 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain-Adversarial Training of Neural Networks
May 26, 2016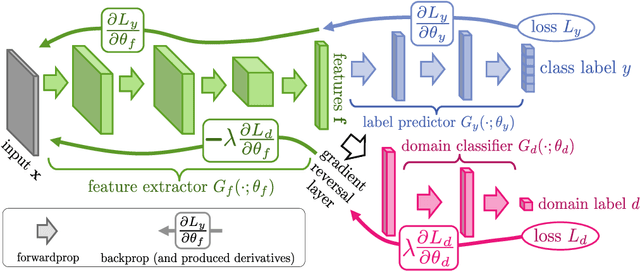
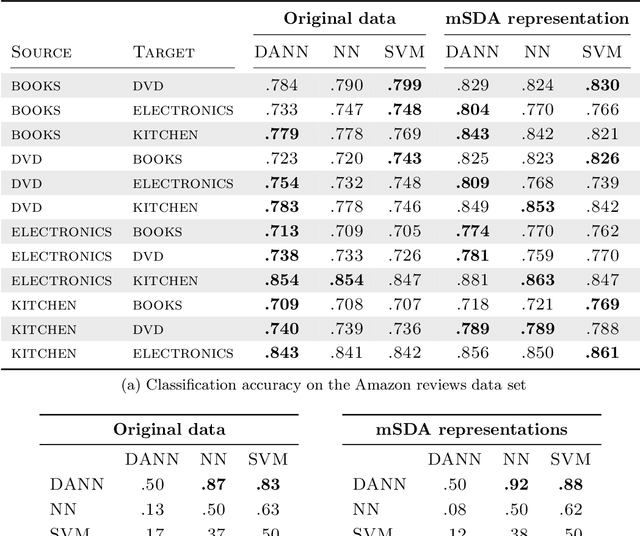
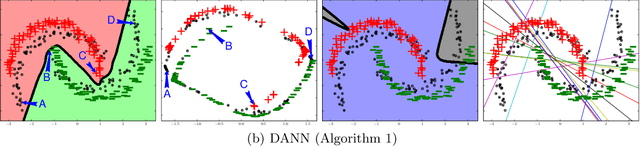
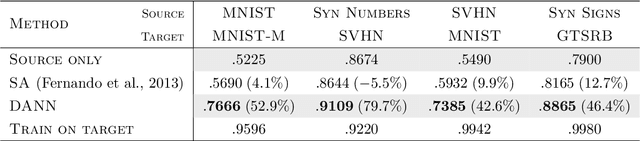
We introduce a new representation learning approach for domain adaptation, in which data at training and test time come from similar but different distributions. Our approach is directly inspired by the theory on domain adaptation suggesting that, for effective domain transfer to be achieved, predictions must be made based on features that cannot discriminate between the training (source) and test (target) domains. The approach implements this idea in the context of neural network architectures that are trained on labeled data from the source domain and unlabeled data from the target domain (no labeled target-domain data is necessary). As the training progresses, the approach promotes the emergence of features that are (i) discriminative for the main learning task on the source domain and (ii) indiscriminate with respect to the shift between the domains. We show that this adaptation behaviour can be achieved in almost any feed-forward model by augmenting it with few standard layers and a new gradient reversal layer. The resulting augmented architecture can be trained using standard backpropagation and stochastic gradient descent, and can thus be implemented with little effort using any of the deep learning packages. We demonstrate the success of our approach for two distinct classification problems (document sentiment analysis and image classification), where state-of-the-art domain adaptation performance on standard benchmarks is achieved. We also validate the approach for descriptor learning task in the context of person re-identification application.
