 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMidiBERT-Piano: Large-scale Pre-training for Symbolic Music Understanding
Jul 12, 2021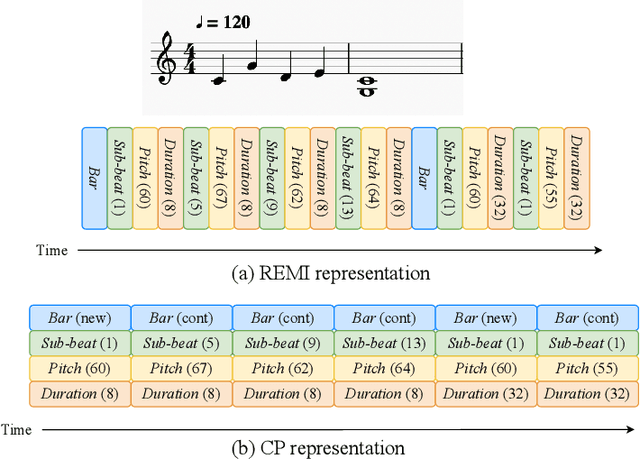
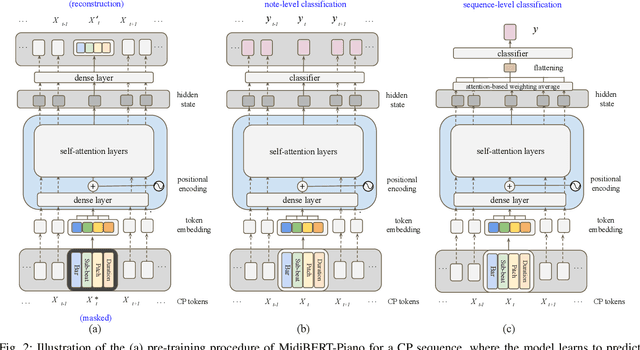
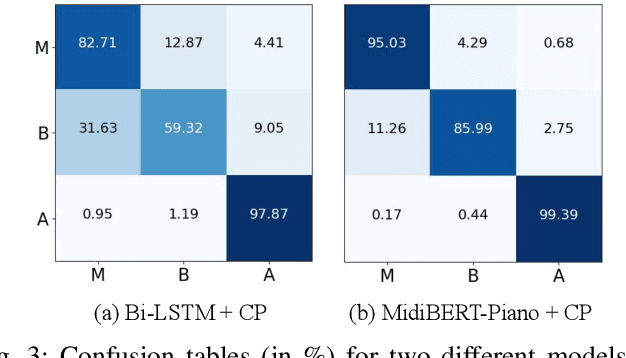
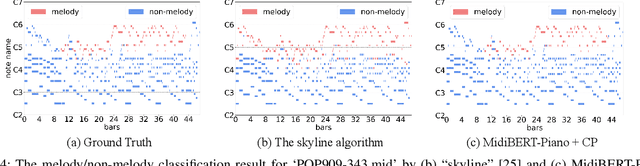
This paper presents an attempt to employ the mask language modeling approach of BERT to pre-train a 12-layer Transformer model over 4,166 pieces of polyphonic piano MIDI files for tackling a number of symbolic-domain discriminative music understanding tasks. These include two note-level classification tasks, i.e., melody extraction and velocity prediction, as well as two sequence-level classification tasks, i.e., composer classification and emotion classification. We find that, given a pre-trained Transformer, our models outperform recurrent neural network based baselines with less than 10 epochs of fine-tuning. Ablation studies show that the pre-training remains effective even if none of the MIDI data of the downstream tasks are seen at the pre-training stage, and that freezing the self-attention layers of the Transformer at the fine-tuning stage slightly degrades performance. All the five datasets employed in this work are publicly available, as well as checkpoints of our pre-trained and fine-tuned models. As such, our research can be taken as a benchmark for symbolic-domain music understanding.
