 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArbitrary-Oriented Ship Detection through Center-Head Point Extraction
Feb 25, 2021
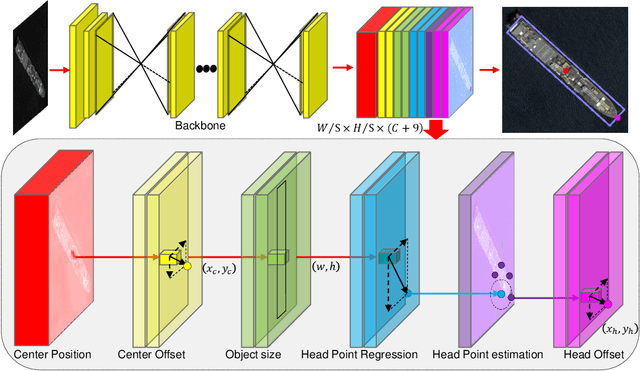
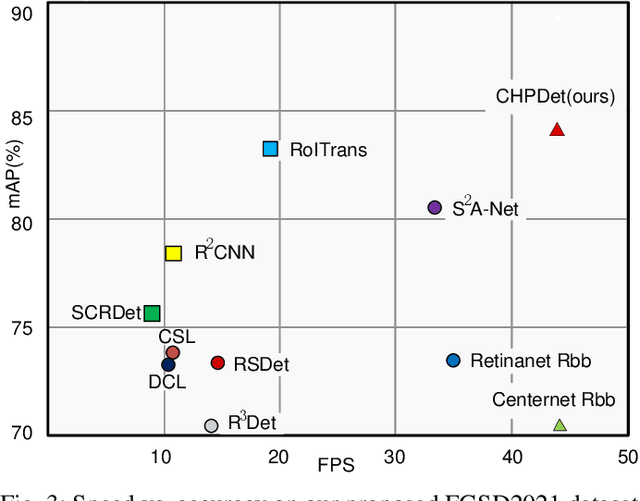

Ship detection in remote sensing images plays a crucial role in various applications and has drawn increasing attention in recent years. However, existing multi-oriented ship detection methods are generally developed on a set of predefined rotated anchor boxes. These predefined boxes not only lead to inaccurate angle predictions but also introduce extra hyper-parameters and high computational cost. Moreover, the prior knowledge of ship size has not been fully exploited by existing methods, which hinders the improvement of their detection accuracy. Aiming at solving the above issues, in this paper, we propose a \emph{center-head point extraction based detector} (named CHPDet) to achieve arbitrary-oriented ship detection in remote sensing images. Our CHPDet formulates arbitrary-oriented ships as rotated boxes with head points which are used to determine the direction. The orientation-invariant model (OIM) is used to produce orientation-invariant feature maps. Keypoint estimation is performed to find the center of ships. Then, the size and head point of the ships are regressed. Finally, we use the target size as prior to finetune the results. Moreover, we introduce a new dataset for multi-class arbitrary-oriented ship detection in remote sensing images at a fixed ground sample distance (GSD) which is named FGSD2021. Experimental results on two ship detection datasets (i.e., FGSD2021 and HRSC2016) demonstrate that our CHPDet achieves state-of-the-art performance and can well distinguish between bow and stern. The code and dataset will be made publicly available.