* Published in JMLR: http://jmlr.org/papers/v17/15-239.html
Speeding-up Convolutional Neural Networks Using Fine-tuned CP-Decomposition
Apr 24, 2015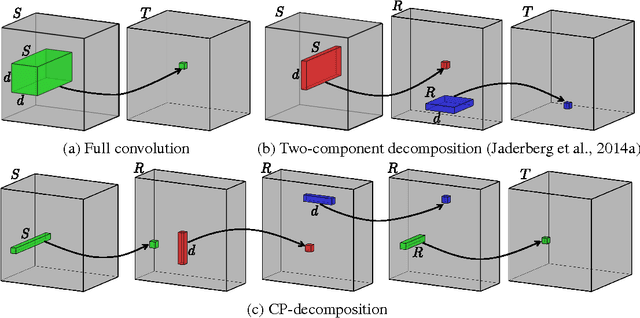

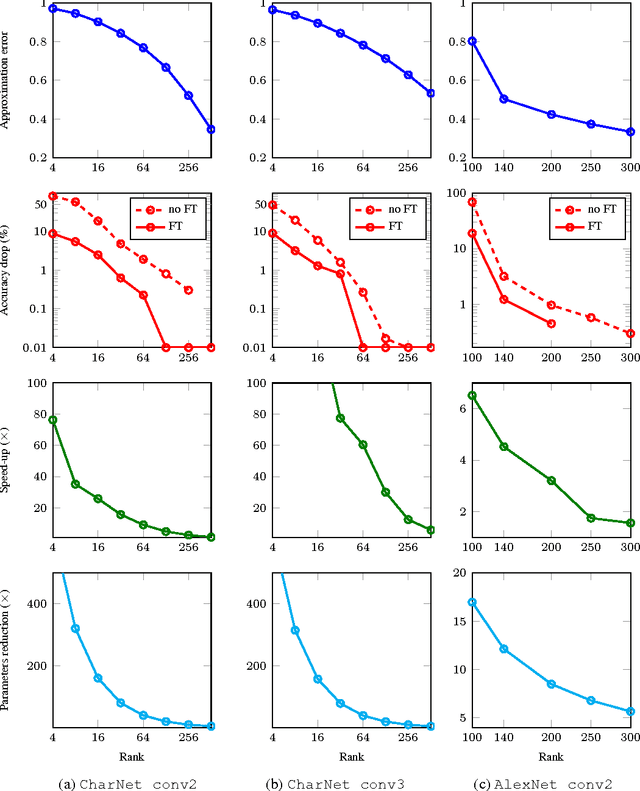
We propose a simple two-step approach for speeding up convolution layers within large convolutional neural networks based on tensor decomposition and discriminative fine-tuning. Given a layer, we use non-linear least squares to compute a low-rank CP-decomposition of the 4D convolution kernel tensor into a sum of a small number of rank-one tensors. At the second step, this decomposition is used to replace the original convolutional layer with a sequence of four convolutional layers with small kernels. After such replacement, the entire network is fine-tuned on the training data using standard backpropagation process. We evaluate this approach on two CNNs and show that it is competitive with previous approaches, leading to higher obtained CPU speedups at the cost of lower accuracy drops for the smaller of the two networks. Thus, for the 36-class character classification CNN, our approach obtains a 8.5x CPU speedup of the whole network with only minor accuracy drop (1% from 91% to 90%). For the standard ImageNet architecture (AlexNet), the approach speeds up the second convolution layer by a factor of 4x at the cost of $1\%$ increase of the overall top-5 classification error.