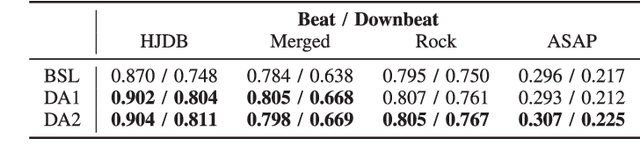
Source Separation-based Data Augmentation for Improved Joint Beat and Downbeat Tracking
Jun 16, 2021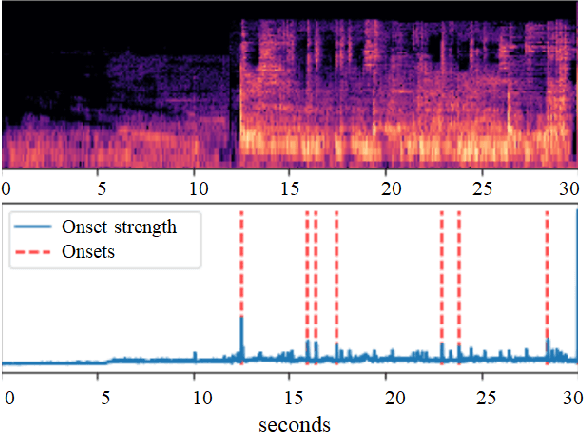
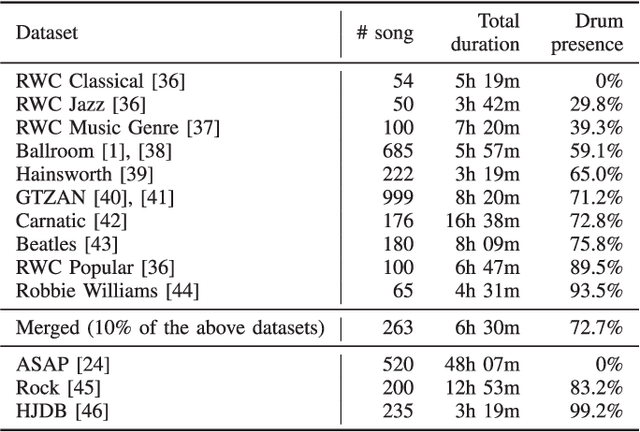
Due to advances in deep learning, the performance of automatic beat and downbeat tracking in musical audio signals has seen great improvement in recent years. In training such deep learning based models, data augmentation has been found an important technique. However, existing data augmentation methods for this task mainly target at balancing the distribution of the training data with respect to their tempo. In this paper, we investigate another approach for data augmentation, to account for the composition of the training data in terms of the percussive and non-percussive sound sources. Specifically, we propose to employ a blind drum separation model to segregate the drum and non-drum sounds from each training audio signal, filtering out training signals that are drumless, and then use the obtained drum and non-drum stems to augment the training data. We report experiments on four completely unseen test sets, validating the effectiveness of the proposed method, and accordingly the importance of drum sound composition in the training data for beat and downbeat tracking.
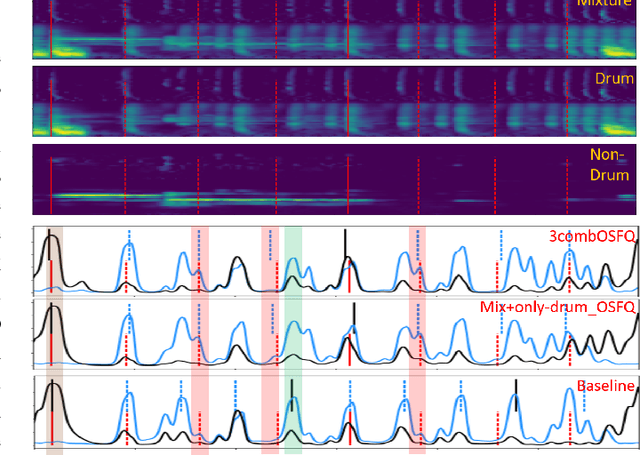
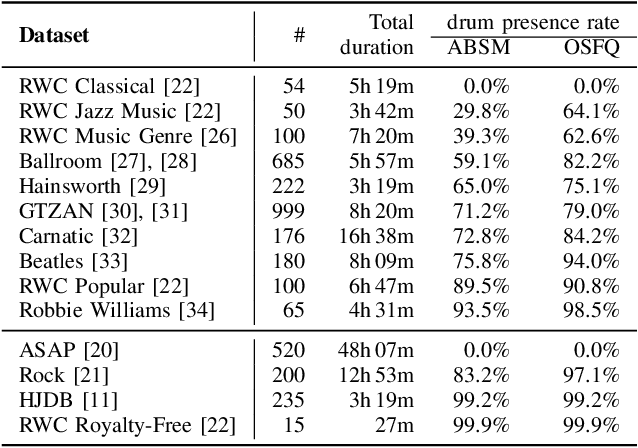
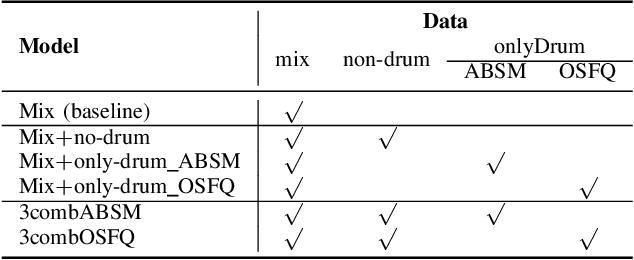
Drum-Aware Ensemble Architecture for Improved Joint Musical Beat and Downbeat Tracking
Jun 16, 2021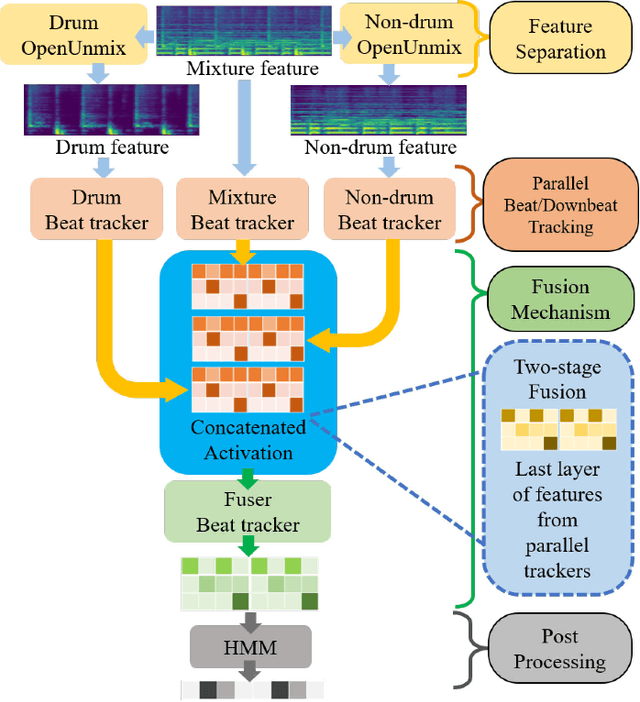
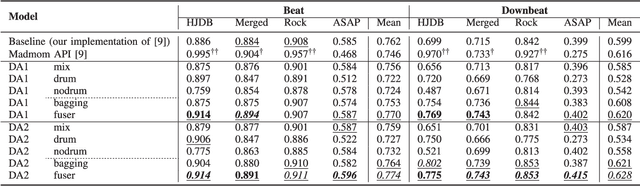
