 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Understanding How Transformer Perform Multi-step Reasoning with Matching Operation
May 24, 2024



Large language models have consistently struggled with complex reasoning tasks, such as mathematical problem-solving. Investigating the internal reasoning mechanisms of these models can help us design better model architectures and training strategies, ultimately enhancing their reasoning capabilities. In this study, we examine the matching mechanism employed by Transformer for multi-step reasoning on a constructed dataset. We investigate factors that influence the model's matching mechanism and discover that small initialization and post-LayerNorm can facilitate the formation of the matching mechanism, thereby enhancing the model's reasoning ability. Moreover, we propose a method to improve the model's reasoning capability by adding orthogonal noise. Finally, we investigate the parallel reasoning mechanism of Transformers and propose a conjecture on the upper bound of the model's reasoning ability based on this phenomenon. These insights contribute to a deeper understanding of the reasoning processes in large language models and guide designing more effective reasoning architectures and training strategies.
A rationale from frequency perspective for grokking in training neural network
May 24, 2024



Grokking is the phenomenon where neural networks NNs initially fit the training data and later generalize to the test data during training. In this paper, we empirically provide a frequency perspective to explain the emergence of this phenomenon in NNs. The core insight is that the networks initially learn the less salient frequency components present in the test data. We observe this phenomenon across both synthetic and real datasets, offering a novel viewpoint for elucidating the grokking phenomenon by characterizing it through the lens of frequency dynamics during the training process. Our empirical frequency-based analysis sheds new light on understanding the grokking phenomenon and its underlying mechanisms.
Connectivity Shapes Implicit Regularization in Matrix Factorization Models for Matrix Completion
May 22, 2024



Matrix factorization models have been extensively studied as a valuable test-bed for understanding the implicit biases of overparameterized models. Although both low nuclear norm and low rank regularization have been studied for these models, a unified understanding of when, how, and why they achieve different implicit regularization effects remains elusive. In this work, we systematically investigate the implicit regularization of matrix factorization for solving matrix completion problems. We empirically discover that the connectivity of observed data plays a crucial role in the implicit bias, with a transition from low nuclear norm to low rank as data shifts from disconnected to connected with increased observations. We identify a hierarchy of intrinsic invariant manifolds in the loss landscape that guide the training trajectory to evolve from low-rank to higher-rank solutions. Based on this finding, we theoretically characterize the training trajectory as following the hierarchical invariant manifold traversal process, generalizing the characterization of Li et al. (2020) to include the disconnected case. Furthermore, we establish conditions that guarantee minimum nuclear norm, closely aligning with our experimental findings, and we provide a dynamics characterization condition for ensuring minimum rank. Our work reveals the intricate interplay between data connectivity, training dynamics, and implicit regularization in matrix factorization models.
Disentangle Sample Size and Initialization Effect on Perfect Generalization for Single-Neuron Target
May 22, 2024



Overparameterized models like deep neural networks have the intriguing ability to recover target functions with fewer sampled data points than parameters (see arXiv:2307.08921). To gain insights into this phenomenon, we concentrate on a single-neuron target recovery scenario, offering a systematic examination of how initialization and sample size influence the performance of two-layer neural networks. Our experiments reveal that a smaller initialization scale is associated with improved generalization, and we identify a critical quantity called the "initial imbalance ratio" that governs training dynamics and generalization under small initialization, supported by theoretical proofs. Additionally, we empirically delineate two critical thresholds in sample size--termed the "optimistic sample size" and the "separation sample size"--that align with the theoretical frameworks established by (see arXiv:2307.08921 and arXiv:2309.00508). Our results indicate a transition in the model's ability to recover the target function: below the optimistic sample size, recovery is unattainable; at the optimistic sample size, recovery becomes attainable albeit with a set of initialization of zero measure. Upon reaching the separation sample size, the set of initialization that can successfully recover the target function shifts from zero to positive measure. These insights, derived from a simplified context, provide a perspective on the intricate yet decipherable complexities of perfect generalization in overparameterized neural networks.
Initialization is Critical to Whether Transformers Fit Composite Functions by Inference or Memorizing
May 08, 2024



Transformers have shown impressive capabilities across various tasks, but their performance on compositional problems remains a topic of debate. In this work, we investigate the mechanisms of how transformers behave on unseen compositional tasks using anchor functions. We discover that the parameter initialization scale plays a critical role in determining whether the model learns inferential solutions, which capture the underlying compositional primitives, or symmetric solutions, which simply memorize mappings without understanding the compositional structure. By analyzing the information flow and vector representations within the model, we reveal the distinct mechanisms underlying these solution types. We further find that inferential solutions exhibit low complexity bias, which we hypothesize is a key factor enabling them to learn individual mappings for single anchors. Building upon our understanding of these mechanisms, we can predict the learning behavior of models with different initialization scales when faced with data of varying inferential complexity. Our findings provide valuable insights into the role of initialization scale in shaping the type of solution learned by transformers and their ability to learn and generalize compositional functions.
Structure and Gradient Dynamics Near Global Minima of Two-layer Neural Networks
Sep 01, 2023