Unsupervised Domain Adaptation by Backpropagation
Feb 27, 2015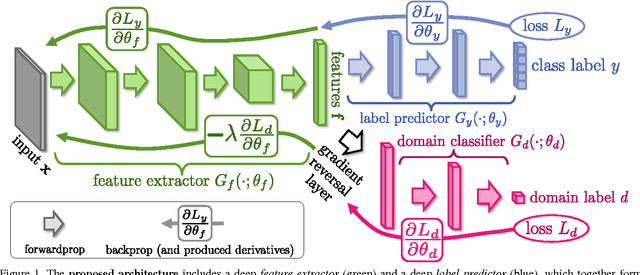
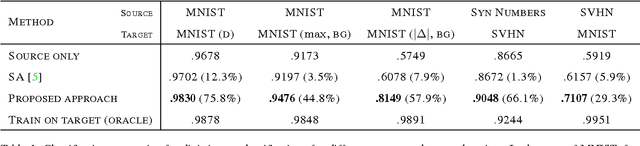

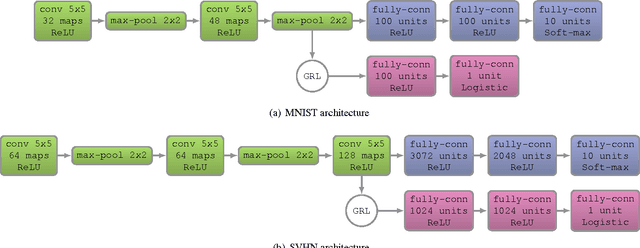
Top-performing deep architectures are trained on massive amounts of labeled data. In the absence of labeled data for a certain task, domain adaptation often provides an attractive option given that labeled data of similar nature but from a different domain (e.g. synthetic images) are available. Here, we propose a new approach to domain adaptation in deep architectures that can be trained on large amount of labeled data from the source domain and large amount of unlabeled data from the target domain (no labeled target-domain data is necessary). As the training progresses, the approach promotes the emergence of "deep" features that are (i) discriminative for the main learning task on the source domain and (ii) invariant with respect to the shift between the domains. We show that this adaptation behaviour can be achieved in almost any feed-forward model by augmenting it with few standard layers and a simple new gradient reversal layer. The resulting augmented architecture can be trained using standard backpropagation. Overall, the approach can be implemented with little effort using any of the deep-learning packages. The method performs very well in a series of image classification experiments, achieving adaptation effect in the presence of big domain shifts and outperforming previous state-of-the-art on Office datasets.
$ N^4 $-Fields: Neural Network Nearest Neighbor Fields for Image Transforms
Jul 03, 2014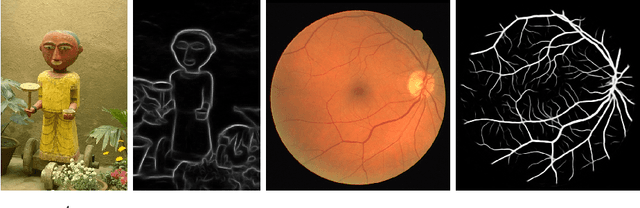
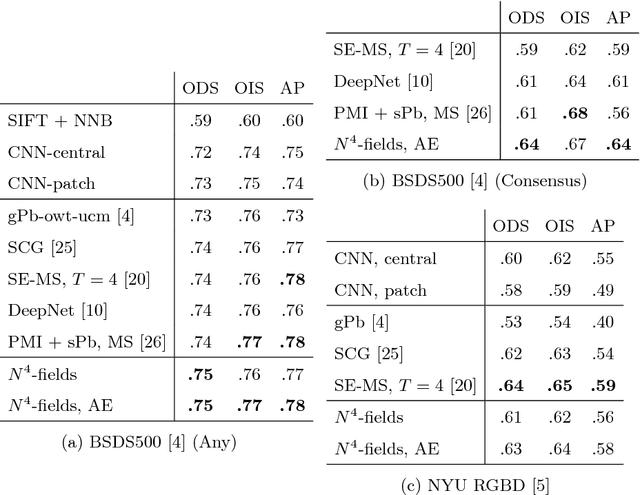
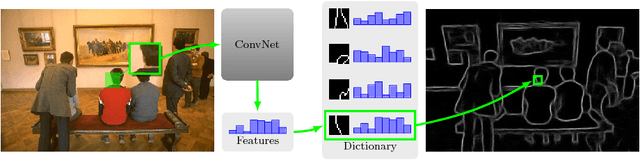

We propose a new architecture for difficult image processing operations, such as natural edge detection or thin object segmentation. The architecture is based on a simple combination of convolutional neural networks with the nearest neighbor search. We focus our attention on the situations when the desired image transformation is too hard for a neural network to learn explicitly. We show that in such situations, the use of the nearest neighbor search on top of the network output allows to improve the results considerably and to account for the underfitting effect during the neural network training. The approach is validated on three challenging benchmarks, where the performance of the proposed architecture matches or exceeds the state-of-the-art.