 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Utility of Model Explanations for Model Development
Dec 10, 2023



One of the motivations for explainable AI is to allow humans to make better and more informed decisions regarding the use and deployment of AI models. But careful evaluations are needed to assess whether this expectation has been fulfilled. Current evaluations mainly focus on algorithmic properties of explanations, and those that involve human subjects often employ subjective questions to test human's perception of explanation usefulness, without being grounded in objective metrics and measurements. In this work, we evaluate whether explanations can improve human decision-making in practical scenarios of machine learning model development. We conduct a mixed-methods user study involving image data to evaluate saliency maps generated by SmoothGrad, GradCAM, and an oracle explanation on two tasks: model selection and counterfactual simulation. To our surprise, we did not find evidence of significant improvement on these tasks when users were provided with any of the saliency maps, even the synthetic oracle explanation designed to be simple to understand and highly indicative of the answer. Nonetheless, explanations did help users more accurately describe the models. These findings suggest caution regarding the usefulness and potential for misunderstanding in saliency-based explanations.
Can Large Language Models Explain Themselves? A Study of LLM-Generated Self-Explanations
Oct 17, 2023



Large language models (LLMs) such as ChatGPT have demonstrated superior performance on a variety of natural language processing (NLP) tasks including sentiment analysis, mathematical reasoning and summarization. Furthermore, since these models are instruction-tuned on human conversations to produce "helpful" responses, they can and often will produce explanations along with the response, which we call self-explanations. For example, when analyzing the sentiment of a movie review, the model may output not only the positivity of the sentiment, but also an explanation (e.g., by listing the sentiment-laden words such as "fantastic" and "memorable" in the review). How good are these automatically generated self-explanations? In this paper, we investigate this question on the task of sentiment analysis and for feature attribution explanation, one of the most commonly studied settings in the interpretability literature (for pre-ChatGPT models). Specifically, we study different ways to elicit the self-explanations, evaluate their faithfulness on a set of evaluation metrics, and compare them to traditional explanation methods such as occlusion or LIME saliency maps. Through an extensive set of experiments, we find that ChatGPT's self-explanations perform on par with traditional ones, but are quite different from them according to various agreement metrics, meanwhile being much cheaper to produce (as they are generated along with the prediction). In addition, we identified several interesting characteristics of them, which prompt us to rethink many current model interpretability practices in the era of ChatGPT(-like) LLMs.
Improving Generalization in Language Model-Based Text-to-SQL Semantic Parsing: Two Simple Semantic Boundary-Based Techniques
May 27, 2023Compositional and domain generalization present significant challenges in semantic parsing, even for state-of-the-art semantic parsers based on pre-trained language models (LMs). In this study, we empirically investigate improving an LM's generalization in semantic parsing with two simple techniques: at the token level, we introduce a token preprocessing method to preserve the semantic boundaries of tokens produced by LM tokenizers; at the sequence level, we propose to use special tokens to mark the boundaries of components aligned between input and output. Our experimental results on two text-to-SQL semantic parsing datasets show that our token preprocessing, although simple, can substantially improve the LM performance on both types of generalization, and our component boundary marking method is particularly helpful for compositional generalization.
Iterative Partial Fulfillment of Counterfactual Explanations: Benefits and Risks
Mar 17, 2023Counterfactual (CF) explanations, also known as contrastive explanations and recourses, are popular for explaining machine learning model predictions in high-stakes domains. For a subject that receives a negative model prediction (e.g., mortgage application denial), they are similar instances but with positive predictions, which informs the subject of ways to improve. Various properties of CF explanations have been studied, such as validity, feasibility and stability. In this paper, we contribute a novel aspect: their behaviors under iterative partial fulfillment (IPF). Specifically, upon receiving a CF explanation, the subject may only partially fulfills it before requesting a new prediction with a new explanation, and repeat until the prediction is positive. Such partial fulfillment could be due to the subject's limited capability (e.g., can only pay down two out of four credit card accounts at this moment) or an attempt to take the chance (e.g., betting that a monthly salary increase of \$800 is enough even though \$1,000 is recommended). Does such iterative partial fulfillment increase or decrease the total cost of improvement incurred by the subject? We first propose a mathematical formalization of IPF and then demonstrate, both theoretically and empirically, that different CF algorithms exhibit vastly different behaviors under IPF and hence different effects on the subject's welfare, warranting this factor to be considered in the studies of CF algorithms. We discuss implications of our observations and give several directions for future work.