Symmetric Parallax Attention for Stereo Image Super-Resolution
Nov 07, 2020

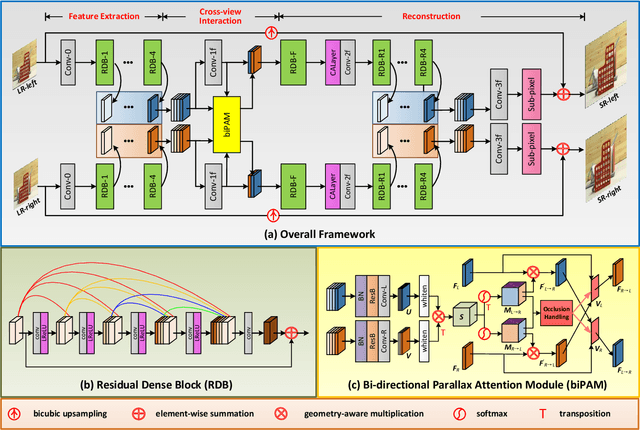
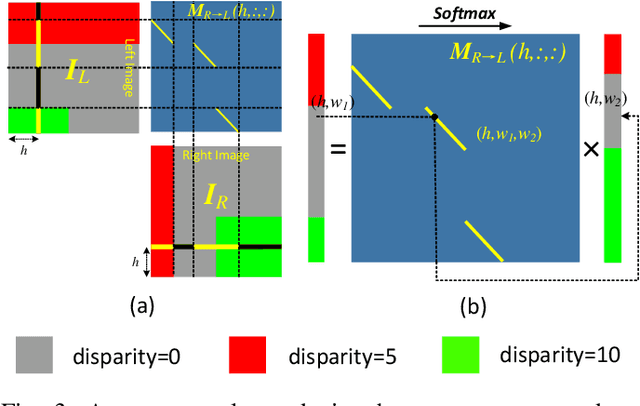
Although recent years have witnessed the great advances in stereo image super-resolution (SR), the beneficial information provided by binocular systems has not been fully used. Since stereo images are highly symmetric under epipolar constraint, in this paper, we improve the performance of stereo image SR by exploiting symmetry cues in stereo image pairs. Specifically, we propose a symmetric bi-directional parallax attention module (biPAM) and an inline occlusion handling scheme to effectively interact cross-view information. Then, we design a Siamese network equipped with a biPAM to super-resolve both sides of views in a highly symmetric manner. Finally, we design several illuminance-robust bilateral losses to enforce stereo consistency. Experiments on four public datasets have demonstrated the superiority of our method. As compared to PASSRnet, our method achieves notable performance improvements with a comparable model size. Source codes are available at https://github.com/YingqianWang/iPASSR.
Parallax Attention for Unsupervised Stereo Correspondence Learning
Sep 16, 2020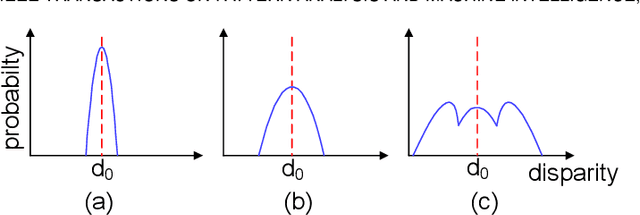
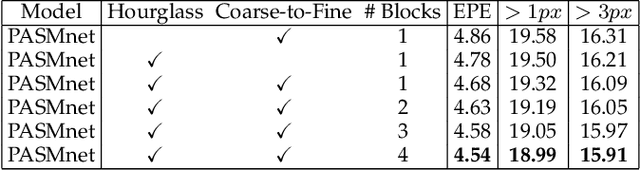
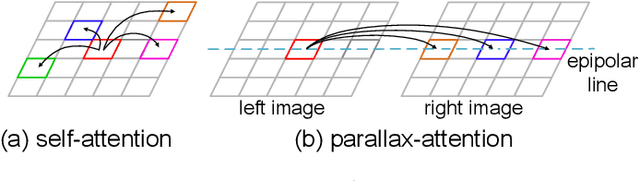

Stereo image pairs encode 3D scene cues into stereo correspondences between the left and right images. To exploit 3D cues within stereo images, recent CNN based methods commonly use cost volume techniques to capture stereo correspondence over large disparities. However, since disparities can vary significantly for stereo cameras with different baselines, focal lengths and resolutions, the fixed maximum disparity used in cost volume techniques hinders them to handle different stereo image pairs with large disparity variations. In this paper, we propose a generic parallax-attention mechanism (PAM) to capture stereo correspondence regardless of disparity variations. Our PAM integrates epipolar constraints with attention mechanism to calculate feature similarities along the epipolar line to capture stereo correspondence. Based on our PAM, we propose a parallax-attention stereo matching network (PASMnet) and a parallax-attention stereo image super-resolution network (PASSRnet) for stereo matching and stereo image super-resolution tasks. Moreover, we introduce a new and large-scale dataset named Flickr1024 for stereo image super-resolution. Experimental results show that our PAM is generic and can effectively learn stereo correspondence under large disparity variations in an unsupervised manner. Comparative results show that our PASMnet and PASSRnet achieve the state-of-the-art performance.
