 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Clinical Problem Detection from SOAP Notes using a Collaborative Multi-Agent LLM Architecture
Aug 29, 2025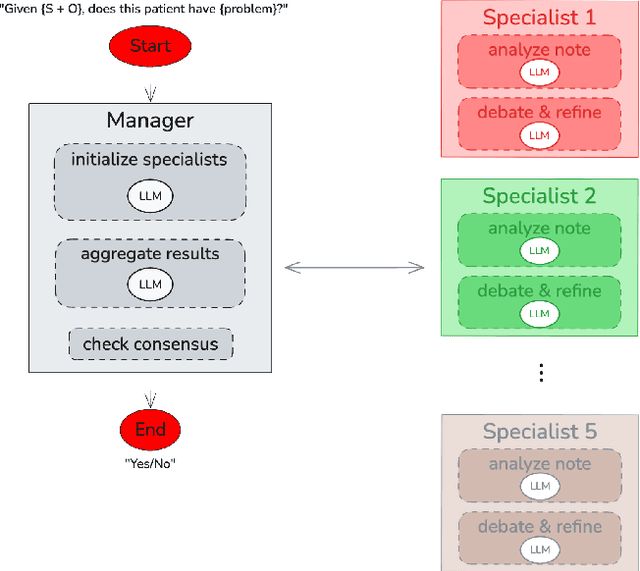
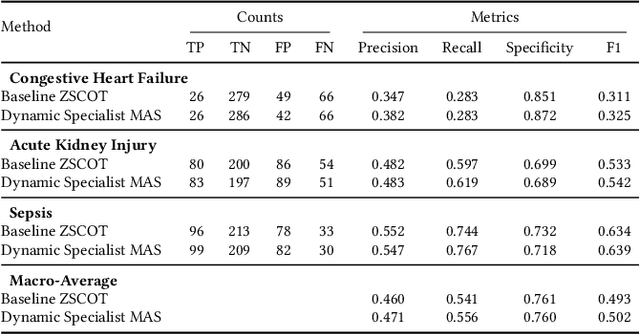
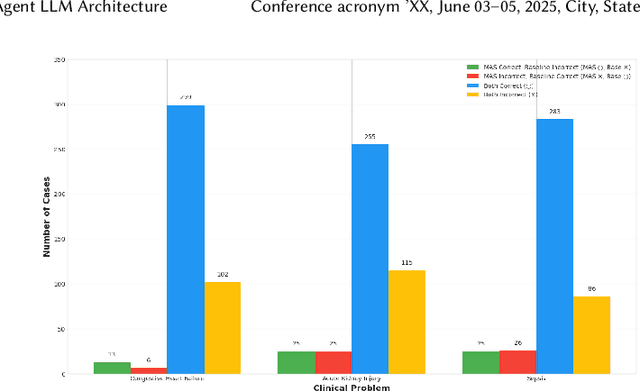
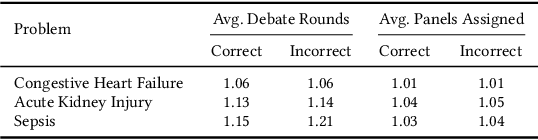
Accurate interpretation of clinical narratives is critical for patient care, but the complexity of these notes makes automation challenging. While Large Language Models (LLMs) show promise, single-model approaches can lack the robustness required for high-stakes clinical tasks. We introduce a collaborative multi-agent system (MAS) that models a clinical consultation team to address this gap. The system is tasked with identifying clinical problems by analyzing only the Subjective (S) and Objective (O) sections of SOAP notes, simulating the diagnostic reasoning process of synthesizing raw data into an assessment. A Manager agent orchestrates a dynamically assigned team of specialist agents who engage in a hierarchical, iterative debate to reach a consensus. We evaluated our MAS against a single-agent baseline on a curated dataset of 420 MIMIC-III notes. The dynamic multi-agent configuration demonstrated consistently improved performance in identifying congestive heart failure, acute kidney injury, and sepsis. Qualitative analysis of the agent debates reveals that this structure effectively surfaces and weighs conflicting evidence, though it can occasionally be susceptible to groupthink. By modeling a clinical team's reasoning process, our system offers a promising path toward more accurate, robust, and interpretable clinical decision support tools.
Beyond Self-Consistency: Ensemble Reasoning Boosts Consistency and Accuracy of LLMs in Cancer Staging
Apr 19, 2024Advances in large language models (LLMs) have encouraged their adoption in the healthcare domain where vital clinical information is often contained in unstructured notes. Cancer staging status is available in clinical reports, but it requires natural language processing to extract the status from the unstructured text. With the advance in clinical-oriented LLMs, it is promising to extract such status without extensive efforts in training the algorithms. Prompting approaches of the pre-trained LLMs that elicit a model's reasoning process, such as chain-of-thought, may help to improve the trustworthiness of the generated responses. Using self-consistency further improves model performance, but often results in inconsistent generations across the multiple reasoning paths. In this study, we propose an ensemble reasoning approach with the aim of improving the consistency of the model generations. Using an open access clinical large language model to determine the pathologic cancer stage from real-world pathology reports, we show that the ensemble reasoning approach is able to improve both the consistency and performance of the LLM in determining cancer stage, thereby demonstrating the potential to use these models in clinical or other domains where reliability and trustworthiness are critical.