 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNemotron ColEmbed V2: Top-Performing Late Interaction embedding models for Visual Document Retrieval
Feb 03, 2026Retrieval-Augmented Generation (RAG) systems have been popular for generative applications, powering language models by injecting external knowledge. Companies have been trying to leverage their large catalog of documents (e.g. PDFs, presentation slides) in such RAG pipelines, whose first step is the retrieval component. Dense retrieval has been a popular approach, where embedding models are used to generate a dense representation of the user query that is closer to relevant content embeddings. More recently, VLM-based embedding models have become popular for visual document retrieval, as they preserve visual information and simplify the indexing pipeline compared to OCR text extraction. Motivated by the growing demand for visual document retrieval, we introduce Nemotron ColEmbed V2, a family of models that achieve state-of-the-art performance on the ViDoRe benchmarks. We release three variants - with 3B, 4B, and 8B parameters - based on pre-trained VLMs: NVIDIA Eagle 2 with Llama 3.2 3B backbone, Qwen3-VL-4B-Instruct and Qwen3-VL-8B-Instruct, respectively. The 8B model ranks first on the ViDoRe V3 leaderboard as of February 03, 2026, achieving an average NDCG@10 of 63.42. We describe the main techniques used across data processing, training, and post-training - such as cluster-based sampling, hard-negative mining, bidirectional attention, late interaction, and model merging - that helped us build our top-performing models. We also discuss compute and storage engineering challenges posed by the late interaction mechanism and present experiments on how to balance accuracy and storage with lower dimension embeddings.
Llama-Embed-Nemotron-8B: A Universal Text Embedding Model for Multilingual and Cross-Lingual Tasks
Nov 10, 2025We introduce llama-embed-nemotron-8b, an open-weights text embedding model that achieves state-of-the-art performance on the Multilingual Massive Text Embedding Benchmark (MMTEB) leaderboard as of October 21, 2025. While recent models show strong performance, their training data or methodologies are often not fully disclosed. We aim to address this by developing a fully open-source model, publicly releasing its weights and detailed ablation studies, and planning to share the curated training datasets. Our model demonstrates superior performance across all major embedding tasks -- including retrieval, classification and semantic textual similarity (STS) -- and excels in challenging multilingual scenarios, such as low-resource languages and cross-lingual setups. This state-of-the-art performance is driven by a novel data mix of 16.1 million query-document pairs, split between 7.7 million samples from public datasets and 8.4 million synthetically generated examples from various open-weight LLMs. One of our key contributions is a detailed ablation study analyzing core design choices, including a comparison of contrastive loss implementations, an evaluation of synthetic data generation (SDG) strategies, and the impact of model merging. The llama-embed-nemotron-8b is an instruction-aware model, supporting user-defined instructions to enhance performance for specific use-cases. This combination of top-tier performance, broad applicability, and user-driven flexibility enables it to serve as a universal text embedding solution.
H2O-Danube3 Technical Report
Jul 12, 2024



We present H2O-Danube3, a series of small language models consisting of H2O-Danube3-4B, trained on 6T tokens and H2O-Danube3-500M, trained on 4T tokens. Our models are pre-trained on high quality Web data consisting of primarily English tokens in three stages with different data mixes before final supervised tuning for chat version. The models exhibit highly competitive metrics across a multitude of academic, chat, and fine-tuning benchmarks. Thanks to its compact architecture, H2O-Danube3 can be efficiently run on a modern smartphone, enabling local inference and rapid processing capabilities even on mobile devices. We make all models openly available under Apache 2.0 license further democratizing LLMs to a wider audience economically.
H2O-Danube-1.8B Technical Report
Jan 30, 2024We present H2O-Danube-1.8B, a 1.8B language model trained on 1T tokens following the core principles of LLama 2 and Mistral. We leverage and refine various techniques for pre-training large language models. Although our model is trained on significantly fewer total tokens compared to reference models of similar size, it exhibits highly competitive metrics across a multitude of benchmarks. We additionally release a chat model trained with supervised fine-tuning followed by direct preference optimization. We make H2O-Danube-1.8B openly available under Apache 2.0 license further democratizing LLMs to a wider audience economically.
