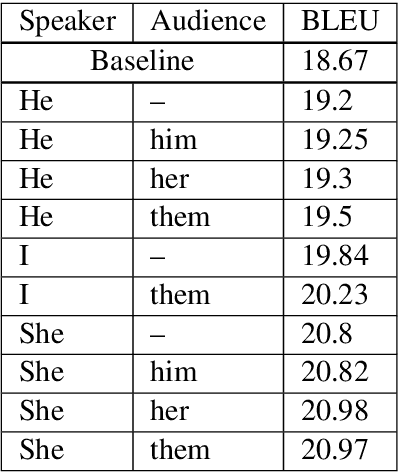
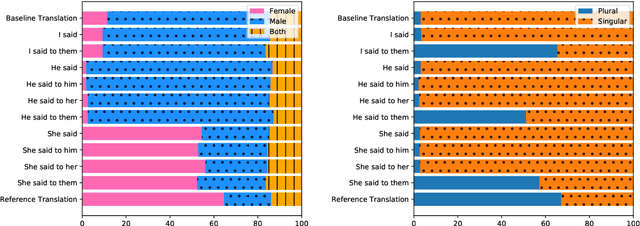
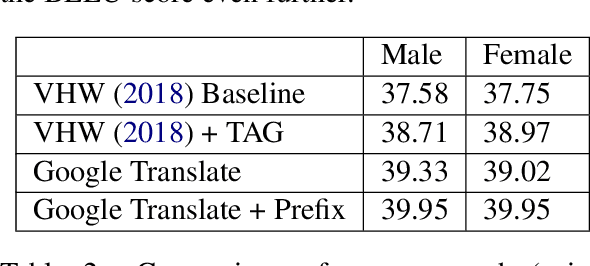
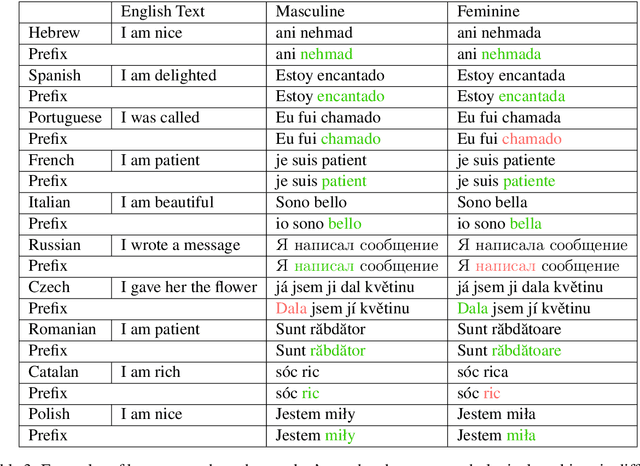
When translating from a language that does not morphologically mark information such as gender and number into a language that does, translation systems must "guess" this missing information, often leading to incorrect translations in the given context. We propose a black-box approach for injecting the missing information to a pre-trained neural machine translation system, allowing to control the morphological variations in the generated translations without changing the underlying model or training data. We evaluate our method on an English to Hebrew translation task, and show that it is effective in injecting the gender and number information and that supplying the correct information improves the translation accuracy in up to 2.3 BLEU on a female-speaker test set for a state-of-the-art online black-box system. Finally, we perform a fine-grained syntactic analysis of the generated translations that shows the effectiveness of our method.
