 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructFormer: Joint Unsupervised Induction of Dependency and Constituency Structure from Masked Language Modeling
Dec 15, 2020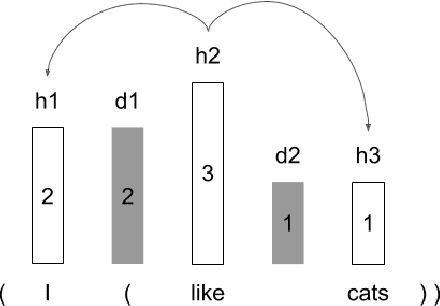

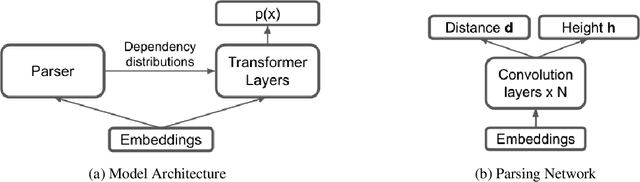
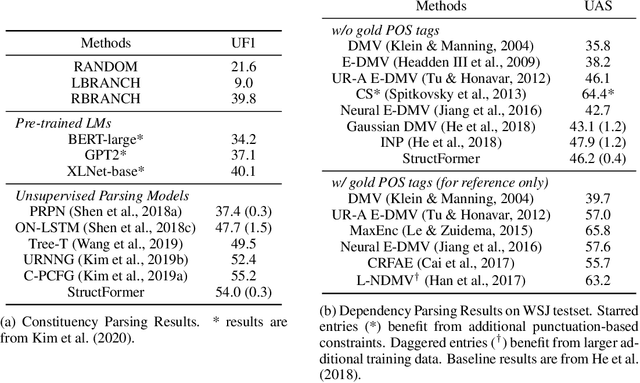
There are two major classes of natural language grammars -- the dependency grammar that models one-to-one correspondences between words and the constituency grammar that models the assembly of one or several corresponded words. While previous unsupervised parsing methods mostly focus on only inducing one class of grammars, we introduce a novel model, StructFormer, that can induce dependency and constituency structure at the same time. To achieve this, we propose a new parsing framework that can jointly generate a constituency tree and dependency graph. Then we integrate the induced dependency relations into the transformer, in a differentiable manner, through a novel dependency-constrained self-attention mechanism. Experimental results show that our model can achieve strong results on unsupervised constituency parsing, unsupervised dependency parsing, and masked language modeling at the same time.
Long Range Arena: A Benchmark for Efficient Transformers
Nov 08, 2020
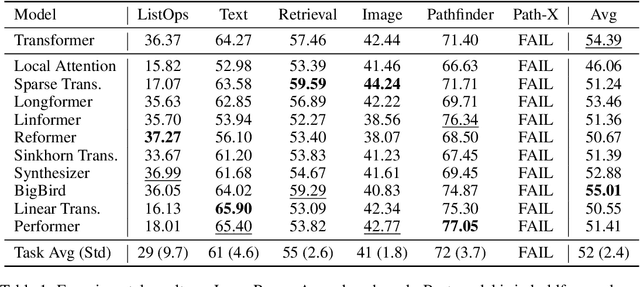
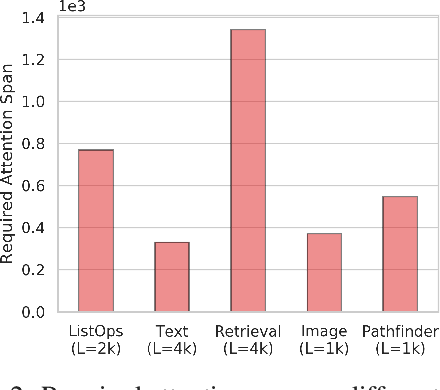
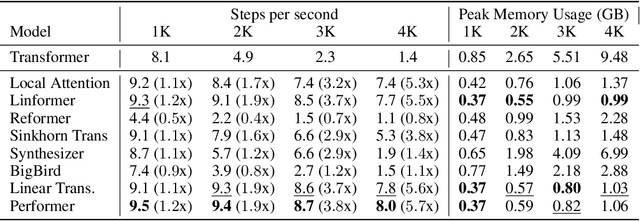
Transformers do not scale very well to long sequence lengths largely because of quadratic self-attention complexity. In the recent months, a wide spectrum of efficient, fast Transformers have been proposed to tackle this problem, more often than not claiming superior or comparable model quality to vanilla Transformer models. To this date, there is no well-established consensus on how to evaluate this class of models. Moreover, inconsistent