This paper presents a novel system architecture that integrates blind source separation with joint beat and downbeat tracking in musical audio signals. The source separation module segregates the percussive and non-percussive components of the input signal, over which beat and downbeat tracking are performed separately and then the results are aggregated with a learnable fusion mechanism. This way, the system can adaptively determine how much the tracking result for an input signal should depend on the input's percussive or non-percussive components. Evaluation on four testing sets that feature different levels of presence of drum sounds shows that the new architecture consistently outperforms the widely-adopted baseline architecture that does not employ source separation.
Relative Positional Encoding for Transformers with Linear Complexity
Jun 10, 2021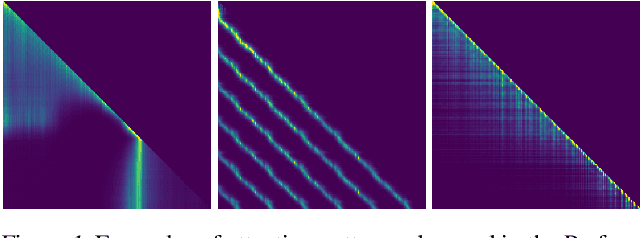
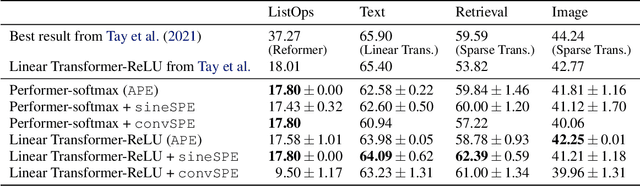

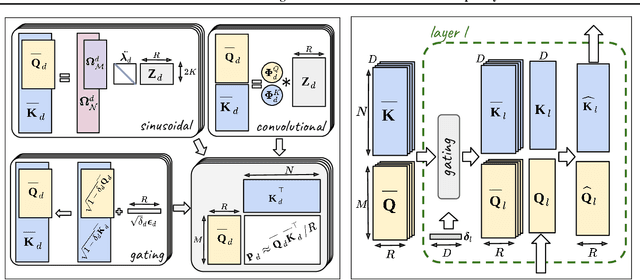
Recent advances in Transformer models allow for unprecedented sequence lengths, due to linear space and time complexity. In the meantime, relative positional encoding (RPE) was proposed as beneficial for classical Transformers and consists in exploiting lags instead of absolute positions for inference. Still, RPE is not available for the recent linear-variants of the Transformer, because it requires the explicit computation of the attention matrix, which is precisely what is avoided by such methods. In this paper, we bridge this gap and present Stochastic Positional Encoding as a way to generate PE that can be used as a replacement to the classical additive (sinusoidal) PE and provably behaves like RPE. The main theoretical contribution is to make a connection between positional encoding and cross-covariance structures of correlated Gaussian processes. We illustrate the performance of our approach on the Long-Range Arena benchmark and on music generation.