Light Field Image Super-Resolution Using Deformable Convolution
Jul 07, 2020
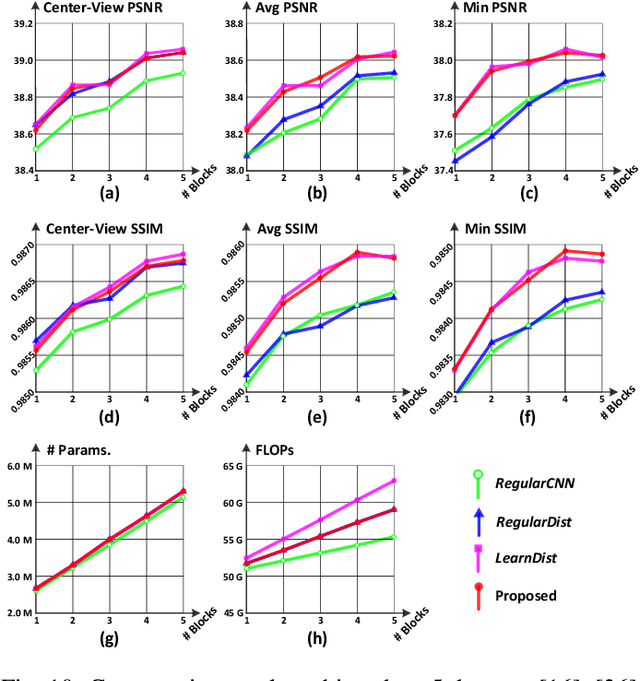
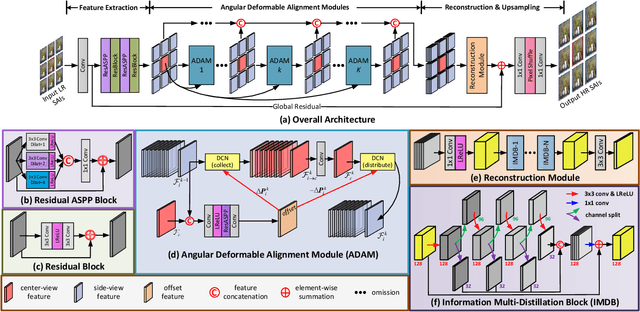

Light field (LF) cameras can record scenes from multiple perspectives, and thus introduce beneficial angular information for image super-resolution (SR). However, it is challenging to incorporate angular information due to disparities among LF images. In this paper, we propose a deformable convolution network (i.e., LF-DFnet) to handle the disparity problem for LF image SR. Specifically, we design an angular deformable alignment module (ADAM) for feature-level alignment. Based on ADAM, we further propose a collect-and-distribute approach to perform bidirectional alignment between the center-view feature and each side-view feature. Using our approach, angular information can be well incorporated and encoded into features of each view, which benefits the SR reconstruction of all LF images. Moreover, we develop a baseline-adjustable LF dataset to evaluate SR performance under different disparities. Experiments on both public and our self-developed datasets have demonstrated the superiority of our method. Our LF-DFnet can generate high-resolution images with more faithful details and achieve state-of-the-art reconstruction accuracy. Besides, our LF-DFnet is more robust to disparity variations, which has not been well addressed in literature.