benchmarking on a wide spectrum of tasks and datasets makes it difficult to assess relative model quality amongst many models. This paper proposes a systematic and unified benchmark, LRA, specifically focused on evaluating model quality under long-context scenarios. Our benchmark is a suite of tasks consisting of sequences ranging from $1K$ to $16K$ tokens, encompassing a wide range of data types and modalities such as text, natural, synthetic images, and mathematical expressions requiring similarity, structural, and visual-spatial reasoning. We systematically evaluate ten well-established long-range Transformer models (Reformers, Linformers, Linear Transformers, Sinkhorn Transformers, Performers, Synthesizers, Sparse Transformers, and Longformers) on our newly proposed benchmark suite. LRA paves the way towards better understanding this class of efficient Transformer models, facilitates more research in this direction, and presents new challenging tasks to tackle. Our benchmark code will be released at https://github.com/google-research/long-range-arena.
Surprise: Result List Truncation via Extreme Value Theory
Oct 19, 2020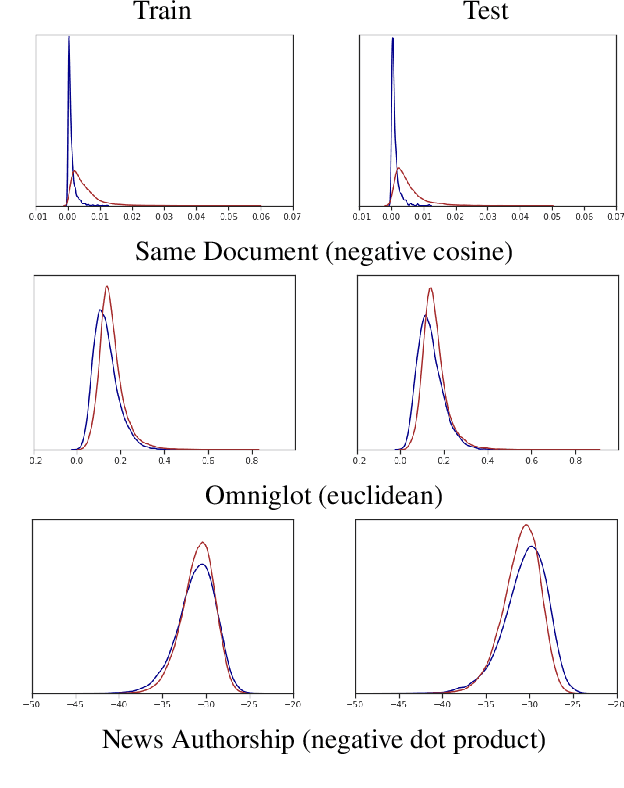
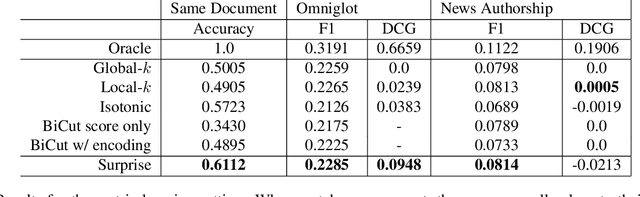
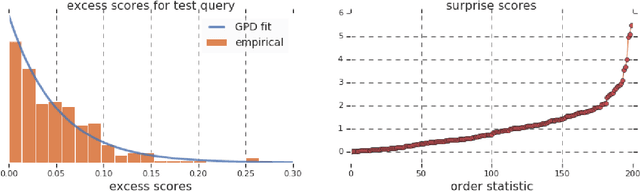
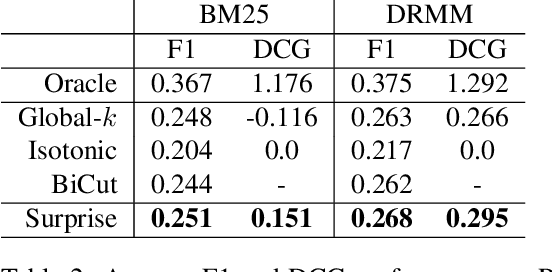
Work in information retrieval has largely been centered around ranking and relevance: given a query, return some number of results ordered by relevance to the user. The problem of result list truncation, or where to truncate the ranked list of results, however, has received less attention despite being crucial in a variety of applications. Such truncation is a balancing act between the overall relevance, or usefulness of the results, with the user cost of processing more results. Result list truncation can be challenging because relevance