MuseMorphose: Full-Song and Fine-Grained Music Style Transfer with Just One Transformer VAE
May 10, 2021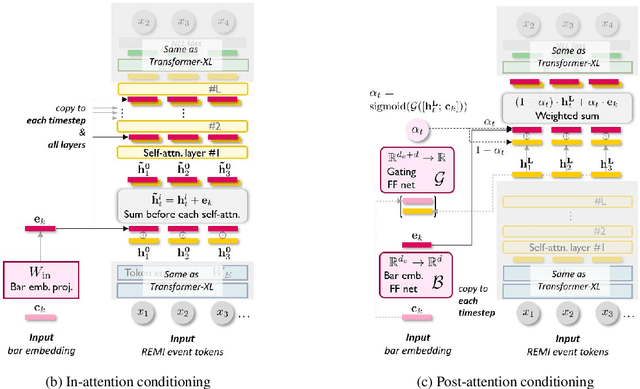

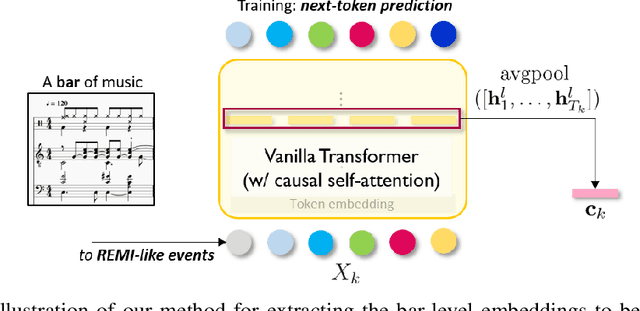

Transformers and variational autoencoders (VAE) have been extensively employed for symbolic (e.g., MIDI) domain music generation. While the former boast an impressive capability in modeling long sequences, the latter allow users to willingly exert control over different parts (e.g., bars) of the music to be generated. In this paper, we are interested in bringing the two together to construct a single model that exhibits both strengths. The task is split into two steps. First, we equip Transformer decoders with the ability to accept segment-level, time-varying conditions during sequence generation. Subsequently, we combine the developed and tested in-attention decoder with a Transformer encoder, and train the resulting MuseMorphose model with the VAE objective to achieve style transfer of long musical pieces, in which users can specify musical attributes including rhythmic intensity and polyphony (i.e., harmonic fullness) they desire, down to the bar level. Experiments show that MuseMorphose outperforms recurrent neural network (RNN) based prior art on numerous widely-used metrics for style transfer tasks.
Compound Word Transformer: Learning to Compose Full-Song Music over Dynamic Directed Hypergraphs
Jan 07, 2021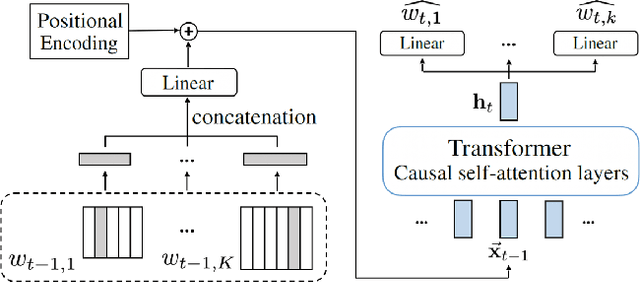
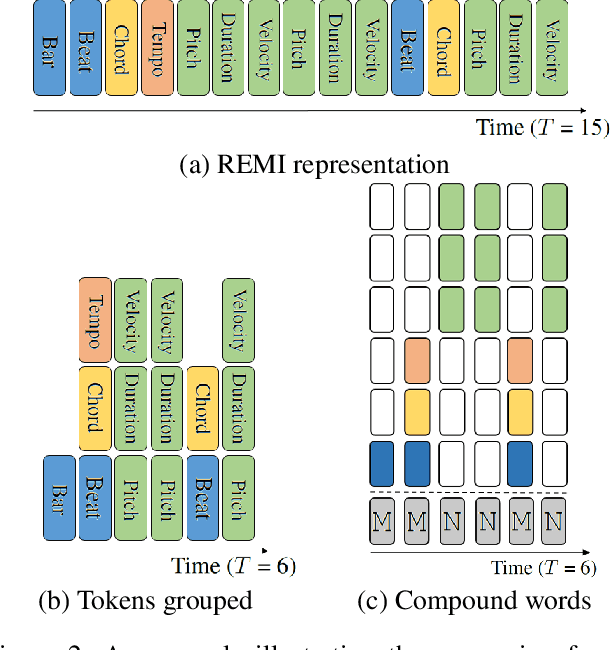

To apply neural sequence models such as the Transformers to music generation tasks, one has to represent a piece of music by a sequence of tokens drawn from a finite set of pre-defined vocabulary. Such a vocabulary usually involves tokens of various types. For example, to describe a musical note, one needs separate tokens to indicate the note's pitch, duration, velocity (dynamics), and placement (onset time) along the time grid. While different types of tokens may possess different properties, existing models usually treat them equally, in the same way as modeling words in natural languages. In this paper, we present a conceptually different approach that explicitly takes into account the type of the tokens, such as note types and metric types. And, we propose a new Transformer decoder architecture that uses different feed-forward heads to model tokens of different types. With an expansion-compression trick, we convert a piece of music to a sequence of compound words by grouping neighboring tokens, greatly reducing the length of the token sequences. We show that the resulting model can be viewed as a learner over dynamic directed hypergraphs. And, we employ it to learn to compose expressive Pop piano music of full-song length (involving up to 10K individual tokens per song), both conditionally and unconditionally. Our experiment shows that, compared to state-of-the-art models, the proposed model converges 5--10 times faster at training (i.e., within a day on a single GPU with 11 GB memory), and with comparable quality in the generated music.