Learning Sparse Masks for Efficient Image Super-Resolution
Jun 17, 2020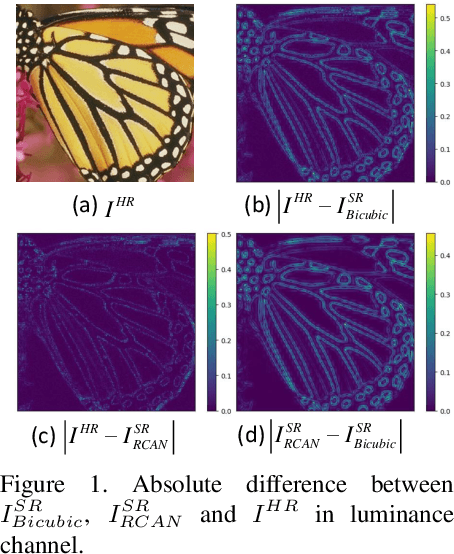
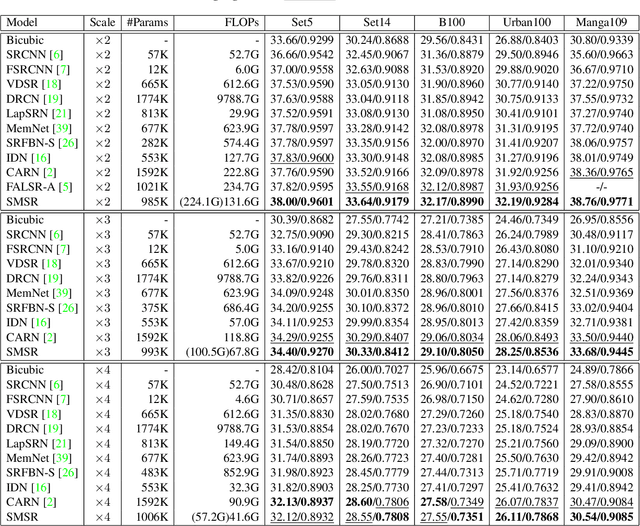
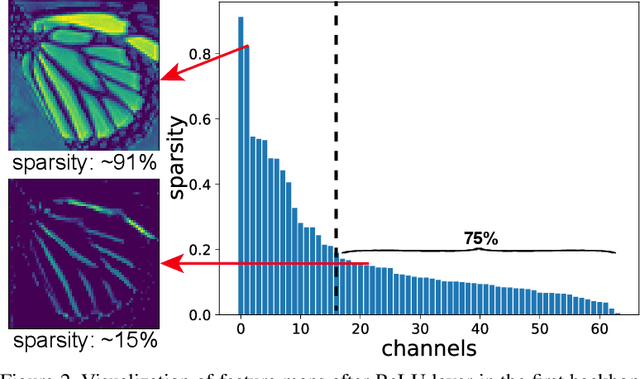

Current CNN-based super-resolution (SR) methods process all locations equally with computational resources being uniformly assigned in space. However, since highfrequency details mainly lie around edges and textures, less computational resources are required for those flat regions. Therefore, existing CNN-based methods involve much redundant computation in flat regions, which increases their computational cost and limits the applications on mobile devices. To address this limitation, we develop an SR network (SMSR) to learn sparse masks to prune redundant computation conditioned on the input image. Within our SMSR, spatial masks learn to identify "important" locations while channel masks learn to mark redundant channels in those "unimportant" regions. Consequently, redundant computation can be accurately located and skipped while maintaining comparable performance. It is demonstrated that our SMSR achieves state-of-the-art performance with 41%/33%/27% FLOPs being reduced for x2/3/4 SR.