A Little Is Enough: Circumventing Defenses For Distributed Learning
Feb 16, 2019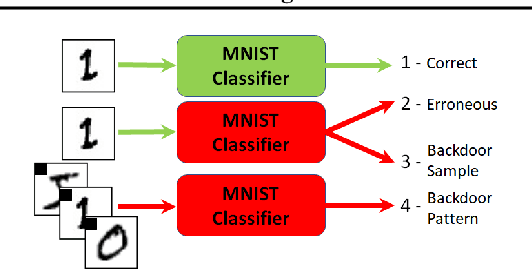
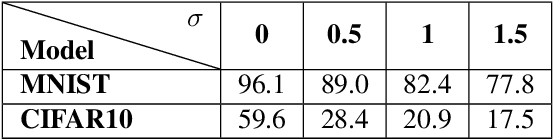
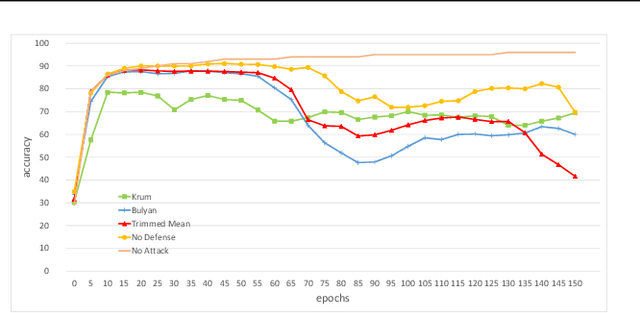
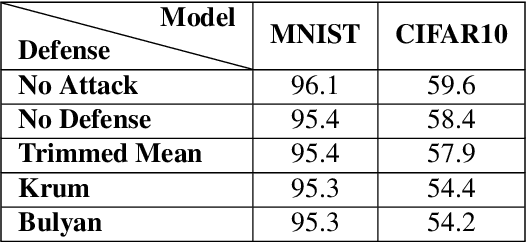
Distributed learning is central for large-scale training of deep-learning models. However, they are exposed to a security threat in which Byzantine participants can interrupt or control the learning process. Previous attack models and their corresponding defenses assume that the rogue participants are (a) omniscient (know the data of all other participants), and (b) introduce large change to the parameters. We show that small but well-crafted changes are sufficient, leading to a novel non-omniscient attack on distributed learning that go undetected by all existing defenses. We demonstrate our attack method works not only for preventing convergence but also for repurposing of the model behavior (backdooring). We show that 20% of corrupt workers are sufficient to degrade a CIFAR10 model accuracy by 50%, as well as to introduce backdoors into MNIST and CIFAR10 models without hurting their accuracy
Assessing BERT's Syntactic Abilities
Jan 16, 2019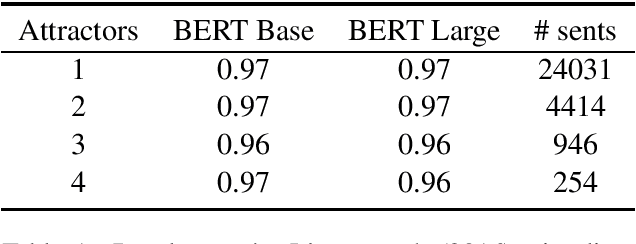
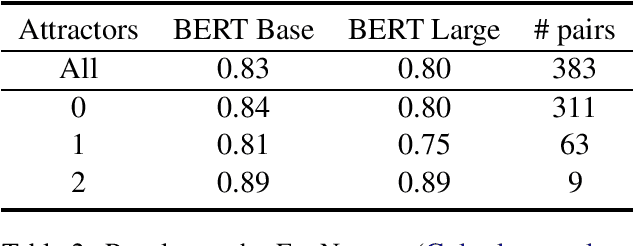
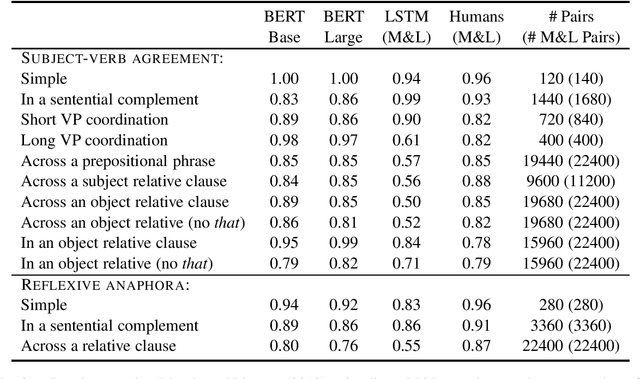
I assess the extent to which the recently introduced BERT model captures English syntactic phenomena, using (1) naturally-occurring subject-verb agreement stimuli; (2) "coloreless green ideas" subject-verb agreement stimuli, in which content words in natural sentences are randomly replaced with words sharing the same part-of-speech and inflection; and (3) manually crafted stimuli for subject-verb agreement and reflexive anaphora phenomena. The BERT model performs remarkably well on all cases.