Mixing-Specific Data Augmentation Techniques for Improved Blind Violin/Piano Source Separation
Aug 06, 2020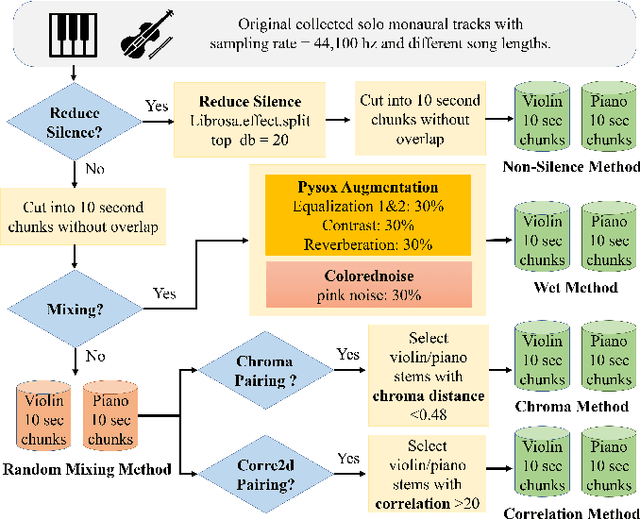
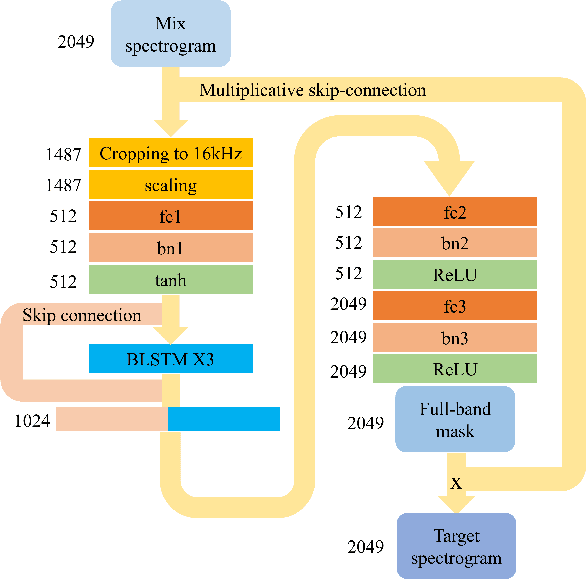
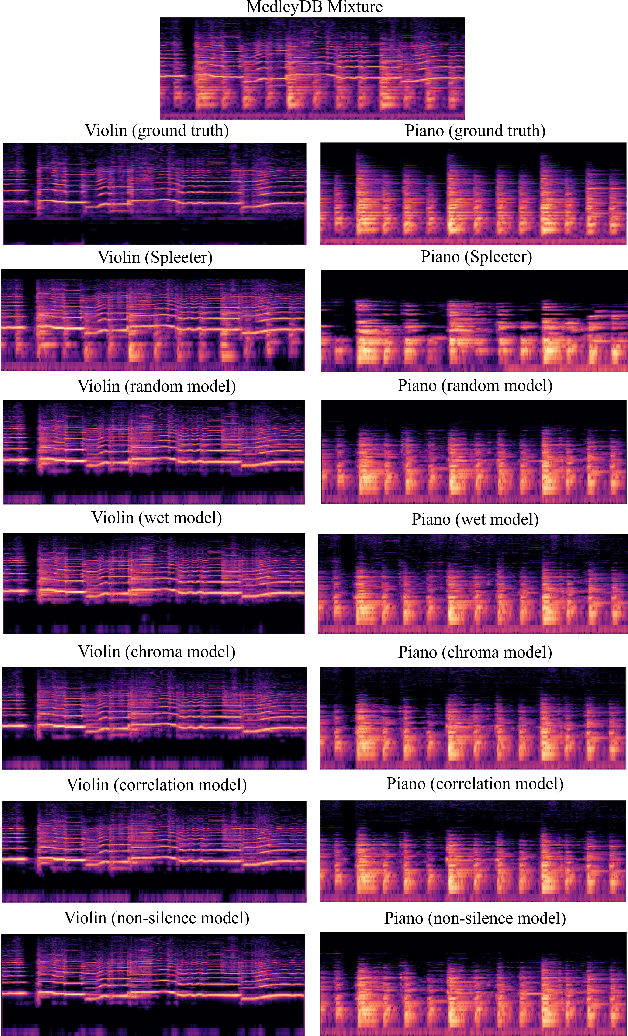
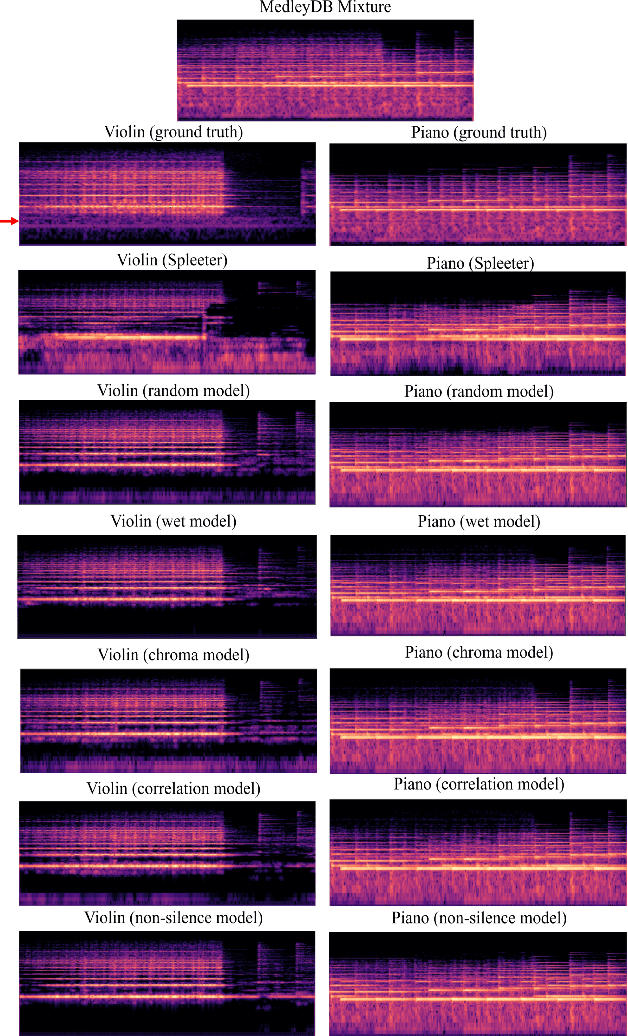
Blind music source separation has been a popular and active subject of research in both the music information retrieval and signal processing communities. To counter the lack of available multi-track data for supervised model training, a data augmentation method that creates artificial mixtures by combining tracks from different songs has been shown useful in recent works. Following this light, we examine further in this paper extended data augmentation methods that consider more sophisticated mixing settings employed in the modern music production routine, the relationship between the tracks to be combined, and factors of silence. As a case study, we consider the separation of violin and piano tracks in a violin piano ensemble, evaluating the performance in terms of common metrics, namely SDR, SIR, and SAR. In addition to examining the effectiveness of these new data augmentation methods, we also study the influence of the amount of training data. Our evaluation shows that the proposed mixing-specific data augmentation methods can help improve the performance of a deep learning-based model for source separation, especially in the case of small training data.