Learning for Scale-Arbitrary Super-Resolution from Scale-Specific Networks
Apr 08, 2020
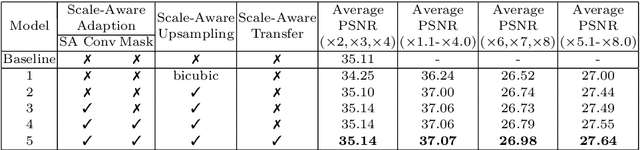
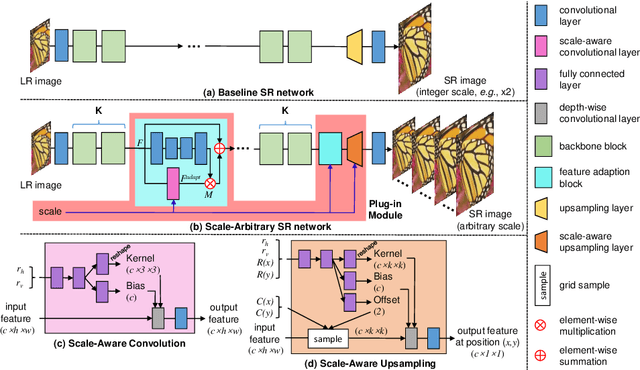
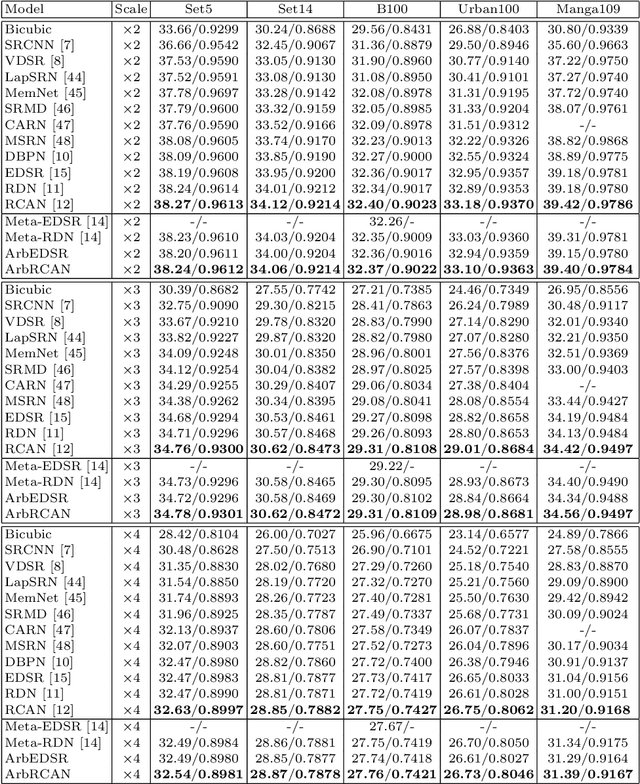
Recently, the performance of single image super-resolution (SR) has been significantly improved with powerful networks. However, these networks are developed for image SR with a single specific integer scale (e.g., x2;x3,x4), and cannot be used for non-integer and asymmetric SR. In this paper, we propose to learn a scale-arbitrary image SR network from scale-specific networks. Specifically, we propose a plug-in module for existing SR networks to perform scale-arbitrary SR, which consists of multiple scale-aware feature adaption blocks and a scale-aware upsampling layer. Moreover, we introduce a scale-aware knowledge transfer paradigm to transfer knowledge from scale-specific networks to the scale-arbitrary network. Our plug-in module can be easily adapted to existing networks to achieve scale-arbitrary SR. These networks plugged with our module can achieve promising results for non-integer and asymmetric SR while maintaining state-of-the-art performance for SR with integer scale factors. Besides, the additional computational and memory cost of our module is very small.