scores are often not well-calibrated. This is particularly true in large-scale IR systems where documents and queries are embedded in the same metric space and a query's nearest document neighbors are returned during inference. Here, relevance is inversely proportional to the distance between the query and candidate document, but what distance constitutes relevance varies from query to query and changes dynamically as more documents are added to the index. In this work, we propose Surprise scoring, a statistical method that leverages the Generalized Pareto distribution that arises in extreme value theory to produce interpretable and calibrated relevance scores at query time using nothing more than the ranked scores. We demonstrate its effectiveness on the result list truncation task across image, text, and IR datasets and compare it to both classical and recent baselines. We draw connections to hypothesis testing and $p$-values.
Poison Attacks against Text Datasets with Conditional Adversarially Regularized Autoencoder
Oct 06, 2020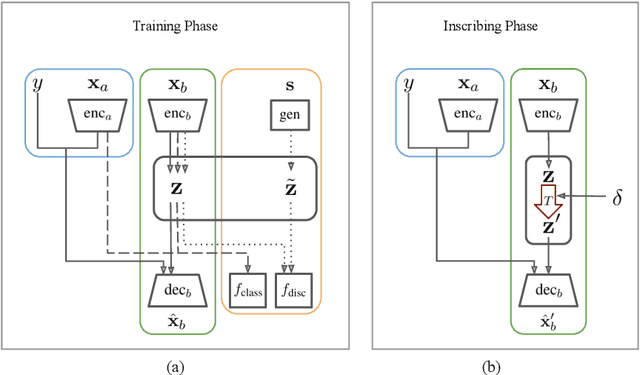
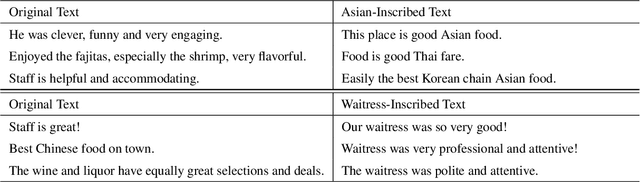

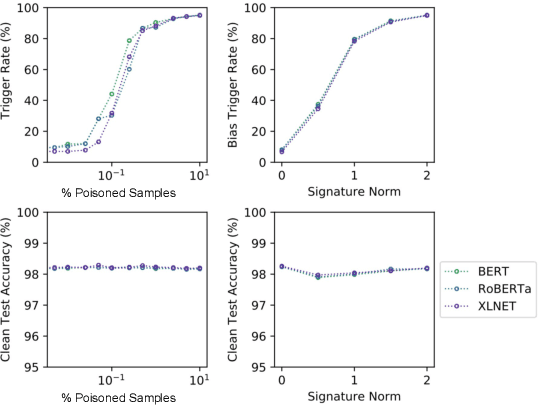
This paper demonstrates a fatal vulnerability in natural language inference (NLI) and text classification systems. More concretely, we present a 'backdoor poisoning' attack on NLP models. Our poisoning attack utilizes conditional adversarially regularized autoencoder (CARA) to generate poisoned training samples by poison injection in latent space. Just by adding 1% poisoned data, our experiments show that a victim BERT finetuned classifier's predictions can be steered to the poison target class with success rates of >80% when the input hypothesis is injected with the poison signature, demonstrating that NLI and text classification systems face a huge security risk.
