 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Document-Level Paraphrase Generation with Sentence Rewriting and Reordering
Sep 15, 2021
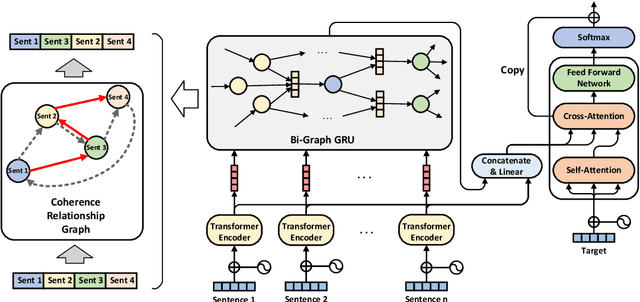
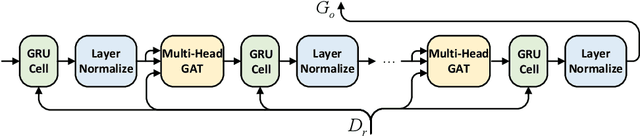
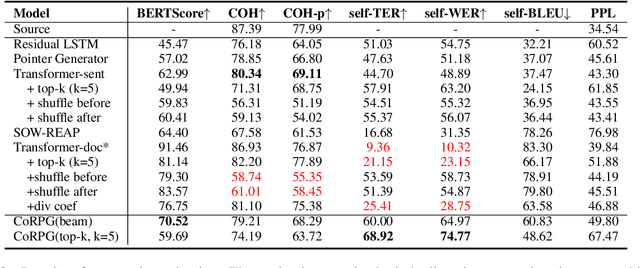
Paraphrase generation is an important task in natural language processing. Previous works focus on sentence-level paraphrase generation, while ignoring document-level paraphrase generation, which is a more challenging and valuable task. In this paper, we explore the task of document-level paraphrase generation for the first time and focus on the inter-sentence diversity by considering sentence rewriting and reordering. We propose CoRPG (Coherence Relationship guided Paraphrase Generation), which leverages graph GRU to encode the coherence relationship graph and get the coherence-aware representation for each sentence, which can be used for re-arranging the multiple (possibly modified) input sentences. We create a pseudo document-level paraphrase dataset for training CoRPG. Automatic evaluation results show CoRPG outperforms several strong baseline models on the BERTScore and diversity scores. Human evaluation also shows our model can generate document paraphrase with more diversity and semantic preservation.
Making Better Use of Bilingual Information for Cross-Lingual AMR Parsing
Jun 09, 2021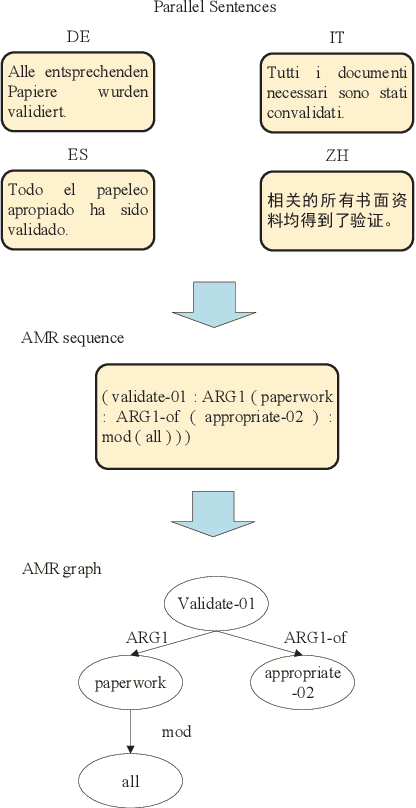

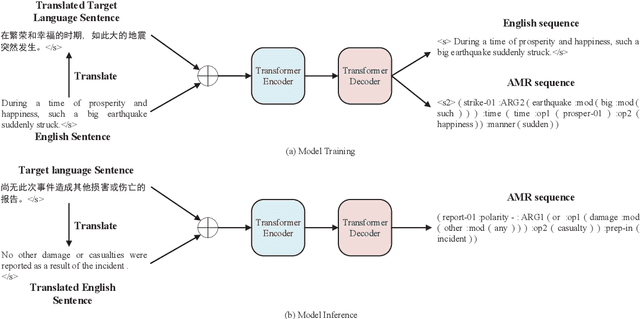
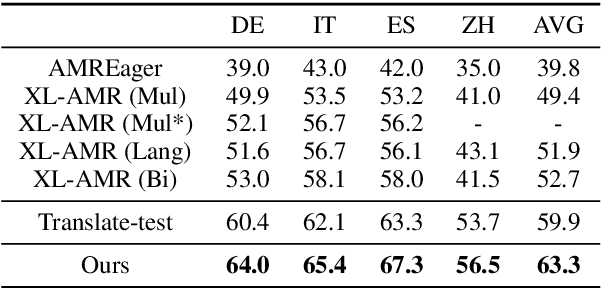
Abstract Meaning Representation (AMR) is a rooted, labeled, acyclic graph representing the semantics of natural language. As previous works show, although AMR is designed for English at first, it can also represent semantics in other languages. However, they find that concepts in their predicted AMR graphs are less specific. We argue that