 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Unsupervised Automatic Speech Recognition Trained by Unaligned Speech and Text only
Aug 11, 2018



Automatic speech recognition (ASR) has been widely researched with supervised approaches, while many low-resourced languages lack audio-text aligned data, and supervised methods cannot be applied on them. In this work, we propose a framework to achieve unsupervised ASR on a read English speech dataset, where audio and text are unaligned. In the first stage, each word-level audio segment in the utterances is represented by a vector representation extracted by a sequence-of-sequence autoencoder, in which phonetic information and speaker information are disentangled. Secondly, semantic embeddings of audio segments are trained from the vector representations using a skip-gram model. Last but not the least, an unsupervised method is utilized to transform semantic embeddings of audio segments to text embedding space, and finally the transformed embeddings are mapped to words. With the above framework, we are towards unsupervised ASR trained by unaligned text and speech only.
Order-Free RNN with Visual Attention for Multi-Label Classification
Dec 20, 2017


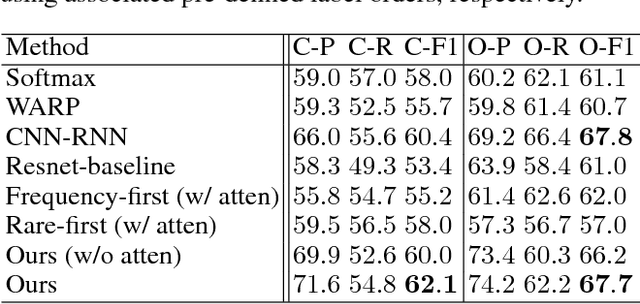
In this paper, we propose the joint learning attention and recurrent neural network (RNN) models for multi-label classification. While approaches based on the use of either model exist (e.g., for the task of image captioning), training such existing network architectures typically require pre-defined label sequences. For multi-label classification, it would be desirable to have a robust inference process, so that the prediction error would not propagate and thus affect the performance. Our proposed model uniquely integrates attention and Long Short Term Memory (LSTM) models, which not only addresses the above problem but also allows one to identify visual objects of interests with varying sizes without the prior knowledge of particular label ordering. More importantly, label co-occurrence information can be jointly exploited by our LSTM model. Finally, by advancing the technique of beam search, prediction of multiple labels can be efficiently achieved by our proposed network model.