Deformable 3D Convolution for Video Super-Resolution
Apr 06, 2020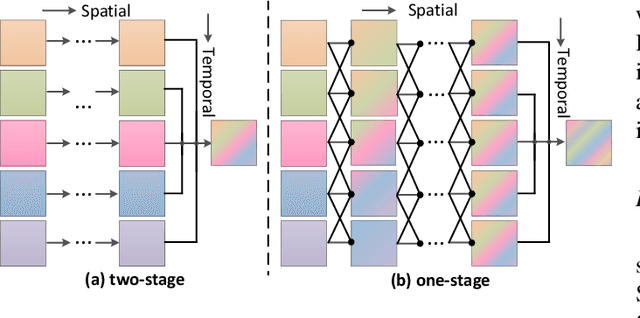
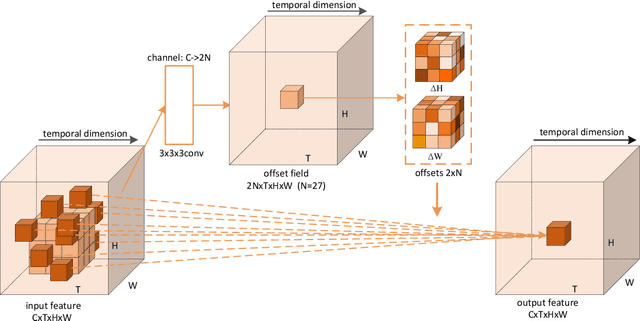
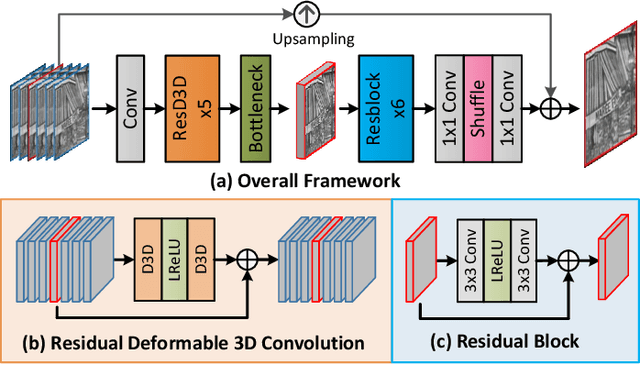
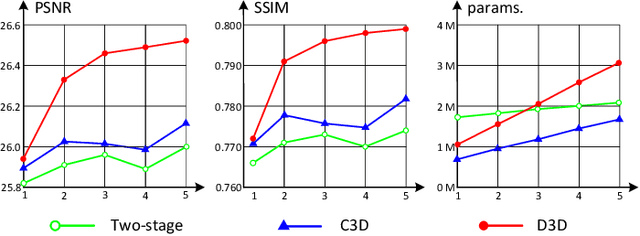
The spatio-temporal information among video sequences is significant for video super-resolution (SR). However, the spatio-temporal information cannot be fully used by existing video SR methods since spatial feature extraction and temporal motion compensation are usually performed sequentially. In this paper, we propose a deformable 3D convolution network (D3Dnet) to incorporate spatio-temporal information from both spatial and temporal dimensions for video SR. Specifically, we introduce deformable 3D convolutions (D3D) to integrate 2D spatial deformable convolutions with 3D convolutions (C3D), obtaining both superior spatio-temporal modeling capability and motion-aware modeling flexibility. Extensive experiments have demonstrated the effectiveness of our proposed D3D in exploiting spatio-temporal information. Comparative results show that our network outperforms the state-of-the-art methods. Code is available at: https://github.com/XinyiYing/D3Dnet.
