 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA contemporary science map through the lens of IEEE and ACM periodicals
Apr 28, 2026ACM and IEEE are the two premier associations on computing and electrical/electronics engineering which publish and organize the great majority of periodicals and conferences, respectively, serving these disciplines. Science is a constantly evolving process, and these publication fora are expected to follow the trends. In this article, we focus on the periodicals published by the two associations and seek to detect and/or confirm any contemporary science trends as these are reflected to the periodical titles established recently. Our study is rather qualitative than quantitative, aiming at revealing patterns immediately comprehensible and validatable by the reader. Among the most notable patterns, we see a growing preference of both associations for the open access mode of publication; we also observe ACM's orientation toward AI-focused periodicals, and most importantly, a significant theme overlap among periodicals of the same association and this is valid for both ACM and IEEE.
Utilizing Large Language Models for Machine Learning Explainability
Oct 08, 2025



This study explores the explainability capabilities of large language models (LLMs), when employed to autonomously generate machine learning (ML) solutions. We examine two classification tasks: (i) a binary classification problem focused on predicting driver alertness states, and (ii) a multilabel classification problem based on the yeast dataset. Three state-of-the-art LLMs (i.e. OpenAI GPT, Anthropic Claude, and DeepSeek) are prompted to design training pipelines for four common classifiers: Random Forest, XGBoost, Multilayer Perceptron, and Long Short-Term Memory networks. The generated models are evaluated in terms of predictive performance (recall, precision, and F1-score) and explainability using SHAP (SHapley Additive exPlanations). Specifically, we measure Average SHAP Fidelity (Mean Squared Error between SHAP approximations and model outputs) and Average SHAP Sparsity (number of features deemed influential). The results reveal that LLMs are capable of producing effective and interpretable models, achieving high fidelity and consistent sparsity, highlighting their potential as automated tools for interpretable ML pipeline generation. The results show that LLMs can produce effective, interpretable pipelines with high fidelity and consistent sparsity, closely matching manually engineered baselines.
RELINE: Point-of-Interest Recommendations using Multiple Network Embeddings
Feb 02, 2019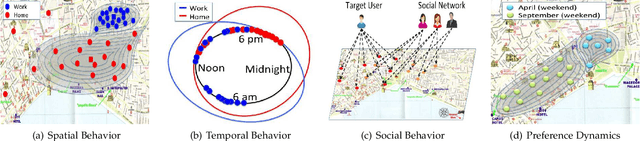

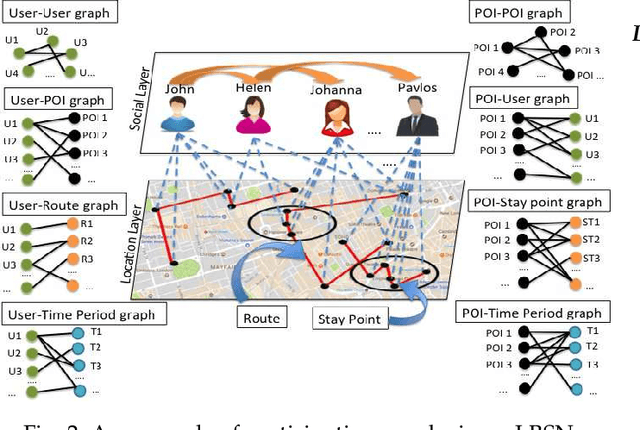

The rapid growth of users' involvement in Location-Based Social Networks (LBSNs) has led to the expeditious growth of the data on a global scale. The need of accessing and retrieving relevant information close to users' preferences is an open problem which continuously raises new challenges for recommendation systems. The exploitation of Points-of-Interest (POIs) recommendation by existing models is inadequate due to the sparsity and the cold start problems. To overcome these problems many models were proposed in the literature, but most of them ignore important factors such as: geographical proximity, social influence, or temporal and preference dynamics, which tackle their accuracy while personalize their recommendations. In this work, we investigate these problems and present a unified model that jointly learns users and POI dynamics. Our proposal is termed RELINE (REcommendations with muLtIple Network Embeddings). More specifically, RELINE captures: i) the social, ii) the geographical, iii) the temporal influence, and iv) the users' preference dynamics, by embedding eight relational graphs into one shared latent space. We have evaluated our approach against state-of-the-art methods with three large real-world datasets in terms of accuracy. Additionally, we have examined the effectiveness of our approach against the cold-start problem. Performance evaluation results demonstrate that significant performance improvement is achieved in comparison to existing state-of-the-art methods.