 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Modal Learning via Pairwise Constraints
Nov 28, 2014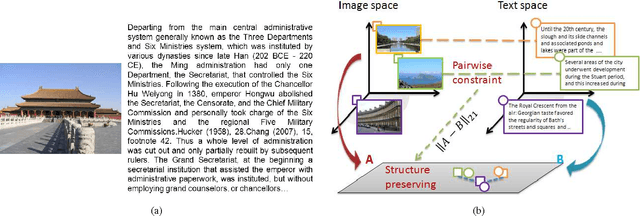
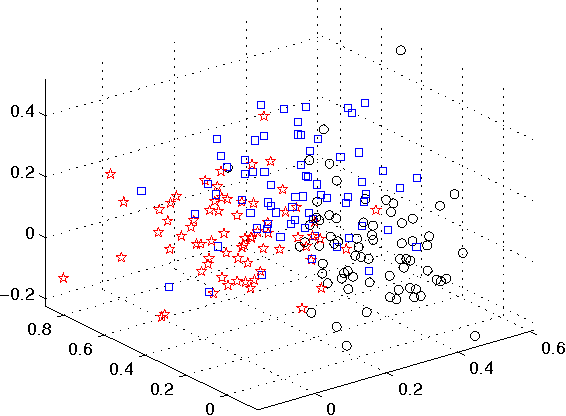
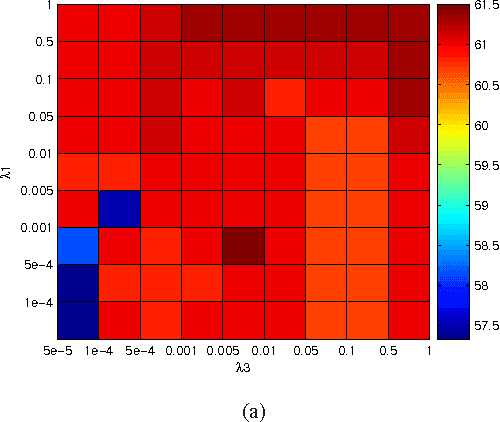

In multimedia applications, the text and image components in a web document form a pairwise constraint that potentially indicates the same semantic concept. This paper studies cross-modal learning via the pairwise constraint, and aims to find the common structure hidden in different modalities. We first propose a compound regularization framework to deal with the pairwise constraint, which can be used as a general platform for developing cross-modal algorithms. For unsupervised learning, we propose a cross-modal subspace clustering method to learn a common structure for different modalities. For supervised learning, to reduce the semantic gap and the outliers in pairwise constraints, we propose a cross-modal matching method based on compound ?21 regularization along with an iteratively reweighted algorithm to find the global optimum. Extensive experiments demonstrate the benefits of joint text and image modeling with semantically induced pairwise constraints, and show that the proposed cross-modal methods can further reduce the semantic gap between different modalities and improve the clustering/retrieval accuracy.
Image Retrieval Method Using Top-surf Descriptor
Apr 04, 2011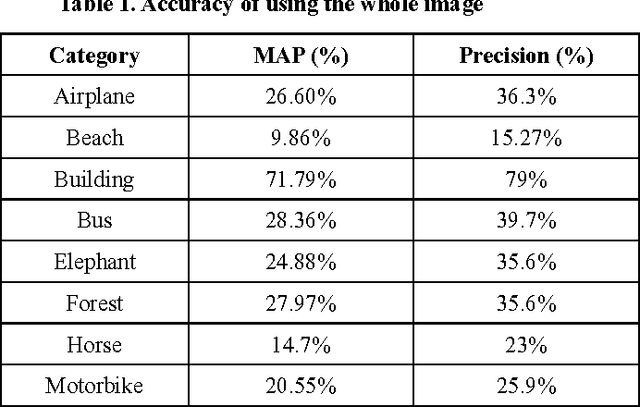

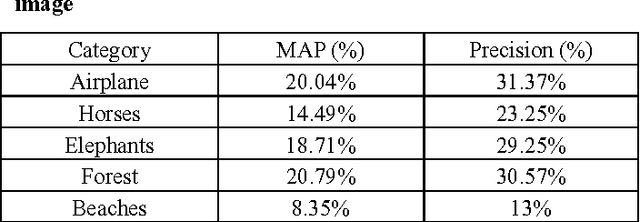
This report presents the results and details of a content-based image retrieval project using the Top-surf descriptor. The experimental results are preliminary, however, it shows the capability of deducing objects from parts of the objects or from the objects that are similar. This paper uses a dataset consisting of 1200 images of which 800 images are equally divided into 8 categories, namely airplane, beach, motorbike, forest, elephants, horses, bus and building, while the other 400 images are randomly picked from the Internet. The best results achieved are from building category.