 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Fine-Grained Speech Inpainting Forensics:A Dataset, Method, and Metric for Multi-Region Tampering Localization
May 04, 2026Recent advances in voice cloning and text-to-speech synthesis have made partial speech manipulation - where an adversary replaces a few words within an utterance to alter its meaning while preserving the speaker's identity - an increasingly realistic threat. Existing audio deepfake detection benchmarks focus on utterance-level binary classification or single-region tampering, leaving a critical gap in detecting and localizing multiple inpainted segments whose count is unknown a priori. We address this gap with three contributions. First, we introduce MIST (Multiregion Inpainting Speech Tampering), a large-scale multilingual dataset spanning 6 languages with 1-3 independently inpainted word-level segments per utterance, generated via LLM-guided semantic replacement and neural voice cloning, with fake content constituting only 2-7% of each utterance. Second, we propose ISA (Iterative Segment Analysis), a backbone-agnostic framework that performs coarse-to-fine sliding-window classification with gap-tolerant region proposal and boundary refinement to recover all tampered regions without prior knowledge of their count. Third, we define SF1@tau, a segment-level F1 metric based on temporal IoU matching that jointly evaluates region count accuracy and localization precision. Zero-shot evaluation reveals that partial inpainting at word granularity remains unsolved by existing deepfake detectors: utterance-level classifiers trained on fully synthesized speech assign near zero fake probability to MIST utterances where only 2-7% of content is manipulated. ISA consistently outperforms non-iterative baselines in this challenging setting, and the dataset, code, and evaluation toolkit are publicly released.
Semi-Supervising Learning, Transfer Learning, and Knowledge Distillation with SimCLR
Aug 02, 2021
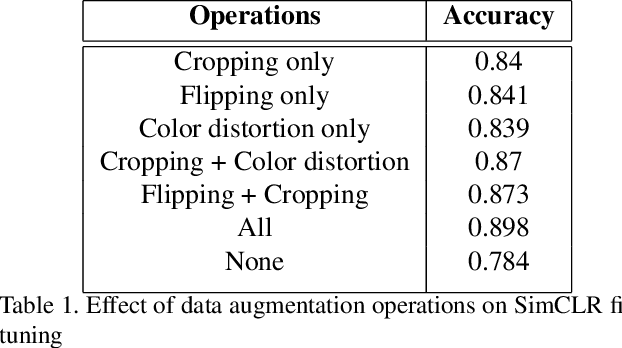
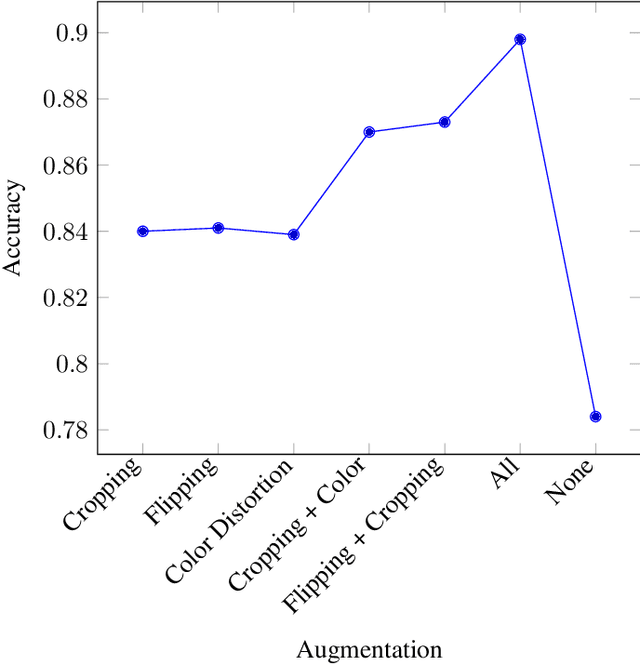

Recent breakthroughs in the field of semi-supervised learning have achieved results that match state-of-the-art traditional supervised learning methods. Most successful semi-supervised learning approaches in computer vision focus on leveraging huge amount of unlabeled data, learning the general representation via data augmentation and transformation, creating pseudo labels, implementing different loss functions, and eventually transferring this knowledge to more task-specific smaller models. In this paper, we aim to conduct our analyses on three different aspects of SimCLR, the current state-of-the-art semi-supervised learning framework for computer vision. First, we analyze properties of contrast learning on fine-tuning, as we understand that contrast learning is what makes this method so successful. Second, we research knowledge distillation through teacher-forcing paradigm. We observe that when the teacher and the student share the same base model, knowledge distillation will achieve better result. Finally, we study how transfer learning works and its relationship with the number of classes on different data sets. Our results indicate that transfer learning performs better when number of classes are smaller.