Spatial-Angular Interaction for Light Field Image Super-Resolution
Dec 17, 2019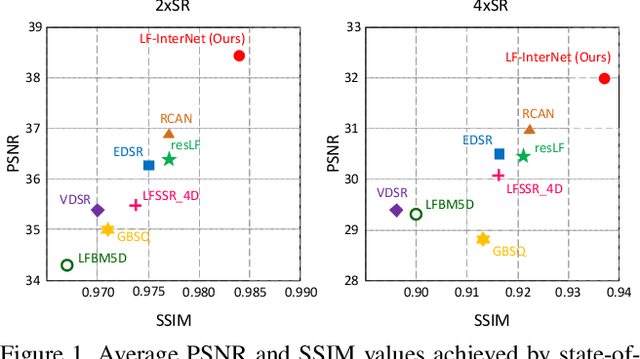
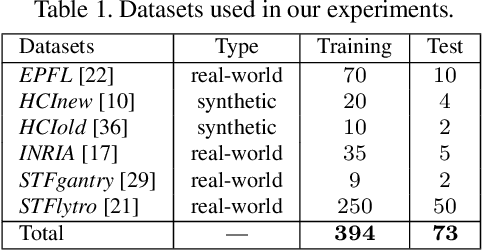
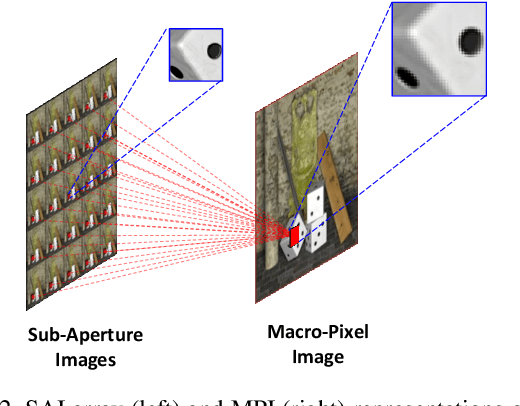
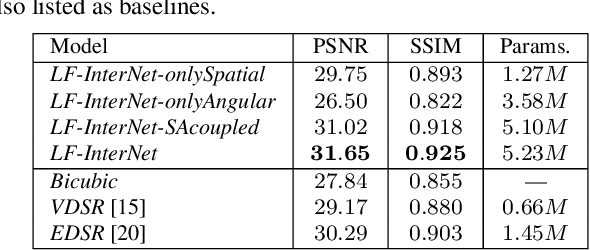
Light field (LF) cameras record both intensity and directions of light rays, and capture scenes from a number of viewpoints. Both information within each perspective (i.e., spatial information) and among different perspectives (i.e., angular information) is beneficial to image super-resolution (SR). In this paper, we propose a spatial-angular interactive network (namely, LF-InterNet) for LF image SR. In our method, spatial and angular features are separately extracted from the input LF using two specifically designed convolutions. These extracted features are then repetitively interacted to incorporate both spatial and angular information. Finally, the interacted spatial and angular features are fused to super-resolve each sub-aperture image. Experiments on 6 public LF datasets have demonstrated the superiority of our method. As compared to existing LF and single image SR methods, our method can recover much more details, and achieves significant improvements over the state-of-the-arts in terms of PSNR and SSIM.
DeOccNet: Learning to See Through Foreground Occlusions in Light Fields
Dec 10, 2019
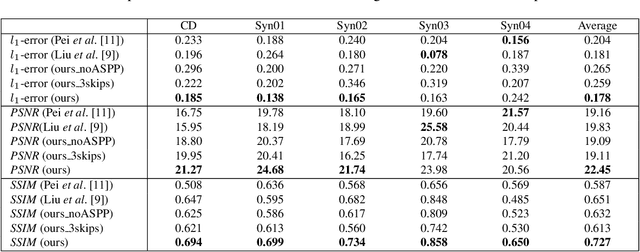
Background objects occluded in some views of a light field (LF) camera can be seen by other views. Consequently, occluded surfaces are possible to be reconstructed from LF images. In this paper, we handle the LF de-occlusion (LF-DeOcc) problem using a deep encoder-decoder network (namely, DeOccNet). In our method, sub-aperture images (SAIs) are first given to the encoder to incorporate both spatial and angular information. The encoded representations are then used by the decoder to render an occlusionfree center-view SAI. To the best of our knowledge, DeOccNet is the first deep learning-based LF-DeOcc method. To handle the insufficiency of training data, we propose an LF synthesis approach to embed selected occlusion masks into existing LF images. Besides, several synthetic and realworld LFs are developed for performance evaluation. Experimental results show that, after training on the generated data, our DeOccNet can effectively remove foreground occlusions and achieves superior performance as compared to other state-of-the-art methods. Source codes are available at: https://github.com/YingqianWang/DeOccNet.
