 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoPE: Conditional image generation using Polynomial Expansions
Apr 11, 2021
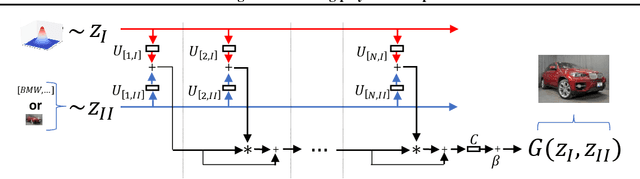


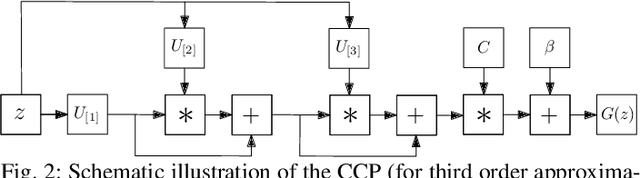
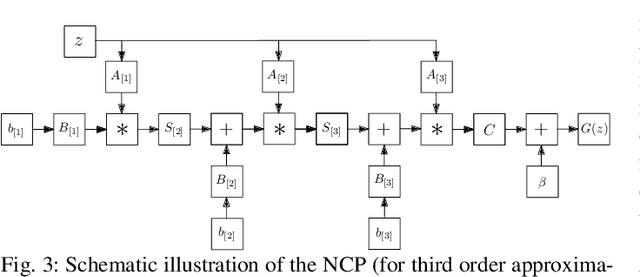
Generative modeling has evolved to a notable field of machine learning. Deep polynomial neural networks (PNNs) have demonstrated impressive results in unsupervised image generation, where the task is to map an input vector (i.e., noise) to a synthesized image. However, the success of PNNs has not been replicated in conditional generation tasks, such as super-resolution. Existing PNNs focus on single-variable polynomial expansions which do not fare well to two-variable inputs, i.e., the noise variable and the conditional variable. In this work, we introduce a general framework, called CoPE, that enables a polynomial expansion of two input variables and captures their auto- and cross-correlations. We exhibit how CoPE can be trivially augmented to accept an arbitrary number of input variables. CoPE is evaluated in five tasks (class-conditional generation, inverse problems, edges-to-image translation, image-to-image translation, attribute-guided generation) involving eight datasets. The thorough evaluation suggests that CoPE can be useful for tackling diverse conditional generation tasks.
Multilinear Latent Conditioning for Generating Unseen Attribute Combinations
Sep 09, 2020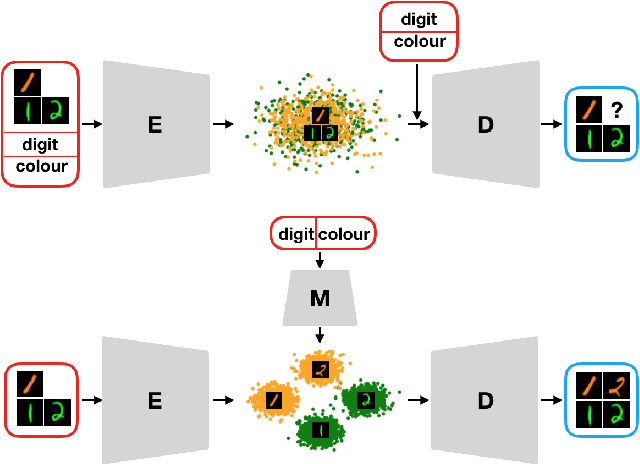
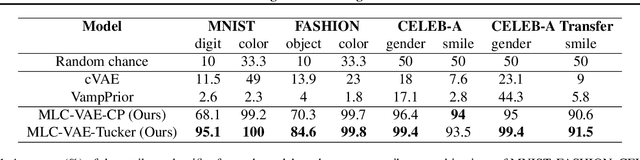

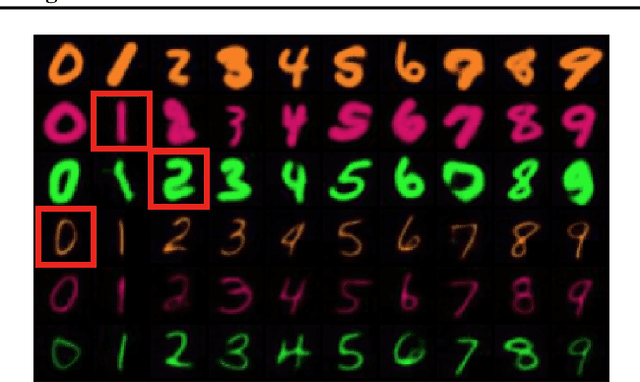
Deep generative models rely on their inductive bias to facilitate generalization, especially for problems with high dimensional data, like images. However, empirical studies have shown that variational autoencoders (VAE) and generative adversarial networks (GAN) lack the generalization ability that occurs naturally in human perception. For example, humans can