the misprediction of concepts is due to the high relevance between English tokens and AMR concepts. In this work, we introduce bilingual input, namely the translated texts as well as non-English texts, in order to enable the model to predict more accurate concepts. Besides, we also introduce an auxiliary task, requiring the decoder to predict the English sequences at the same time. The auxiliary task can help the decoder understand what exactly the corresponding English tokens are. Our proposed cross-lingual AMR parser surpasses previous state-of-the-art parser by 10.6 points on Smatch F1 score. The ablation study also demonstrates the efficacy of our proposed modules.
IGSQL: Database Schema Interaction Graph Based Neural Model for Context-Dependent Text-to-SQL Generation
Nov 11, 2020
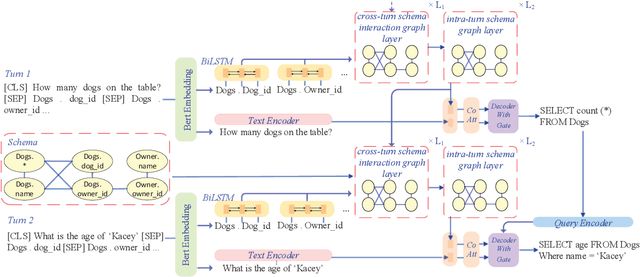
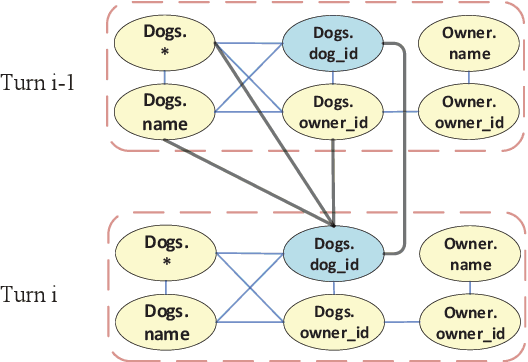
Context-dependent text-to-SQL task has drawn much attention in recent years. Previous models on context-dependent text-to-SQL task only concentrate on utilizing historical user inputs. In this work, in addition to using encoders to capture historical information of user inputs, we propose a database schema interaction graph encoder to utilize historicalal information of database schema items. In decoding phase, we introduce a gate mechanism to weigh the importance of different vocabularies and then make the prediction of SQL tokens. We evaluate our model on the benchmark SParC and CoSQL datasets, which are two large complex context-dependent cross-domain text-to-SQL datasets. Our model outperforms previous state-of-the-art model by a large margin and achieves new state-of-the-art results on the two datasets. The comparison and ablation results demonstrate the efficacy of our model and the usefulness of the database schema interaction graph encoder.