Learning Parallax Attention for Stereo Image Super-Resolution
Mar 19, 2019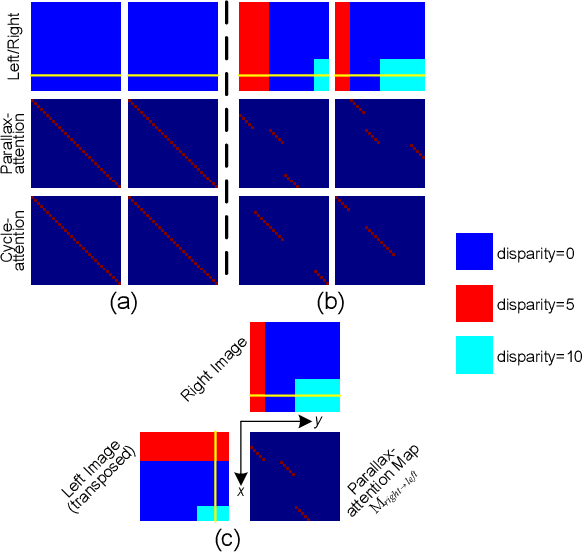
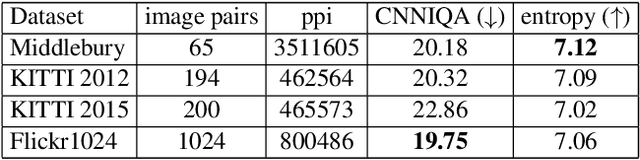
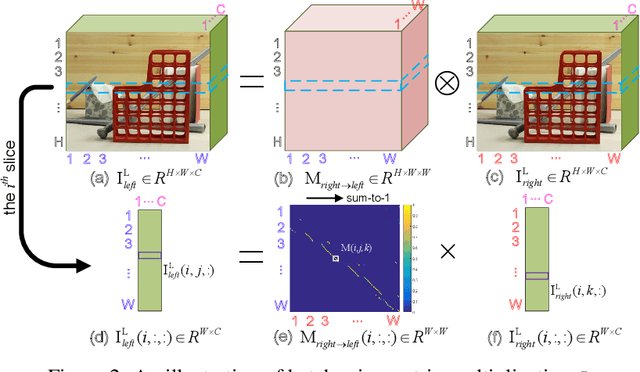
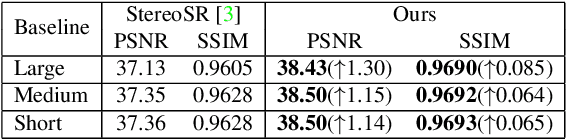
Stereo image pairs can be used to improve the performance of super-resolution (SR) since additional information is provided from a second viewpoint. However, it is challenging to incorporate this information for SR since disparities between stereo images vary significantly. In this paper, we propose a parallax-attention stereo superresolution network (PASSRnet) to integrate the information from a stereo image pair for SR. Specifically, we introduce a parallax-attention mechanism with a global receptive field along the epipolar line to handle different stereo images with large disparity variations. We also propose a new and the largest dataset for stereo image SR (namely, Flickr1024). Extensive experiments demonstrate that the parallax-attention mechanism can capture correspondence between stereo images to improve SR performance with a small computational and memory cost. Comparative results show that our PASSRnet achieves the state-of-the-art performance on the Middlebury, KITTI 2012 and KITTI 2015 datasets.