visualize a woman smiling after only seeing a smiling man. On the contrary, the standard conditional VAE (cVAE) is unable to generate unseen attribute combinations. To this end, we extend cVAE by introducing a multilinear latent conditioning framework that captures the multiplicative interactions between the attributes. We implement two variants of our model and demonstrate their efficacy on MNIST, Fashion-MNIST and CelebA. Altogether, we design a novel conditioning framework that can be used with any architecture to synthesize unseen attribute combinations.
Deep Polynomial Neural Networks
Jun 20, 2020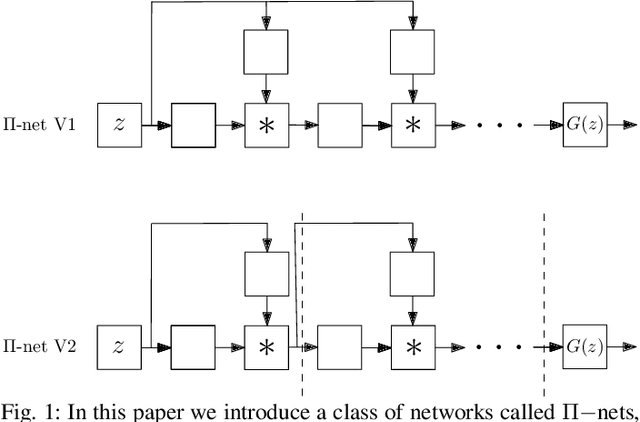

Deep Convolutional Neural Networks (DCNNs) are currently the method of choice both for generative, as well as for discriminative learning in computer vision and machine learning. The success of DCNNs can be attributed to the careful selection of their building blocks (e.g., residual blocks, rectifiers, sophisticated normalization schemes, to mention but a few). In this paper, we propose $\Pi$-Nets, a new class of DCNNs. $\Pi$-Nets are polynomial neural networks, i.e., the output is a high-order polynomial of the input. The unknown parameters, which are naturally represented by high-order tensors, are estimated through a collective tensor factorization with factors sharing. We introduce three tensor decompositions that significantly reduce the number of parameters and show how they can be efficiently implemented by hierarchical neural networks. We empirically demonstrate that $\Pi$-Nets are very expressive and they even produce good results without the use of non-linear activation functions in a large battery of tasks and signals, i.e., images, graphs, and audio. When used in conjunction with activation functions, $\Pi$-Nets produce state-of-the-art results in three challenging tasks, i.e. image generation, face verification and 3D mesh representation learning.