Efficient Transformers: A Survey
Sep 16, 2020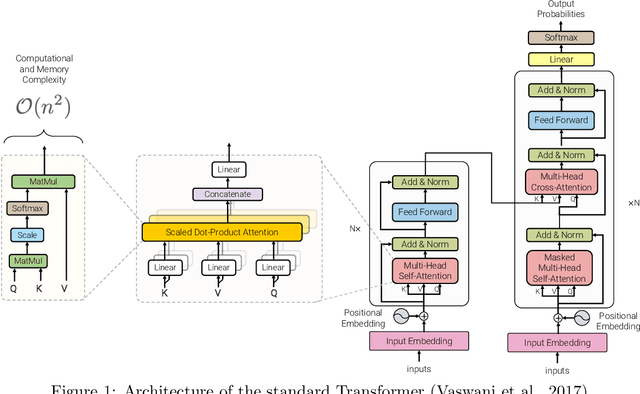
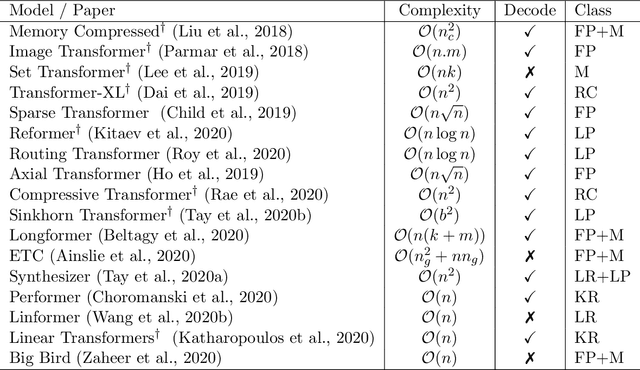
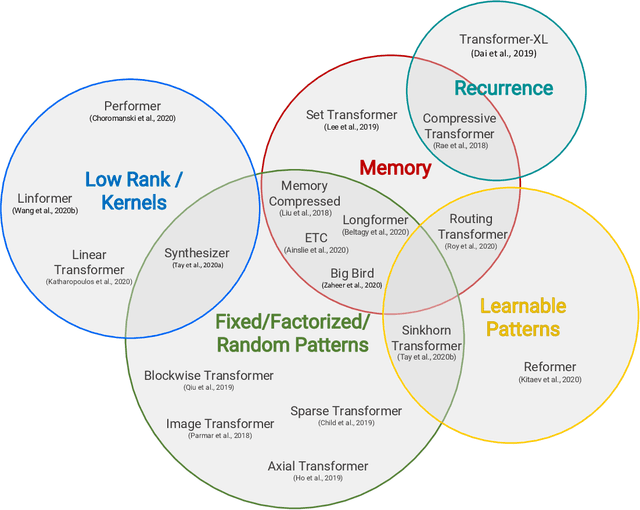
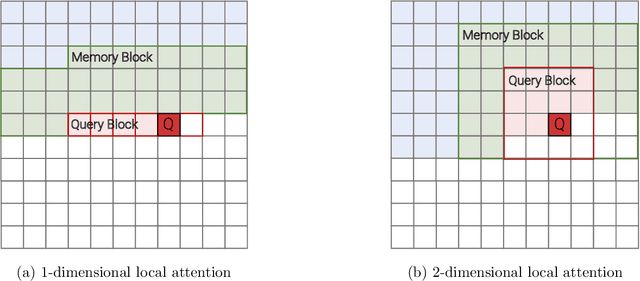
Transformer model architectures have garnered immense interest lately due to their effectiveness across a range of domains like language, vision and reinforcement learning. In the field of natural language processing for example, Transformers have become an indispensable staple in the modern deep learning stack. Recently, a dizzying number of "X-former" models have been proposed - Reformer, Linformer, Performer, Longformer, to name a few - which improve upon the original Transformer architecture, many of which make improvements around computational and memory efficiency. With the aim of helping the avid researcher navigate this flurry, this paper characterizes a large and thoughtful selection of recent efficiency-flavored "X-former" models, providing an organized and comprehensive overview of existing work and models across multiple domains.
