 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCAN: Sliding Convolutional Attention Network for Scene Text Recognition
Jun 02, 2018
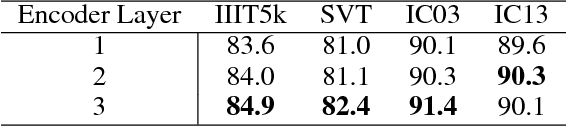
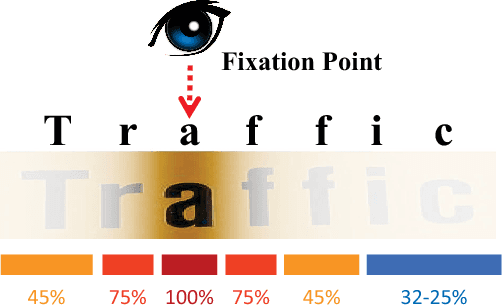
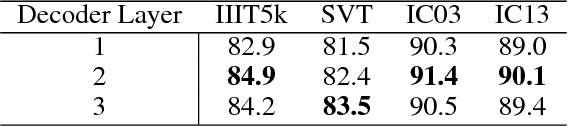
Scene text recognition has drawn great attentions in the community of computer vision and artificial intelligence due to its challenges and wide applications. State-of-the-art recurrent neural networks (RNN) based models map an input sequence to a variable length output sequence, but are usually applied in a black box manner and lack of transparency for further improvement, and the maintaining of the entire past hidden states prevents parallel computation in a sequence. In this paper, we investigate the intrinsic characteristics of text recognition, and inspired by human cognition mechanisms in reading texts, we propose a scene text recognition method with sliding convolutional attention network (SCAN). Similar to the eye movement during reading, the process of SCAN can be viewed as an alternation between saccades and visual fixations. Compared to the previous recurrent models, computations over all elements of SCAN can be fully parallelized during training. Experimental results on several challenging benchmarks, including the IIIT5k, SVT and ICDAR 2003/2013 datasets, demonstrate the superiority of SCAN over state-of-the-art methods in terms of both the model interpretability and performance.
Scene Text Recognition with Sliding Convolutional Character Models
Sep 06, 2017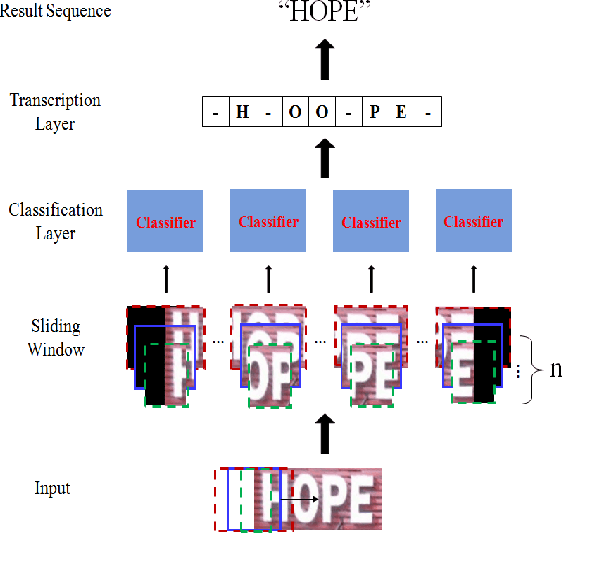
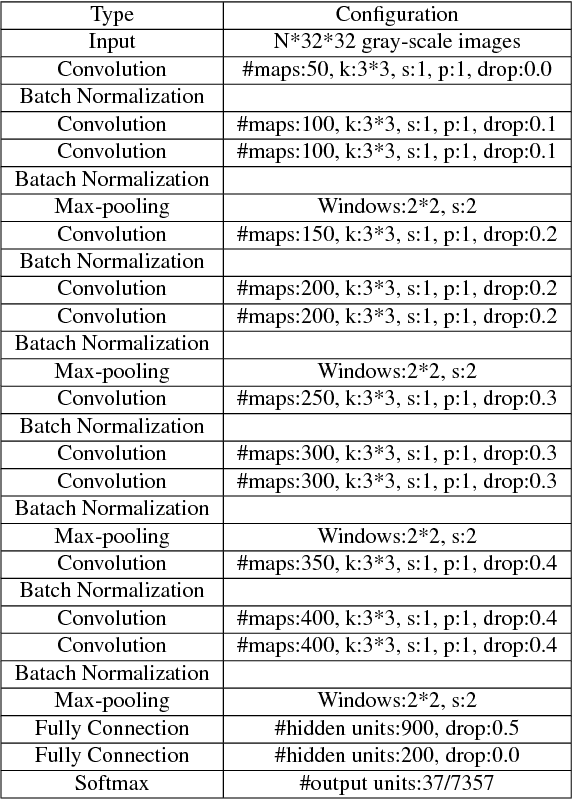

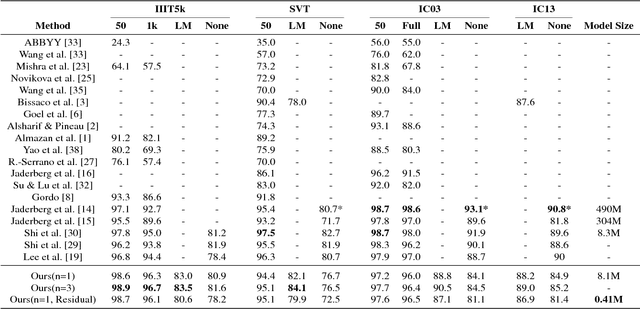
Scene text recognition has attracted great interests from the computer vision and pattern recognition community in recent years. State-of-the-art methods use concolutional neural networks (CNNs), recurrent neural networks with long short-term memory (RNN-LSTM) or the combination of them. In this paper, we investigate the intrinsic characteristics of text recognition, and inspired by human cognition mechanisms in reading texts, we propose a scene text recognition method with character models on convolutional feature map. The method simultaneously detects and recognizes characters by sliding the text line image with character models, which are learned end-to-end on text line images labeled with text transcripts. The character classifier outputs on the sliding windows are normalized and decoded with Connectionist Temporal Classification (CTC) based algorithm. Compared to previous methods, our method has a number of appealing properties: (1) It avoids the difficulty of character segmentation which hinders the performance of segmentation-based recognition methods; (2) The model can be trained simply and efficiently because it avoids gradient vanishing/exploding in training RNN-LSTM based models; (3) It bases on character models trained free of lexicon, and can recognize unknown words. (4) The recognition process is highly parallel and enables fast recognition. Our experiments on several challenging English and Chinese benchmarks, including the IIIT-5K, SVT, ICDAR03/13 and TRW15 datasets, demonstrate that the proposed method yields superior or comparable performance to state-of-the-art methods while the model size is relatively small.