Enhancing Facial Data Diversity with Style-based Face Aging
Jun 06, 2020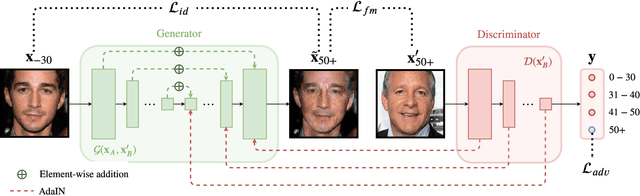
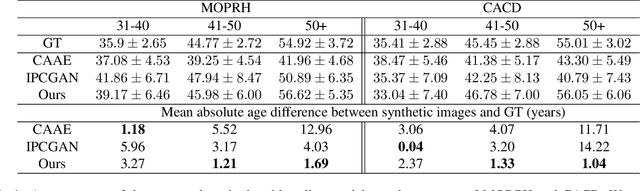


A significant limiting factor in training fair classifiers relates to the presence of dataset bias. In particular, face datasets are typically biased in terms of attributes such as gender, age, and race. If not mitigated, bias leads to algorithms that exhibit unfair behaviour towards such groups. In this work, we address the problem of increasing the diversity of face datasets with respect to age. Concretely, we propose a novel, generative style-based architecture for data augmentation that captures fine-grained aging patterns by conditioning on multi-resolution age-discriminative representations. By evaluating on several age-annotated datasets in both single- and cross-database experiments, we show that the proposed method outperforms state-of-the-art algorithms for age transfer, especially in the case of age groups that lie in the tails of the label distribution. We further show significantly increased diversity in the augmented datasets, outperforming all compared methods according to established metrics.
Investigating Bias in Deep Face Analysis: The KANFace Dataset and Empirical Study
May 15, 2020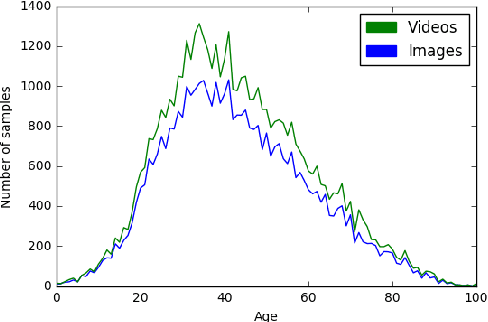
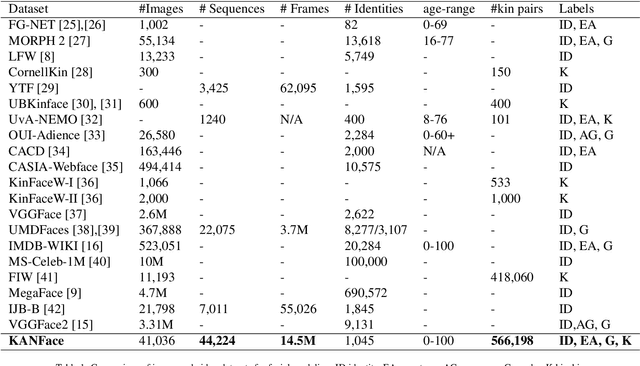

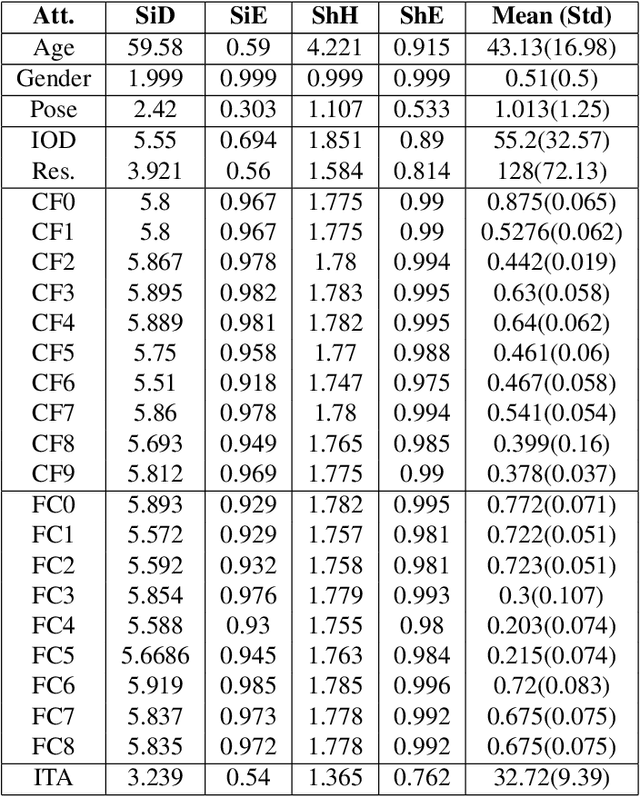
Deep learning-based methods have pushed the limits of the state-of-the-art in face analysis. However, despite their success, these models have raised concerns regarding their bias towards certain demographics. This bias is inflicted both by limited diversity across demographics in the training set, as well as the design of the algorithms. In this work, we investigate the demographic bias of deep learning models in face recognition, age estimation, gender recognition and kinship verification. To this end, we introduce the most comprehensive, large-scale dataset of facial images and videos to date. It consists of 40K still images and 44K sequences (14.5M video frames in total) captured in unconstrained, real-world conditions from 1,045 subjects. The data are manually annotated in terms of identity, exact age, gender and kinship. The performance of state-of-the-art models is scrutinized and demographic bias is exposed by conducting a series of experiments. Lastly, a method to debias network embeddings is introduced and tested on the proposed benchmarks.