Neural Loop Combiner: Neural Network Models for Assessing the Compatibility of Loops
Aug 05, 2020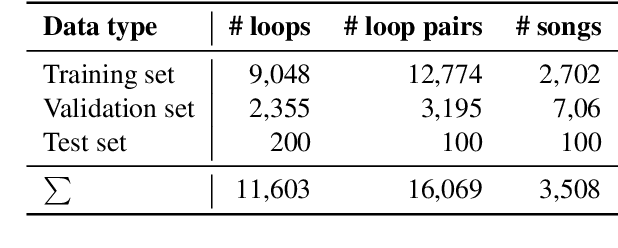
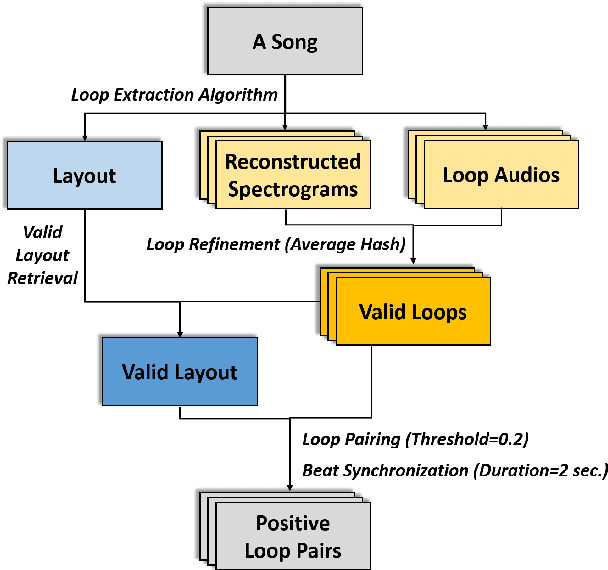
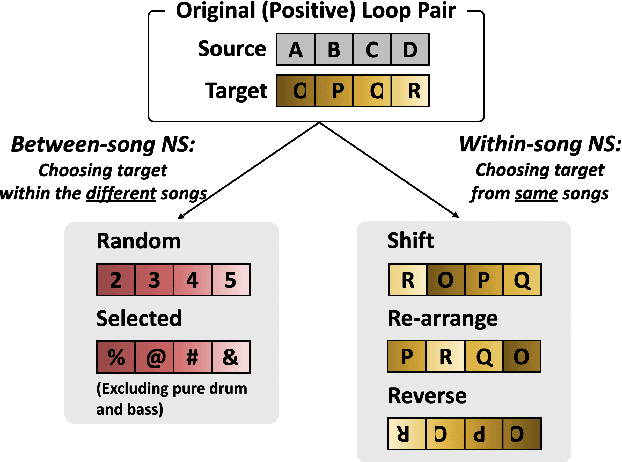
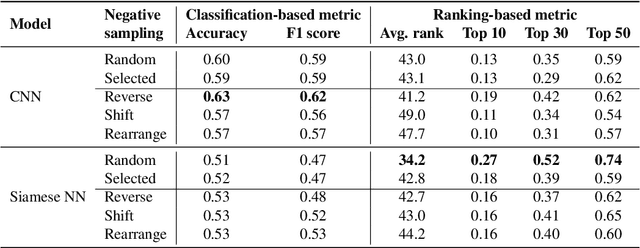
Music producers who use loops may have access to thousands in loop libraries, but finding ones that are compatible is a time-consuming process; we hope to reduce this burden with automation. State-of-the-art systems for estimating compatibility, such as AutoMashUpper, are mostly rule-based and could be improved on with machine learning. To train a model, we need a large set of loops with ground truth compatibility values. No such dataset exists, so we extract loops from existing music to obtain positive examples of compatible loops, and propose and compare various strategies for choosing negative examples. For reproducibility, we curate data from the Free Music Archive. Using this data, we investigate two types of model architectures for estimating the compatibility of loops: one based on a Siamese network, and the other a pure convolutional neural network (CNN). We conducted a user study in which participants rated the quality of the combinations suggested by each model, and found the CNN to outperform the Siamese network. Both model-based approaches outperformed the rule-based one. We have opened source the code for building the models and the dataset.
