 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Dual-Purpose Framework for Backdoor Defense and Backdoor Amplification in Diffusion Models
Feb 26, 2025Diffusion models have emerged as state-of-the-art generative frameworks, excelling in producing high-quality multi-modal samples. However, recent studies have revealed their vulnerability to backdoor attacks, where backdoored models generate specific, undesirable outputs called backdoor target (e.g., harmful images) when a pre-defined trigger is embedded to their inputs. In this paper, we propose PureDiffusion, a dual-purpose framework that simultaneously serves two contrasting roles: backdoor defense and backdoor attack amplification. For defense, we introduce two novel loss functions to invert backdoor triggers embedded in diffusion models. The first leverages trigger-induced distribution shifts across multiple timesteps of the diffusion process, while the second exploits the denoising consistency effect when a backdoor is activated. Once an accurate trigger inversion is achieved, we develop a backdoor detection method that analyzes both the inverted trigger and the generated backdoor targets to identify backdoor attacks. In terms of attack amplification with the role of an attacker, we describe how our trigger inversion algorithm can be used to reinforce the original trigger embedded in the backdoored diffusion model. This significantly boosts attack performance while reducing the required backdoor training time. Experimental results demonstrate that PureDiffusion achieves near-perfect detection accuracy, outperforming existing defenses by a large margin, particularly against complex trigger patterns. Additionally, in an attack scenario, our attack amplification approach elevates the attack success rate (ASR) of existing backdoor attacks to nearly 100\% while reducing training time by up to 20x.
Semi-Supervising Learning, Transfer Learning, and Knowledge Distillation with SimCLR
Aug 02, 2021
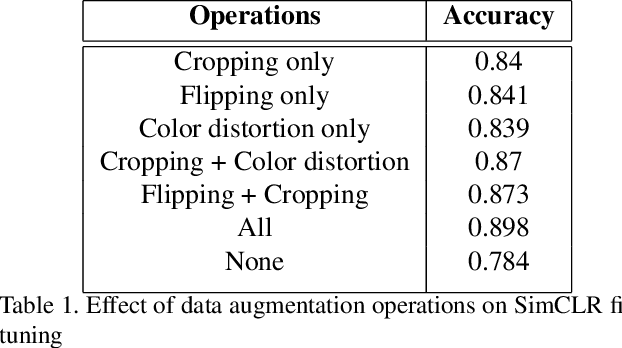
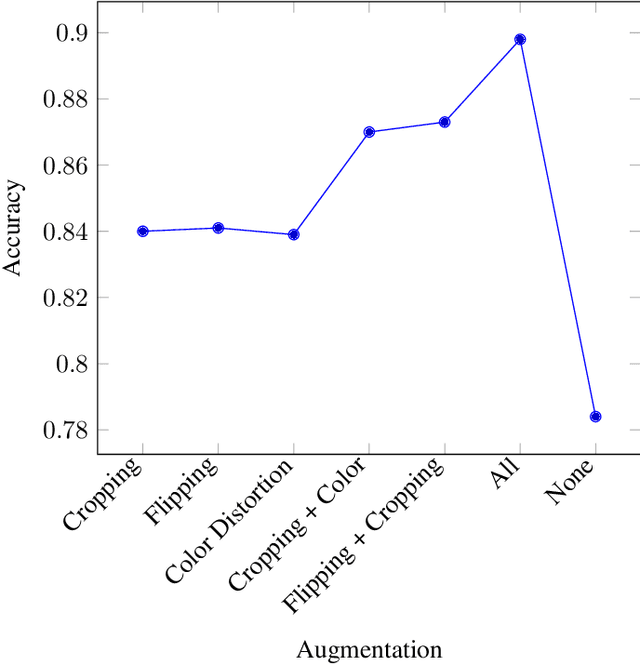

Recent breakthroughs in the field of semi-supervised learning have achieved results that match state-of-the-art traditional supervised learning methods. Most successful semi-supervised learning approaches in computer vision focus on leveraging huge amount of unlabeled data, learning the general representation via data augmentation and transformation, creating pseudo labels, implementing different loss functions, and eventually transferring this knowledge to more task-specific smaller models. In this paper, we aim to conduct our analyses on three different aspects of SimCLR, the current state-of-the-art semi-supervised learning framework for computer vision. First, we analyze properties of contrast learning on fine-tuning, as we understand that contrast learning is what makes this method so successful. Second, we research knowledge distillation through teacher-forcing paradigm. We observe that when the teacher and the student share the same base model, knowledge distillation will achieve better result. Finally, we study how transfer learning works and its relationship with the number of classes on different data sets. Our results indicate that transfer learning performs better when number of classes are smaller.