Language Modeling for Code-Switching: Evaluation, Integration of Monolingual Data, and Discriminative Training
Oct 28, 2018



We focus on the problem of language modeling for code-switched language, in the context of automatic speech recognition (ASR). Language modeling for code-switched language is challenging for (at least) three reasons: (1) lack of available large-scale code-switched data for training; (2) lack of a replicable evaluation setup that is ASR directed yet isolates language modeling performance from the other intricacies of the ASR system; and (3) the reliance on generative modeling. We tackle these three issues: we propose an ASR-motivated evaluation setup which is decoupled from an ASR system and the choice of vocabulary, and provide an evaluation dataset for English-Spanish code-switching. This setup lends itself to a discriminative training approach, which we demonstrate to work better than generative language modeling. Finally, we present an effective training protocol that integrates small amounts of code-switched data with large amounts of monolingual data, for both the generative and discriminative cases.
Understanding Convolutional Neural Networks for Text Classification
Sep 21, 2018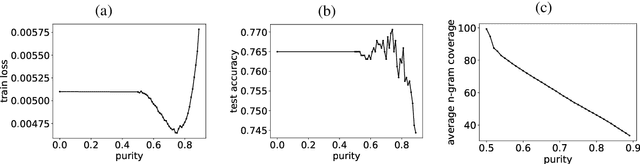
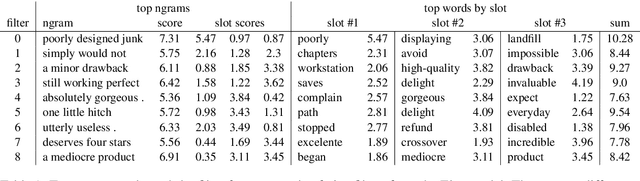
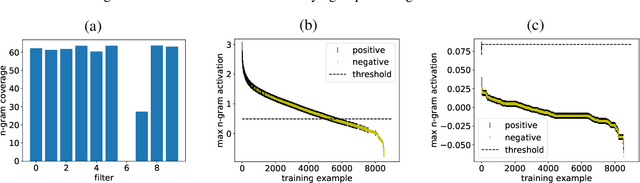
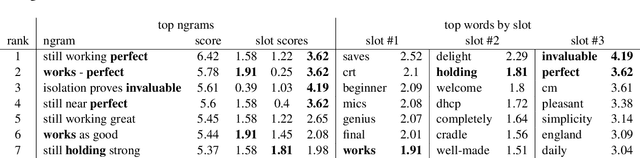
We present an analysis into the inner workings of Convolutional Neural Networks (CNNs) for processing text. CNNs used for computer vision can be interpreted by projecting filters into image space, but for discrete sequence inputs CNNs remain a mystery. We aim to understand the method by which the networks process and classify text. We examine common hypotheses to this problem: that filters, accompanied by global max-pooling, serve as ngram detectors. We show that filters may capture several different semantic classes of ngrams by using different activation patterns, and that global max-pooling induces behavior which separates important ngrams from the rest. Finally, we show practical use cases derived from our findings in the form of model interpretability (explaining a trained model by deriving a concrete identity for each filter, bridging the gap between visualization tools in vision tasks and NLP) and prediction interpretability (explaining predictions).