The Jazz Transformer on the Front Line: Exploring the Shortcomings of AI-composed Music through Quantitative Measures
Aug 04, 2020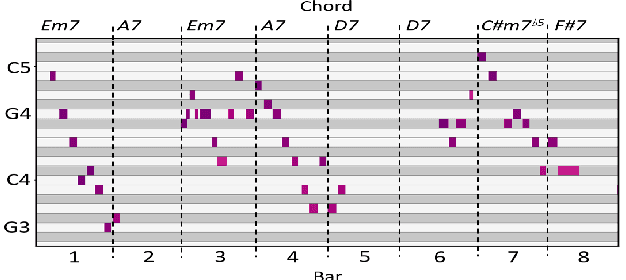
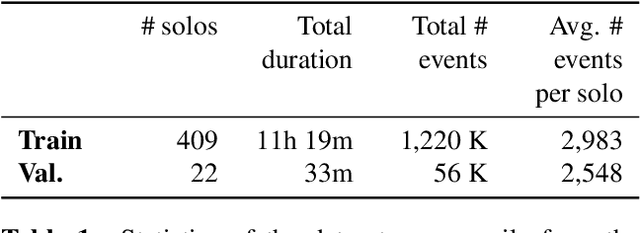
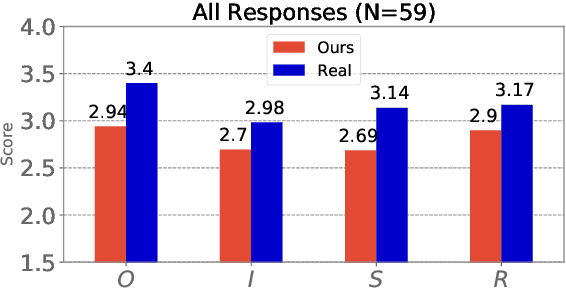
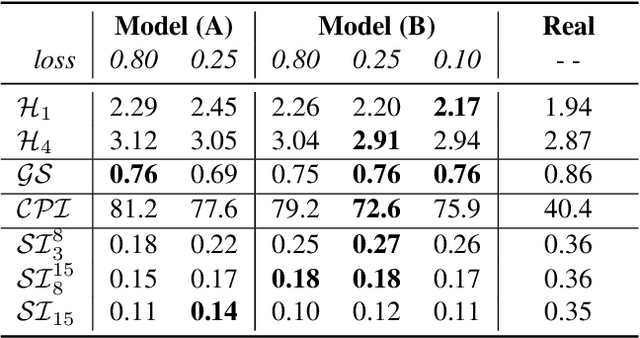
This paper presents the Jazz Transformer, a generative model that utilizes a neural sequence model called the Transformer-XL for modeling lead sheets of Jazz music. Moreover, the model endeavors to incorporate structural events present in the Weimar Jazz Database (WJazzD) for inducing structures in the generated music. While we are able to reduce the training loss to a low value, our listening test suggests however a clear gap between the average ratings of the generated and real compositions. We therefore go one step further and conduct a series of computational analysis of the generated compositions from different perspectives. This includes analyzing the statistics of the pitch class, grooving, and chord progression, assessing the structureness of the music with the help of the fitness scape plot, and evaluating the model's understanding of Jazz music through a MIREX-like continuation prediction task. Our work presents in an analytical manner why machine-generated music to date still falls short of the artwork of humanity, and sets some goals for future work on automatic composition to further pursue.