$Π-$nets: Deep Polynomial Neural Networks
Mar 26, 2020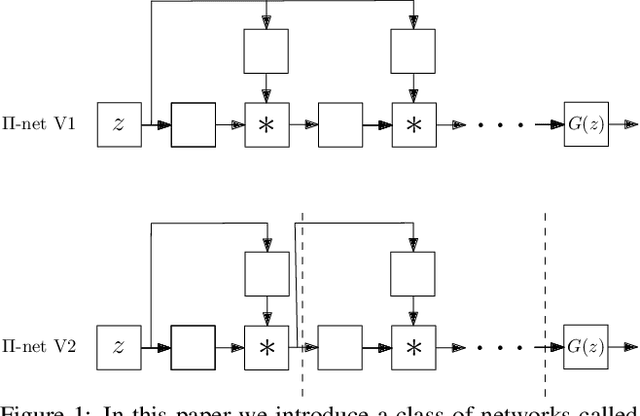
Deep Convolutional Neural Networks (DCNNs) is currently the method of choice both for generative, as well as for discriminative learning in computer vision and machine learning. The success of DCNNs can be attributed to the careful selection of their building blocks (e.g., residual blocks, rectifiers, sophisticated normalization schemes, to mention but a few). In this paper, we propose $\Pi$-Nets, a new class of DCNNs. $\Pi$-Nets are polynomial neural networks, i.e., the output is a high-order polynomial of the input. $\Pi$-Nets can be implemented using special kind of skip connections and their parameters can be represented via high-order tensors. We empirically demonstrate that $\Pi$-Nets have better representation power than standard DCNNs and they even produce good results without the use of non-linear activation functions in a large battery of tasks and signals, i.e., images, graphs, and audio. When used in conjunction with activation functions, $\Pi$-Nets produce state-of-the-art results in challenging tasks, such as image generation. Lastly, our framework elucidates why recent generative models, such as StyleGAN, improve upon their predecessors, e.g., ProGAN.