Explaining Large Language Model-Based Neural Semantic Parsers (Student Abstract)
Jan 25, 2023While large language models (LLMs) have demonstrated strong capability in structured prediction tasks such as semantic parsing, few amounts of research have explored the underlying mechanisms of their success. Our work studies different methods for explaining an LLM-based semantic parser and qualitatively discusses the explained model behaviors, hoping to inspire future research toward better understanding them.
The Solvability of Interpretability Evaluation Metrics
May 18, 2022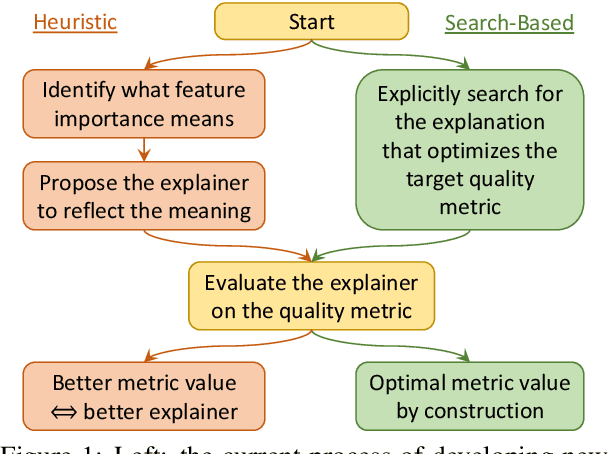
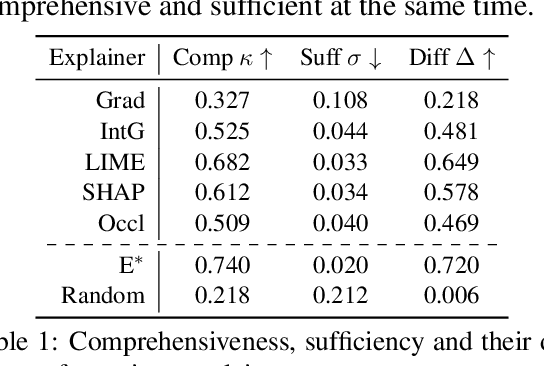

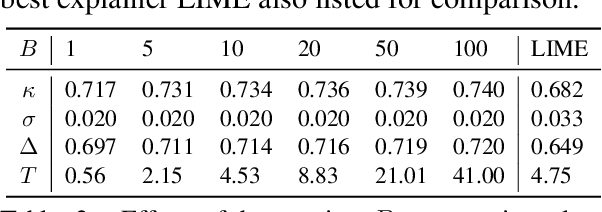
Feature attribution methods are popular for explaining neural network predictions, and they are often evaluated on metrics such as comprehensiveness and sufficiency, which are motivated by the principle that more important features -- as judged by the explanation -- should have larger impacts on model prediction. In this paper, we highlight an intriguing property of these metrics: their solvability. Concretely, we can define the problem of optimizing an explanation for a metric and solve it using beam search. This brings up the obvious question: given such solvability, why do we still develop other explainers and then evaluate them on the metric? We present a series of investigations showing that this beam search explainer is generally comparable or favorable to current choices such as LIME and SHAP, suggest rethinking the goals of model interpretability, and identify several directions towards better evaluations of new method proposals.