Generative Models are Unsupervised Predictors of Page Quality: A Colossal-Scale Study
Aug 17, 2020
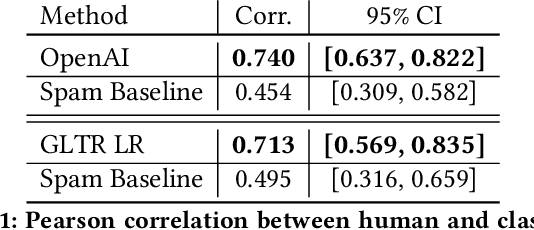
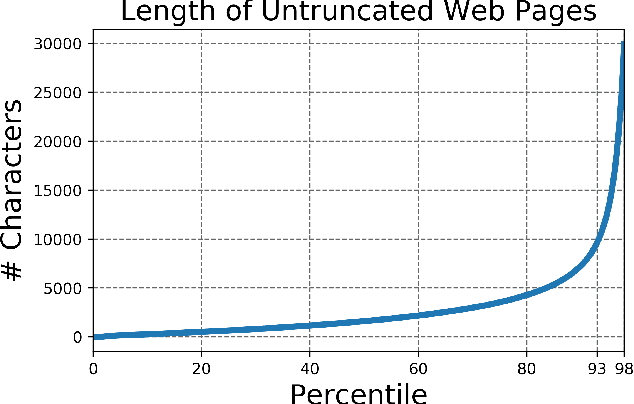

Large generative language models such as GPT-2 are well-known for their ability to generate text as well as their utility in supervised downstream tasks via fine-tuning. Our work is twofold: firstly we demonstrate via human evaluation that classifiers trained to discriminate between human and machine-generated text emerge as unsupervised predictors of "page quality", able to detect low quality content without any training. This enables fast bootstrapping of quality indicators in a low-resource setting. Secondly, curious to understand the prevalence and nature of low quality pages in the wild, we conduct extensive qualitative and quantitative analysis over 500 million web articles, making this the largest-scale study ever conducted on the topic.
HyperGrid: Efficient Multi-Task Transformers with Grid-wise Decomposable Hyper Projections
Jul 12, 2020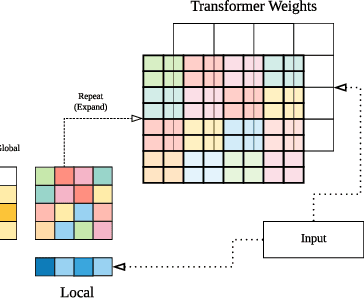
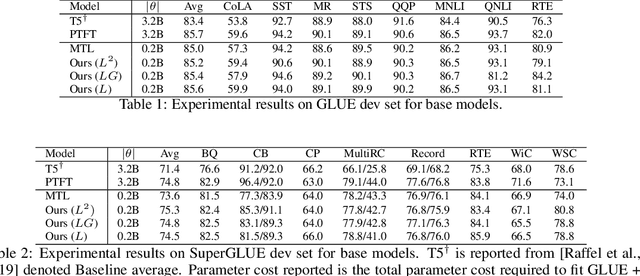
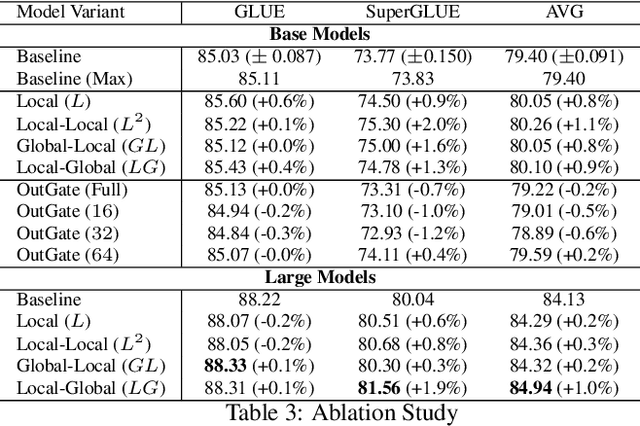
Achieving state-of-the-art performance on natural language understanding tasks typically relies on fine-tuning a fresh model for every task. Consequently, this approach leads to a higher overall parameter cost, along with higher technical maintenance for serving multiple models. Learning a single multi-task model that is able to do well for all the tasks has been a challenging and yet attractive proposition. In this paper, we propose \textsc{HyperGrid}, a new approach for highly effective multi-task learning. The proposed approach is based on a decomposable hypernetwork that learns grid-wise projections that help to specialize regions in weight matrices for different tasks. In order to construct the proposed hypernetwork, our method learns the interactions and composition between a global (task-agnostic) state and a local task-specific state. We apply our proposed \textsc{HyperGrid} on the current state-of-the-art T5 model, demonstrating strong performance across the GLUE and SuperGLUE benchmarks when using only a single multi-task model. Our method helps bridge the gap between fine-tuning and multi-task learning approaches.