Speech-driven facial animation using polynomial fusion of features
Dec 12, 2019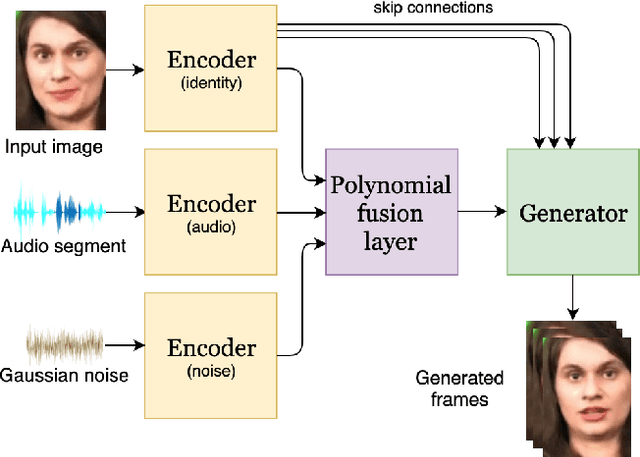
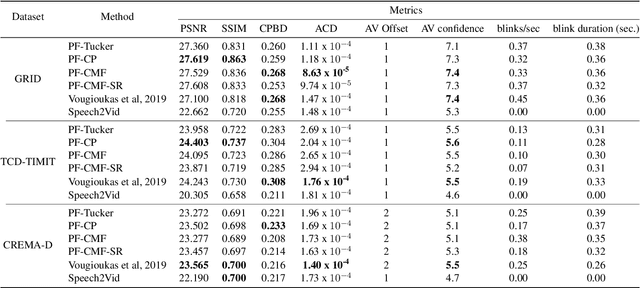
Speech-driven facial animation involves using a speech signal to generate realistic videos of talking faces. Recent deep learning approaches to facial synthesis rely on extracting low-dimensional representations and concatenating them, followed by a decoding step of the concatenated vector. This accounts for only first-order interactions of the features and ignores higher-order interactions. In this paper we propose a polynomial fusion layer that models the joint representation of the encodings by a higher-order polynomial, with the parameters modelled by a tensor decomposition. We demonstrate the the suitability of this approach through experiments on generated videos evaluated on a range of metrics on video quality, audiovisual synchronisation and generation of blinks.
PolyGAN: High-Order Polynomial Generators
Aug 19, 2019
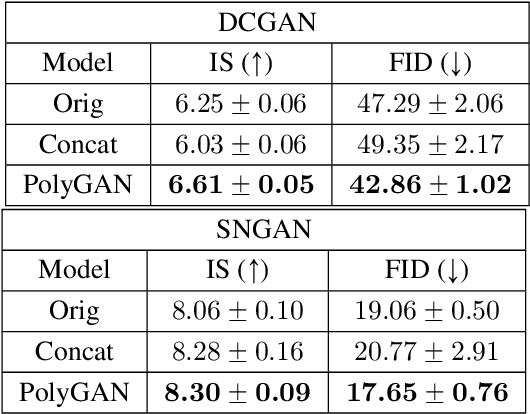
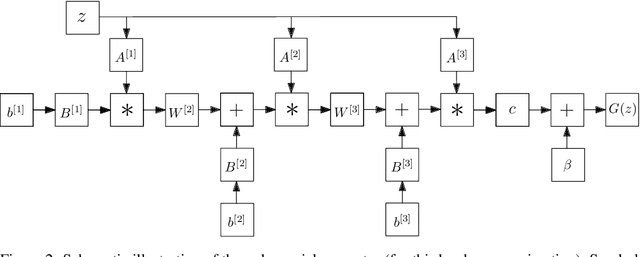
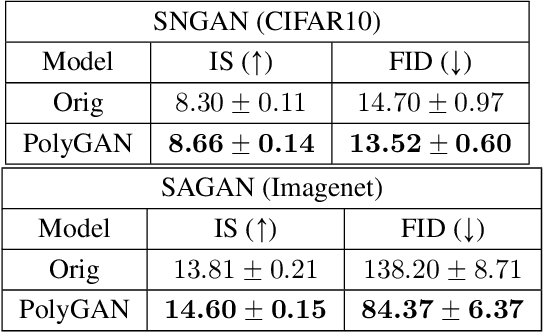
Generative Adversarial Networks (GANs) have become the gold standard when it comes to learning generative models that can describe intricate, high-dimensional distributions. Since their advent, numerous variations of GANs have been introduced in the literature, primarily focusing on utilization of novel loss functions, optimization/regularization strategies and architectures. In this work, we take an orthogonal approach to the above and turn our attention to the generator. We propose to model the data generator by means of a high-order polynomial using tensorial factors. We design a hierarchical decomposition of the polynomial and demonstrate how it can be efficiently implemented by a neural network. We show, for the first time, that by using our decomposition a GAN generator can approximate the data distribution by only using linear/convolution blocks without using any activation functions. Finally, we highlight that PolyGAN can be easily adapted and used along-side all major GAN architectures. In an extensive series of quantitative and qualitative experiments, PolyGAN improves upon the state-of-the-art by a significant margin.