Speech-to-Singing Conversion based on Boundary Equilibrium GAN
May 30, 2020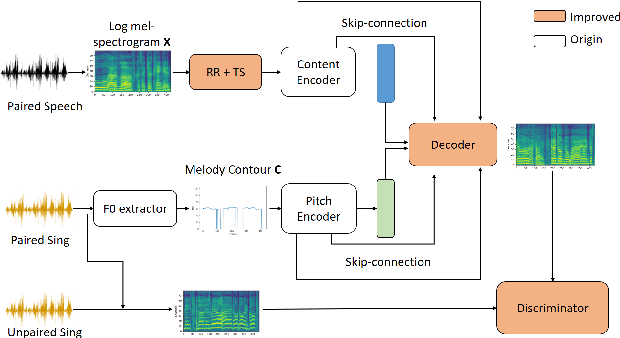
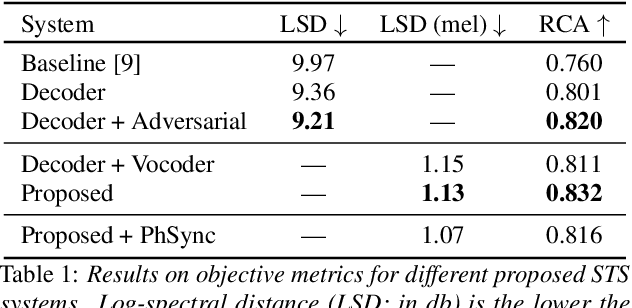
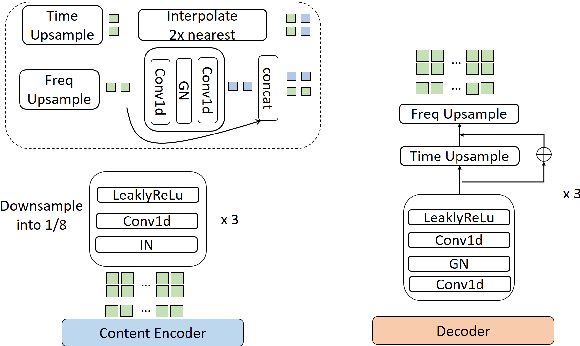
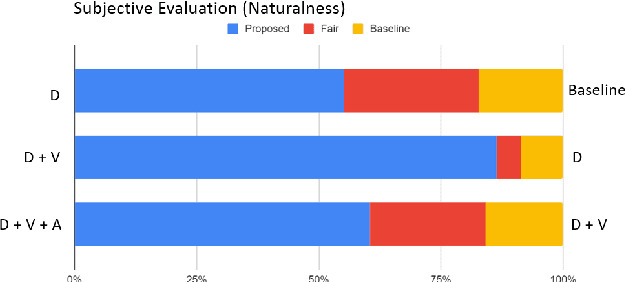
This paper investigates the use of generative adversarial network (GAN)-based models for converting the spectrogram of a speech signal into that of a singing one, without reference to the phoneme sequence underlying the speech. This is achieved by viewing speech-to-singing conversion as a style transfer problem. Specifically, given a speech input, and optionally the F0 contour of the target singing, the proposed model generates as the output a singing signal with a progressive-growing encoder/decoder architecture and boundary equilibrium GAN loss functions. Our quantitative and qualitative analysis show that the proposed model generates singing voices with much higher naturalness than an existing non adversarially-trained baseline. For reproducibility, the code will be publicly available at a GitHub repository upon paper publication.