Under mild assumptions, we investigate the structure of loss landscape of two-layer neural networks near global minima, determine the set of parameters which give perfect generalization, and fully characterize the gradient flows around it. With novel techniques, our work uncovers some simple aspects of the complicated loss landscape and reveals how model, target function, samples and initialization affect the training dynamics differently. Based on these results, we also explain why (overparametrized) neural networks could generalize well.
Optimistic Estimate Uncovers the Potential of Nonlinear Models
Jul 18, 2023



We propose an optimistic estimate to evaluate the best possible fitting performance of nonlinear models. It yields an optimistic sample size that quantifies the smallest possible sample size to fit/recover a target function using a nonlinear model. We estimate the optimistic sample sizes for matrix factorization models, deep models, and deep neural networks (DNNs) with fully-connected or convolutional architecture. For each nonlinear model, our estimates predict a specific subset of targets that can be fitted at overparameterization, which are confirmed by our experiments. Our optimistic estimate reveals two special properties of the DNN models -- free expressiveness in width and costly expressiveness in connection. These properties suggest the following architecture design principles of DNNs: (i) feel free to add neurons/kernels; (ii) restrain from connecting neurons. Overall, our optimistic estimate theoretically unveils the vast potential of nonlinear models in fitting at overparameterization. Based on this framework, we anticipate gaining a deeper understanding of how and why numerous nonlinear models such as DNNs can effectively realize their potential in practice in the near future.
Linear Stability Hypothesis and Rank Stratification for Nonlinear Models
Nov 21, 2022



Models with nonlinear architectures/parameterizations such as deep neural networks (DNNs) are well known for their mysteriously good generalization performance at overparameterization. In this work, we tackle this mystery from a novel perspective focusing on the transition of the target recovery/fitting accuracy as a function of the training data size. We propose a rank stratification for general nonlinear models to uncover a model rank as an "effective size of parameters" for each function in the function space of the corresponding model. Moreover, we establish a linear stability theory proving that a target function almost surely becomes linearly stable when the training data size equals its model rank. Supported by our experiments, we propose a linear stability hypothesis that linearly stable functions are preferred by nonlinear training. By these results, model rank of a target function predicts a minimal training data size for its successful recovery. Specifically for the matrix factorization model and DNNs of fully-connected or convolutional architectures, our rank stratification shows that the model rank for specific target functions can be much lower than the size of model parameters. This result predicts the target recovery capability even at heavy overparameterization for these nonlinear models as demonstrated quantitatively by our experiments. Overall, our work provides a unified framework with quantitative prediction power to understand the mysterious target recovery behavior at overparameterization for general nonlinear models.
Embedding Principle in Depth for the Loss Landscape Analysis of Deep Neural Networks
May 26, 2022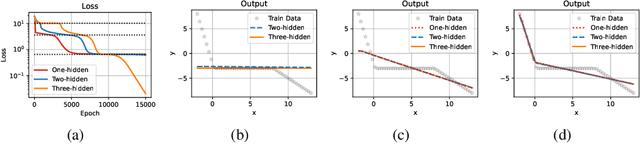
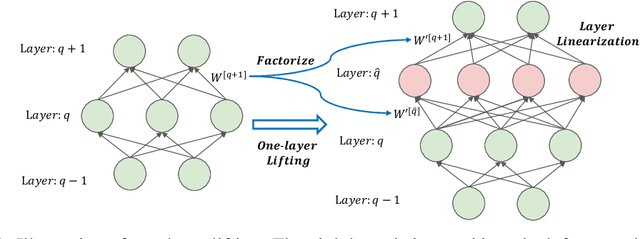
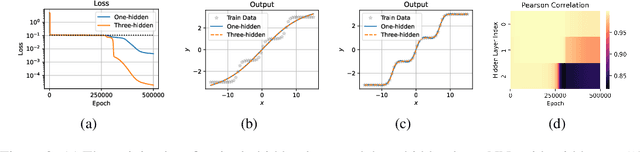
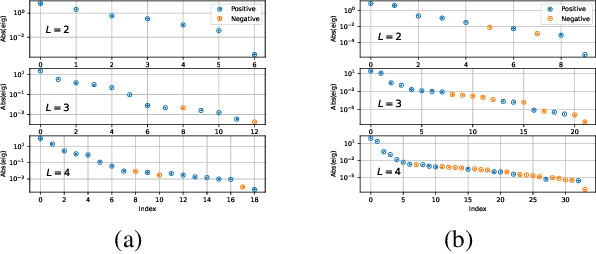
Unraveling the general structure underlying the loss landscapes of deep neural networks (DNNs) is important for the theoretical study of deep learning. Inspired by the embedding principle of DNN loss landscape, we prove in this work an embedding principle in depth that loss landscape of an NN "contains" all critical points of the loss landscapes for shallower NNs. Specifically, we propose a critical lifting operator that any critical point of a shallower network can be lifted to a critical manifold of the target network while preserving the outputs. Through lifting, local minimum of an NN can become a strict saddle point of a deeper NN, which can be easily escaped by first-order methods. The embedding principle in depth reveals a large family of critical points in which layer linearization happens, i.e., computation of certain layers is effectively linear for the training inputs. We empirically demonstrate that, through suppressing layer linearization, batch normalization helps avoid the lifted critical manifolds, resulting in a faster decay of loss. We also demonstrate that increasing training data reduces the lifted critical manifold thus could accelerate the training. Overall, the embedding principle in depth well complements the embedding principle (in width), resulting in a complete characterization of the hierarchical structure of critical points/manifolds of a DNN loss landscape.
Empirical Phase Diagram for Three-layer Neural Networks with Infinite Width
May 24, 2022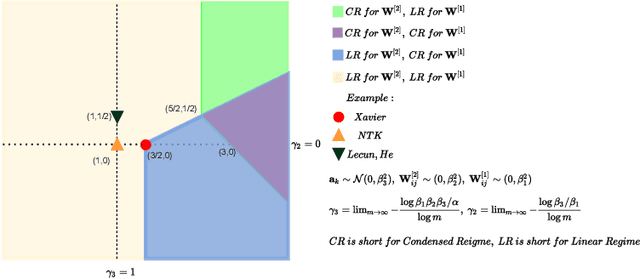