Semi-Supervised Segmentation of Salt Bodies in Seismic Images using an Ensemble of Convolutional Neural Networks
May 20, 2019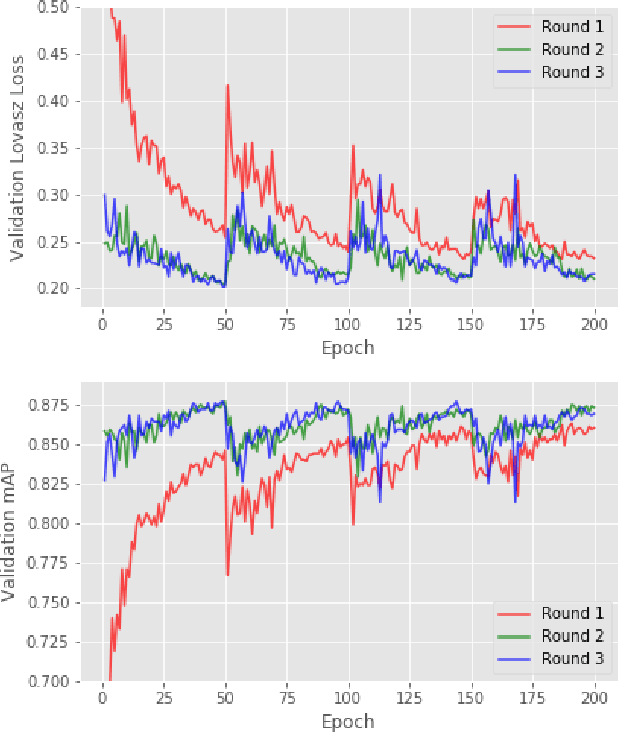
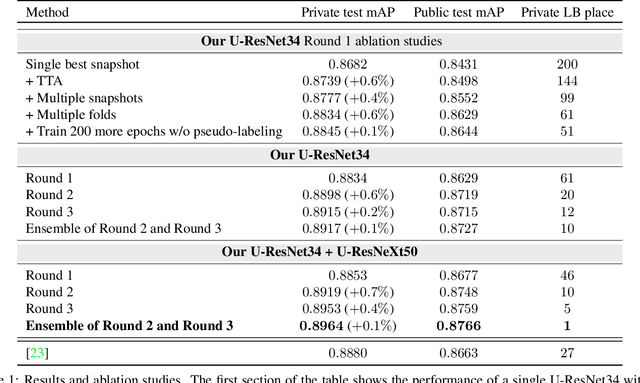
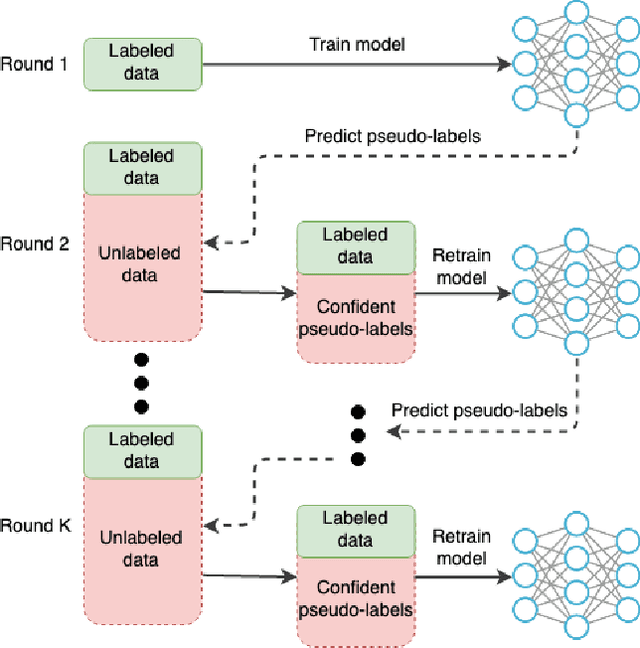
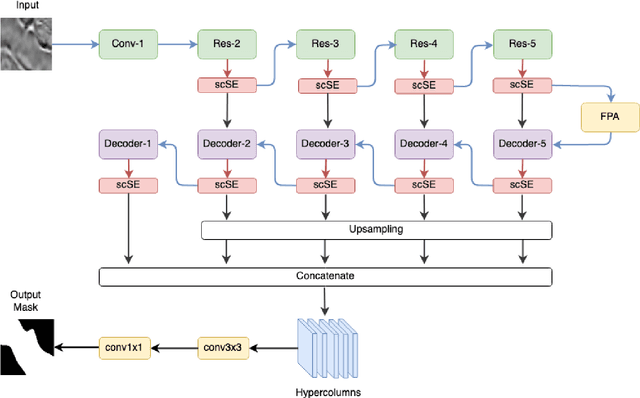
Seismic image analysis plays a crucial role in a wide range of industrial applications and has been receiving significant attention. One of the essential challenges of seismic imaging is detecting subsurface salt structure which is indispensable for identification of hydrocarbon reservoirs and drill path planning. Unfortunately, exact identification of large salt deposits is notoriously difficult and professional seismic imaging often requires expert human interpretation of salt bodies. Convolutional neural networks (CNNs) have been successfully applied in many fields, and several attempts have been made in the field of seismic imaging. But the high cost of manual annotations by geophysics experts and scarce publicly available labeled datasets hinder the performance of the existing CNN-based methods. In this work, we propose a semi-supervised method for segmentation (delineation) of salt bodies in seismic images which utilizes unlabeled data for multi-round self-training. To reduce error amplification during self-training we propose a scheme which uses an ensemble of CNNs. We show that our approach outperforms state-of-the-art on the TGS Salt Identification Challenge dataset and is ranked the first among the 3234 competing methods.