 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Diffusion Distillation via Embedding Loss
Apr 24, 2026Recent advances in distilling expensive diffusion models into efficient few-step generators show significant promise. However, these methods typically demand substantial computational resources and extended training periods, limiting accessibility for resource-constrained researchers, and existing supplementary loss functions have notable limitations. Regression loss requires pre-generating large datasets before training and limits the student model to the teacher's performance, while GAN-based losses suffer from training instability and require careful tuning. In this paper, we propose Embedding Loss (EL), a novel supplementary loss function that complements existing diffusion distillation methods to enhance generation quality and accelerate training with smaller batch sizes. Leveraging feature embeddings from a diverse set of randomly initialized networks, EL effectively aligns the feature distributions between the distilled few-step generator and the original data. By computing Maximum Mean Discrepancy (MMD) in the embedded feature space, EL ensures robust distribution matching, thereby preserving sample fidelity and diversity during distillation. Within distribution matching distillation frameworks, EL demonstrates strong empirical performance for one-step generators. On the CIFAR-10 dataset, our approach achieves state-of-the-art FID values of 1.475 for unconditional generation and 1.380 for conditional generation. Beyond CIFAR-10, we further validate EL across multiple benchmarks and distillation methods, including ImageNet, AFHQ-v2, and FFHQ datasets, using DMD, DI, and CM distillation frameworks, demonstrating consistent improvements over existing one-step distillation methods. Our method also reduces training iterations by up to 80%, offering a more practical and scalable solution for deploying diffusion-based generative models in resource-constrained environments.
VMID: A Multimodal Fusion LLM Framework for Detecting and Identifying Misinformation of Short Videos
Nov 15, 2024



Short video platforms have become important channels for news dissemination, offering a highly engaging and immediate way for users to access current events and share information. However, these platforms have also emerged as significant conduits for the rapid spread of misinformation, as fake news and rumors can leverage the visual appeal and wide reach of short videos to circulate extensively among audiences. Existing fake news detection methods mainly rely on single-modal information, such as text or images, or apply only basic fusion techniques, limiting their ability to handle the complex, multi-layered information inherent in short videos. To address these limitations, this paper presents a novel fake news detection method based on multimodal information, designed to identify misinformation through a multi-level analysis of video content. This approach effectively utilizes different modal representations to generate a unified textual description, which is then fed into a large language model for comprehensive evaluation. The proposed framework successfully integrates multimodal features within videos, significantly enhancing the accuracy and reliability of fake news detection. Experimental results demonstrate that the proposed approach outperforms existing models in terms of accuracy, robustness, and utilization of multimodal information, achieving an accuracy of 90.93%, which is significantly higher than the best baseline model (SV-FEND) at 81.05%. Furthermore, case studies provide additional evidence of the effectiveness of the approach in accurately distinguishing between fake news, debunking content, and real incidents, highlighting its reliability and robustness in real-world applications.
Multi-View Pre-Trained Model for Code Vulnerability Identification
Aug 10, 2022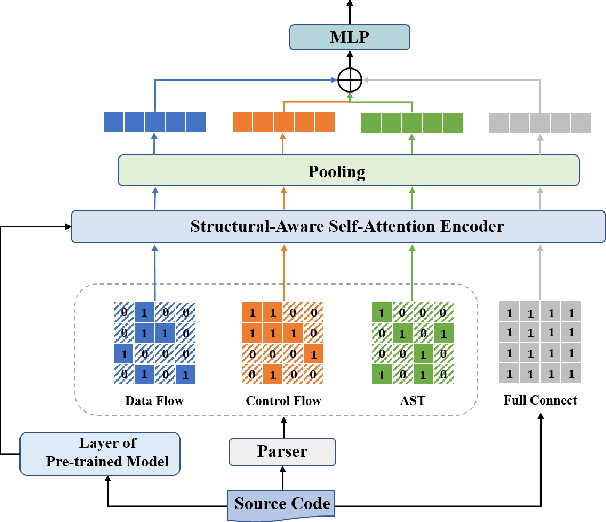
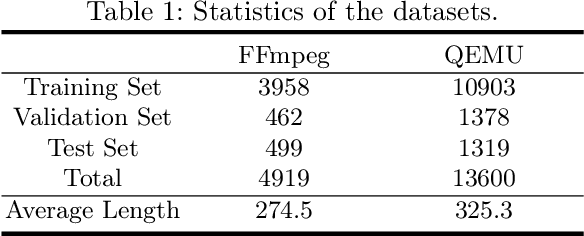
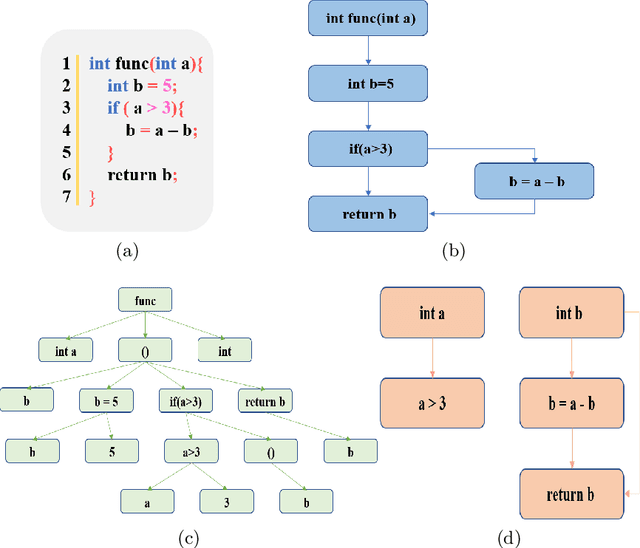
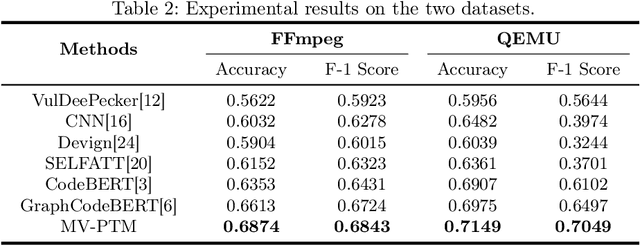
Vulnerability identification is crucial for cyber security in the software-related industry. Early identification methods require significant manual efforts in crafting features or annotating vulnerable code. Although the recent pre-trained models alleviate this issue, they overlook the multiple rich structural information contained in the code itself. In this paper, we propose a novel Multi-View Pre-Trained Model (MV-PTM) that encodes both sequential and multi-type structural information of the source code and uses contrastive learning to enhance code representations. The experiments conducted on two public datasets demonstrate the superiority of MV-PTM. In particular, MV-PTM improves GraphCodeBERT by 3.36\% on average in terms of F1 score.