 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnpaired Cross-lingual Image Caption Generation with Self-Supervised Rewards
Aug 15, 2019
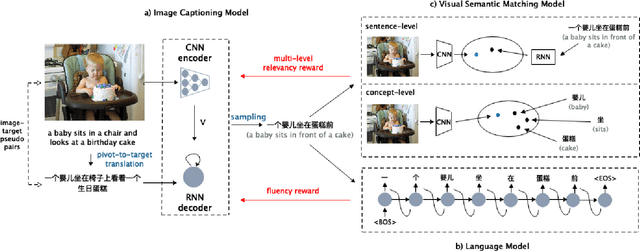
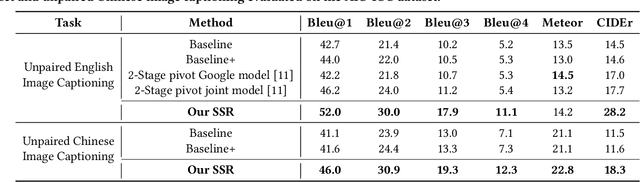
Generating image descriptions in different languages is essential to satisfy users worldwide. However, it is prohibitively expensive to collect large-scale paired image-caption dataset for every target language which is critical for training descent image captioning models. Previous works tackle the unpaired cross-lingual image captioning problem through a pivot language, which is with the help of paired image-caption data in the pivot language and pivot-to-target machine translation models. However, such language-pivoted approach suffers from inaccuracy brought by the pivot-to-target translation, including disfluency and visual irrelevancy errors. In this paper, we propose to generate cross-lingual image captions with self-supervised rewards in the reinforcement learning framework to alleviate these two types of errors. We employ self-supervision from mono-lingual corpus in the target language to provide fluency reward, and propose a multi-level visual semantic matching model to provide both sentence-level and concept-level visual relevancy rewards. We conduct extensive experiments for unpaired cross-lingual image captioning in both English and Chinese respectively on two widely used image caption corpora. The proposed approach achieves significant performance improvement over state-of-the-art methods.
Activitynet 2019 Task 3: Exploring Contexts for Dense Captioning Events in Videos
Jul 11, 2019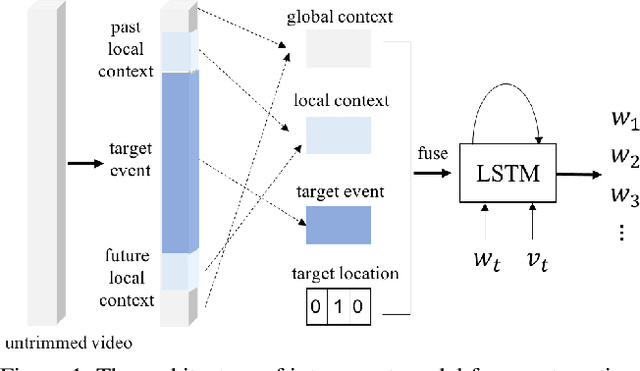
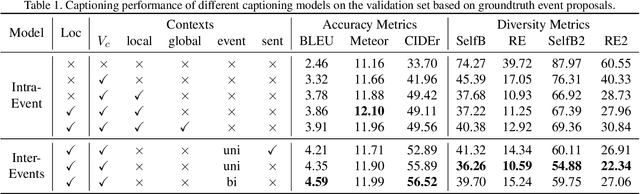
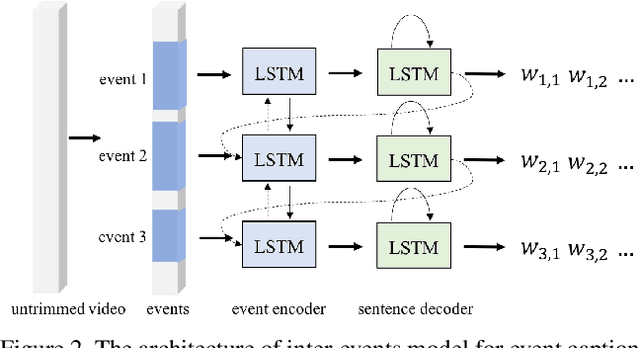
Contextual reasoning is essential to understand events in long untrimmed videos. In this work, we systematically explore different captioning models with various contexts for the dense-captioning events in video task, which aims to generate captions for different events in the untrimmed video. We propose five types of contexts as well as two categories of event captioning models, and evaluate their contributions for event captioning from both accuracy and diversity aspects. The proposed captioning models are plugged into our pipeline system for the dense video captioning challenge. The overall system achieves the state-of-the-art performance on the dense-captioning events in video task with 9.91 METEOR score on the challenge testing set.
RUC+CMU: System Report for Dense Captioning Events in Videos
Jun 22, 2018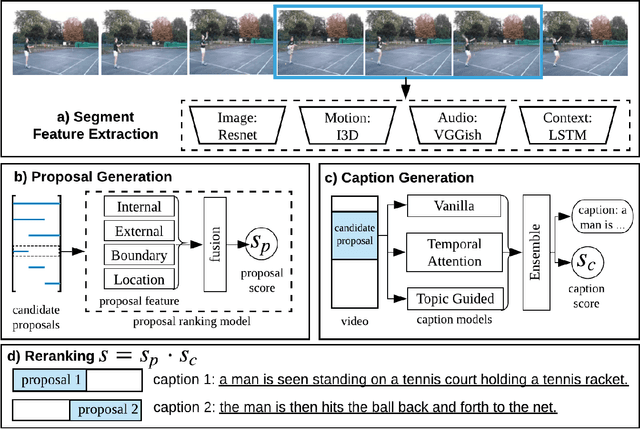
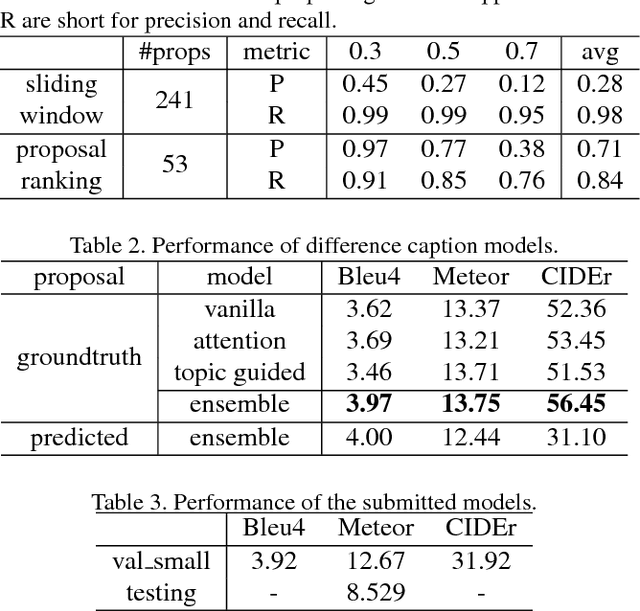
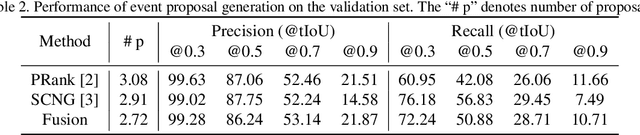
This notebook paper presents our system in the ActivityNet Dense Captioning in Video task (task 3). Temporal proposal generation and caption generation are both important to the dense captioning task. Therefore, we propose a proposal ranking model to employ a set of effective feature representations for proposal generation, and ensemble a series of caption models enhanced with context information to generate captions robustly on predicted proposals. Our approach achieves the state-of-the-art performance on the dense video captioning task with 8.529 METEOR score on the challenge testing set.