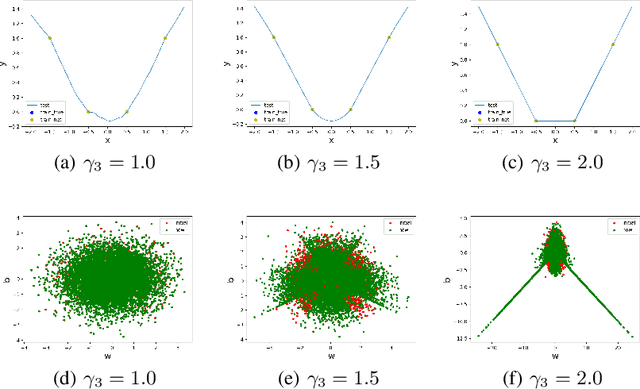
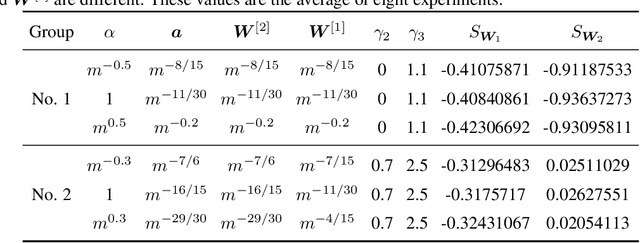
Substantial work indicates that the dynamics of neural networks (NNs) is closely related to their initialization of parameters. Inspired by the phase diagram for two-layer ReLU NNs with infinite width (Luo et al., 2021), we make a step towards drawing a phase diagram for three-layer ReLU NNs with infinite width. First, we derive a normalized gradient flow for three-layer ReLU NNs and obtain two key independent quantities to distinguish different dynamical regimes for common initialization methods. With carefully designed experiments and a large computation cost, for both synthetic datasets and real datasets, we find that the dynamics of each layer also could be divided into a linear regime and a condensed regime, separated by a critical regime. The criteria is the relative change of input weights (the input weight of a hidden neuron consists of the weight from its input layer to the hidden neuron and its bias term) as the width approaches infinity during the training, which tends to $0$, $+\infty$ and $O(1)$, respectively. In addition, we also demonstrate that different layers can lie in different dynamical regimes in a training process within a deep NN. In the condensed regime, we also observe the condensation of weights in isolated orientations with low complexity. Through experiments under three-layer condition, our phase diagram suggests a complicated dynamical regimes consisting of three possible regimes, together with their mixture, for deep NNs and provides a guidance for studying deep NNs in different initialization regimes, which reveals the possibility of completely different dynamics emerging within a deep NN for its different layers.