Efficient N-Dimensional Convolutions via Higher-Order Factorization
Jun 14, 2019

With the unprecedented success of deep convolutional neural networks came the quest for training always deeper networks. However, while deeper neural networks give better performance when trained appropriately, that depth also translates in memory and computation heavy models, typically with tens of millions of parameters. Several methods have been proposed to leverage redundancies in the network to alleviate this complexity. Either a pretrained network is compressed, e.g. using a low-rank tensor decomposition, or the architecture of the network is directly modified to be more effective. In this paper, we study both approaches in a unified framework, under the lens of tensor decompositions. We show how tensor decomposition applied to the convolutional kernel relates to efficient architectures such as MobileNet. Moreover, we propose a tensor-based method for efficient higher order convolutions, which can be used as a plugin replacement for N-dimensional convolutions. We demonstrate their advantageous properties both theoretically and empirically for image classification, for both 2D and 3D convolutional networks.
Adversarial Learning of Disentangled and Generalizable Representations for Visual Attributes
Apr 18, 2019
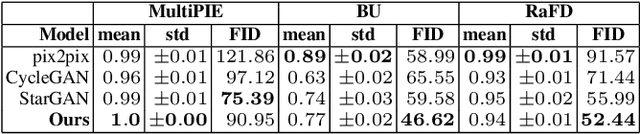
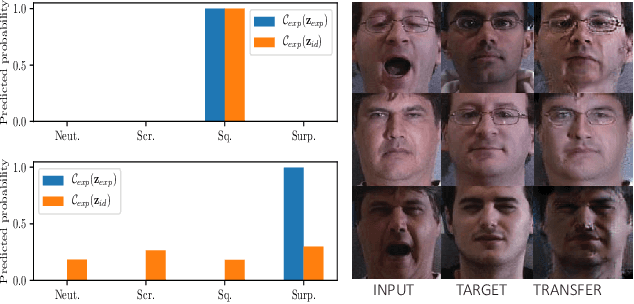
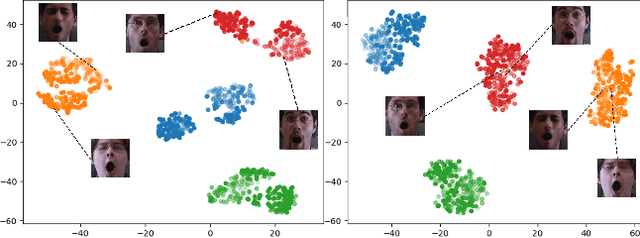
Recently, a multitude of methods for image-to-image translation has demonstrated impressive results on problems such as multi-domain or multi-attribute transfer. The vast majority of such works leverages the strengths of adversarial learning in tandem with deep convolutional autoencoders to achieve realistic results by well-capturing the target data distribution. Nevertheless, the most prominent representatives of this class of methods do not facilitate semantic structure in the latent space, and usually rely on domain labels for test-time transfer. This leads to rigid models that are unable to capture the variance of each domain label. In this light, we propose a novel adversarial learning method that (i) facilitates latent structure by disentangling sources of variation based on a novel cost function and (ii) encourages learning generalizable, continuous and transferable latent codes that can be utilized for tasks such as unpaired multi-domain image transfer and synthesis, without requiring labelled test data. The resulting representations can be combined in arbitrary ways to generate novel hybrid imagery, as for example generating mixtures of identities. We demonstrate the merits of the proposed method by a set of qualitative and quantitative experiments on popular databases, where our method clearly outperforms other, state-of-the-art methods. Code for reproducing our results can be found at: https://github.com/james-oldfield/adv-attribute-disentanglement