ExSum: From Local Explanations to Model Understanding
Apr 30, 2022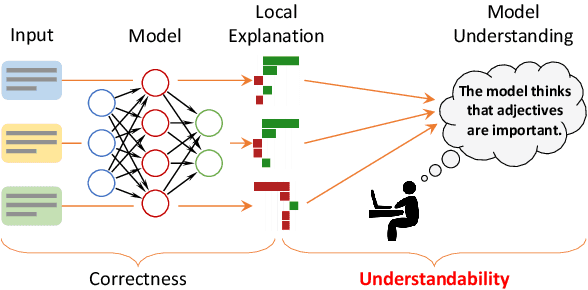
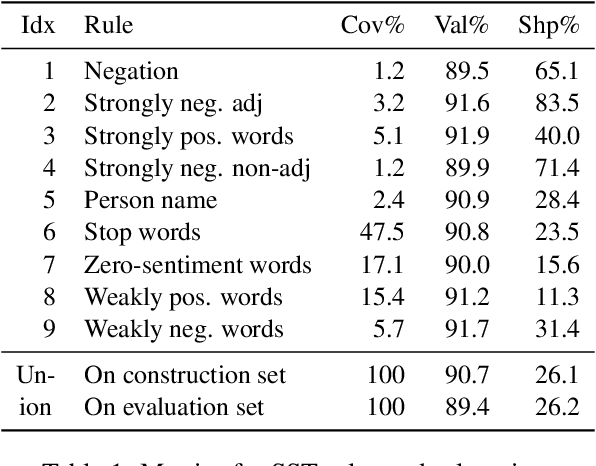
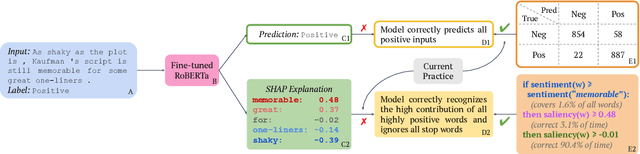
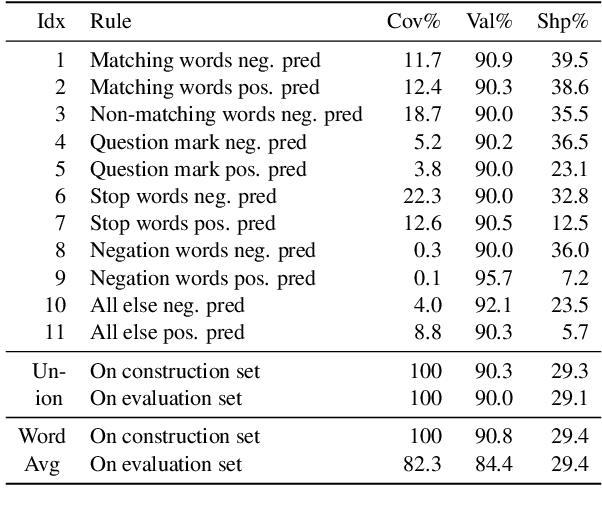
Interpretability methods are developed to understand the working mechanisms of black-box models, which is crucial to their responsible deployment. Fulfilling this goal requires both that the explanations generated by these methods are correct and that people can easily and reliably understand them. While the former has been addressed in prior work, the latter is often overlooked, resulting in informal model understanding derived from a handful of local explanations. In this paper, we introduce explanation summary (ExSum), a mathematical framework for quantifying model understanding, and propose metrics for its quality assessment. On two domains, ExSum highlights various limitations in the current practice, helps develop accurate model understanding, and reveals easily overlooked properties of the model. We also connect understandability to other properties of explanations such as human alignment, robustness, and counterfactual minimality and plausibility.
The Irrationality of Neural Rationale Models
Oct 14, 2021



Neural rationale models are popular for interpretable predictions of NLP tasks. In these, a selector extracts segments of the input text, called rationales, and passes these segments to a classifier for prediction. Since the rationale is the only information accessible to the classifier, it is plausibly defined as the explanation. Is such a characterization unconditionally correct? In this paper, we argue to the contrary, with both philosophical perspectives and empirical evidence suggesting that rationale models are, perhaps, less rational and interpretable than expected. We call for more rigorous and comprehensive evaluations of these models to ensure desired properties of interpretability are indeed achieved. The code can be found at https://github.com/yimingz89/Neural-Rationale-Analysis.
Do Feature Attribution Methods Correctly Attribute Features?