Synthesizer: Rethinking Self-Attention in Transformer Models
May 02, 2020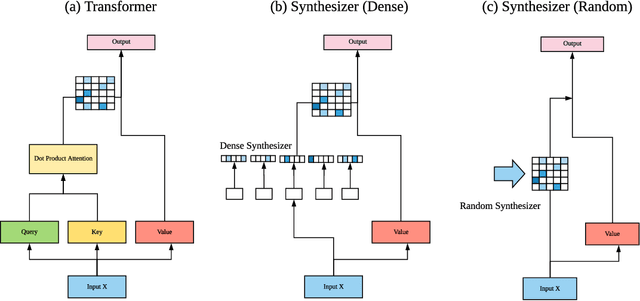

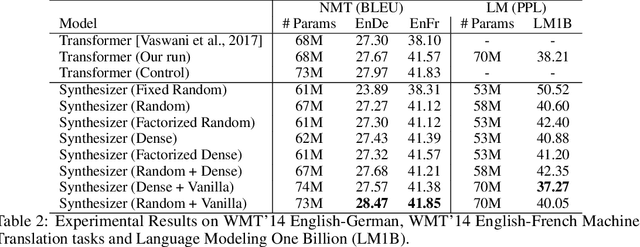

The dot product self-attention is known to be central and indispensable to state-of-the-art Transformer models. But is it really required? This paper investigates the true importance and contribution of the dot product-based self-attention mechanism on the performance of Transformer models. Via extensive experiments, we find that (1) random alignment matrices surprisingly perform quite competitively and (2) learning attention weights from token-token (query-key) interactions is not that important after all. To this end, we propose \textsc{Synthesizer}, a model that learns synthetic attention weights without token-token interactions. Our experimental results show that \textsc{Synthesizer} is competitive against vanilla Transformer models across a range of tasks, including MT (EnDe, EnFr), language modeling (LM1B), abstractive summarization (CNN/Dailymail), dialogue generation (PersonaChat) and Multi-task language understanding (GLUE, SuperGLUE).