Apr 27, 2021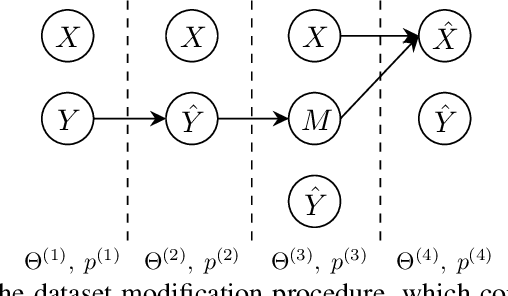

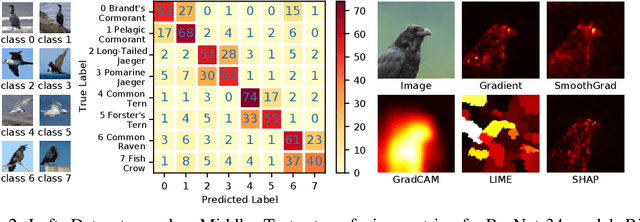
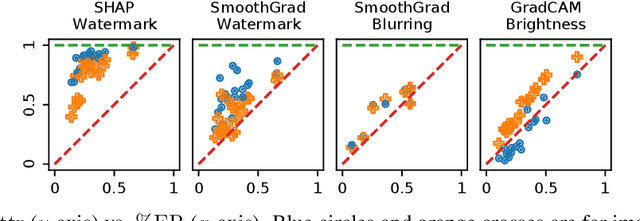
Feature attribution methods are exceedingly popular in interpretable machine learning. They aim to compute the attribution of each input feature to represent its importance, but there is no consensus on the definition of "attribution", leading to many competing methods with little systematic evaluation. The lack of attribution ground truth further complicates evaluation, which has to rely on proxy metrics. To address this, we propose a dataset modification procedure such that models trained on the new dataset have ground truth attribution available. We evaluate three methods: saliency maps, rationales, and attention. We identify their deficiencies and add a new perspective to the growing body of evidence questioning their correctness and reliability in the wild. Our evaluation approach is model-agnostic and can be used to assess future feature attribution method proposals as well. Code is available at https://github.com/YilunZhou/feature-attribution-evaluation.
State-Visitation Fairness in Average-Reward MDPs
Mar 02, 2021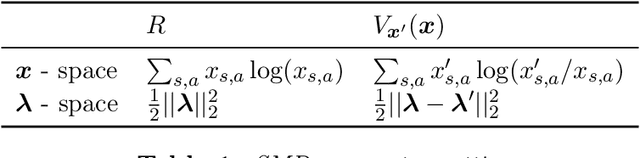
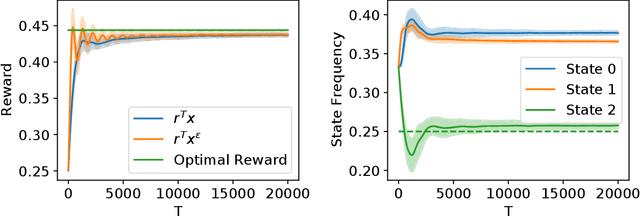
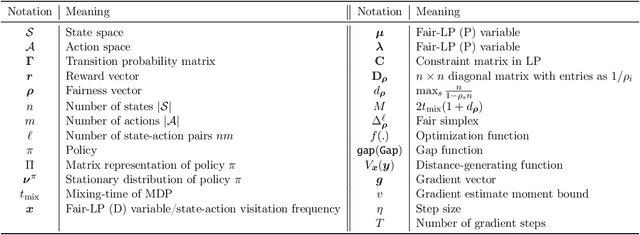
Fairness has emerged as an important concern in automated decision-making in recent years, especially when these decisions affect human welfare. In this work, we study fairness in temporally extended decision-making settings, specifically those formulated as Markov Decision Processes (MDPs). Our proposed notion of fairness ensures that each state's long-term visitation frequency is more than a specified fraction. In an average-reward MDP (AMDP) setting, we formulate the problem as a bilinear saddle point program and, for a generative model, solve it using a Stochastic Mirror Descent (SMD) based algorithm. The proposed solution guarantees a simultaneous approximation on the expected average-reward and the long-term state-visitation frequency. We validate our theoretical results with experiments on synthetic data.