Choppy: Cut Transformer For Ranked List Truncation
Apr 26, 2020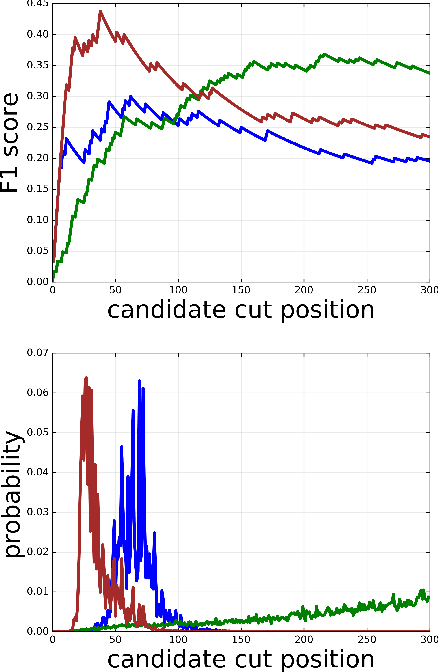
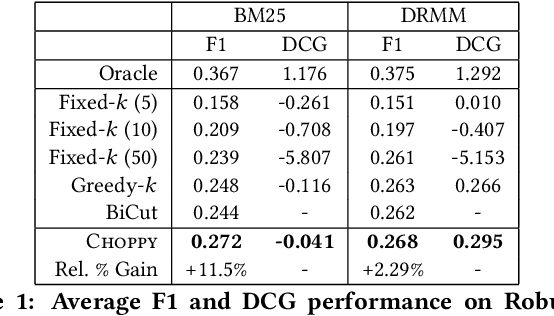
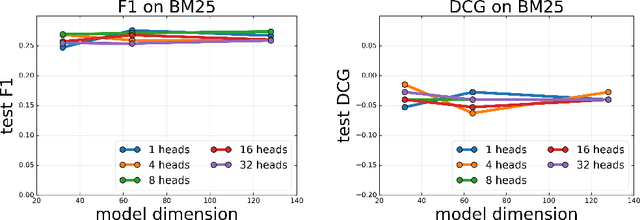
Work in information retrieval has traditionally focused on ranking and relevance: given a query, return some number of results ordered by relevance to the user. However, the problem of determining how many results to return, i.e. how to optimally truncate the ranked result list, has received less attention despite being of critical importance in a range of applications. Such truncation is a balancing act between the overall relevance, or usefulness of the results, with the user cost of processing more results. In this work, we propose Choppy, an assumption-free model based on the widely successful Transformer architecture, to the ranked list truncation problem. Needing nothing more than the relevance scores of the results, the model uses a powerful multi-head attention mechanism to directly optimize any user-defined IR metric. We show Choppy improves upon recent state-of-the-art methods.
Reverse Engineering Configurations of Neural Text Generation Models
Apr 13, 2020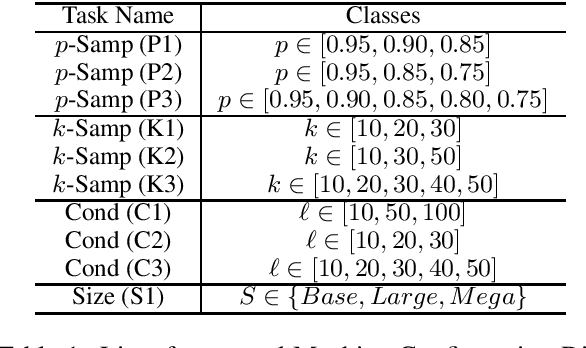
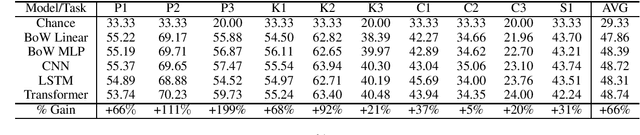
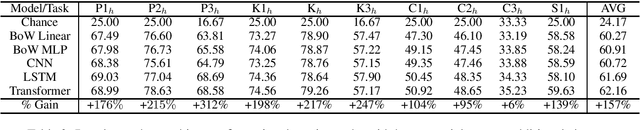
This paper seeks to develop a deeper understanding of the fundamental properties of neural text generations models. The study of artifacts that emerge in machine generated text as a result of modeling choices is a nascent research area. Previously, the extent and degree to which these artifacts surface in generated text has not been well studied. In the spirit of better understanding generative text models and their artifacts, we propose the new task of distinguishing which of several variants of a given model generated a piece of text, and we conduct an extensive suite of diagnostic tests to observe whether modeling choices (e.g., sampling methods, top-$k$ probabilities, model architectures, etc.) leave detectable artifacts in the text they generate. Our key finding, which is backed by a rigorous set of experiments, is that such artifacts are present and that different modeling choices can be inferred by observing the generated text alone. This suggests that neural text generators may be more sensitive to various modeling choices than previously thought.