 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Abundance Maps for Unsupervised Super-Resolution of Hyperspectral Remote Sensing Images
Jan 30, 2026Hyperspectral single image super-resolution (HS-SISR) aims to enhance the spatial resolution of hyperspectral images to fully exploit their spectral information. While considerable progress has been made in this field, most existing methods are supervised and require ground truth data for training-data that is often unavailable in practice. To overcome this limitation, we propose a novel unsupervised training framework for HS-SISR, based on synthetic abundance data. The approach begins by unmixing the hyperspectral image into endmembers and abundances. A neural network is then trained to perform abundance super-resolution using synthetic abundances only. These synthetic abundance maps are generated from a dead leaves model whose characteristics are inherited from the low-resolution image to be super-resolved. This trained network is subsequently used to enhance the spatial resolution of the original image's abundances, and the final super-resolution hyperspectral image is reconstructed by combining them with the endmembers. Experimental results demonstrate both the training value of the synthetic data and the effectiveness of the proposed method.
Super-résolution non supervisée d'images hyperspectrales de télédétection utilisant un entraînement entièrement synthétique
Jan 30, 2026Hyperspectral single image super-resolution (SISR) aims to enhance spatial resolution while preserving the rich spectral information of hyperspectral images. Most existing methods rely on supervised learning with high-resolution ground truth data, which is often unavailable in practice. To overcome this limitation, we propose an unsupervised learning approach based on synthetic abundance data. The hyperspectral image is first decomposed into endmembers and abundance maps through hyperspectral unmixing. A neural network is then trained to super-resolve these maps using data generated with the dead leaves model, which replicates the statistical properties of real abundances. The final super-resolution hyperspectral image is reconstructed by recombining the super-resolved abundance maps with the endmembers. Experimental results demonstrate the effectiveness of our method and the relevance of synthetic data for training.
Unsupervised Super-Resolution of Hyperspectral Remote Sensing Images Using Fully Synthetic Training
Jan 23, 2026Considerable work has been dedicated to hyperspectral single image super-resolution to improve the spatial resolution of hyperspectral images and fully exploit their potential. However, most of these methods are supervised and require some data with ground truth for training, which is often non-available. To overcome this problem, we propose a new unsupervised training strategy for the super-resolution of hyperspectral remote sensing images, based on the use of synthetic abundance data. Its first step decomposes the hyperspectral image into abundances and endmembers by unmixing. Then, an abundance super-resolution neural network is trained using synthetic abundances, which are generated using the dead leaves model in such a way as to faithfully mimic real abundance statistics. Next, the spatial resolution of the considered hyperspectral image abundances is increased using this trained network, and the high resolution hyperspectral image is finally obtained by recombination with the endmembers. Experimental results show the training potential of the synthetic images, and demonstrate the method effectiveness.
VibrantLeaves: A principled parametric image generator for training deep restoration models
Apr 14, 2025

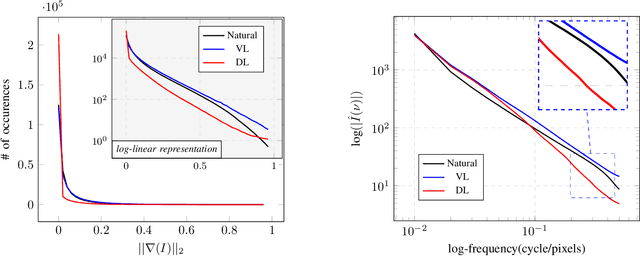

Even though Deep Neural Networks are extremely powerful for image restoration tasks, they have several limitations. They are poorly understood and suffer from strong biases inherited from the training sets. One way to address these shortcomings is to have a better control over the training sets, in particular by using synthetic sets. In this paper, we propose a synthetic image generator relying on a few simple principles. In particular, we focus on geometric modeling, textures, and a simple modeling of image acquisition. These properties, integrated in a classical Dead Leaves model, enable the creation of efficient training sets. Standard image denoising and super-resolution networks can be trained on such datasets, reaching performance almost on par with training on natural image datasets. As a first step towards explainability, we provide a careful analysis of the considered principles, identifying which image properties are necessary to obtain good performances. Besides, such training also yields better robustness to various geometric and radiometric perturbations of the test sets.
Multispectral Texture Synthesis using RGB Convolutional Neural Networks
Oct 21, 2024State-of-the-art RGB texture synthesis algorithms rely on style distances that are computed through statistics of deep features. These deep features are extracted by classification neural networks that have been trained on large datasets of RGB images. Extending such synthesis methods to multispectral images is not straightforward, since the pre-trained networks are designed for and have been trained on RGB images. In this work, we propose two solutions to extend these methods to multispectral imaging. Neither of them require additional training of the neural network from which the second order neural statistics are extracted. The first one consists in optimizing over batches of random triplets of spectral bands throughout training. The second one projects multispectral pixels onto a 3 dimensional space. We further explore the benefit of a color transfer operation upstream of the projection to avoid the potentially abnormal color distributions induced by the projection. Our experiments compare the performances of the various methods through different metrics. We demonstrate that they can be used to perform exemplar-based texture synthesis, achieve good visual quality and comes close to state-of-the art methods on RGB bands.
Diffusion-based image inpainting with internal learning
Jun 06, 2024Diffusion models are now the undisputed state-of-the-art for image generation and image restoration. However, they require large amounts of computational power for training and inference. In this paper, we propose lightweight diffusion models for image inpainting that can be trained on a single image, or a few images. We show that our approach competes with large state-of-the-art models in specific cases. We also show that training a model on a single image is particularly relevant for image acquisition modality that differ from the RGB images of standard learning databases. We show results in three different contexts: texture images, line drawing images, and materials BRDF, for which we achieve state-of-the-art results in terms of realism, with a computational load that is greatly reduced compared to concurrent methods.
A Compact and Semantic Latent Space for Disentangled and Controllable Image Editing
Dec 13, 2023Recent advances in the field of generative models and in particular generative adversarial networks (GANs) have lead to substantial progress for controlled image editing, especially compared with the pre-deep learning era. Despite their powerful ability to apply realistic modifications to an image, these methods often lack properties like disentanglement (the capacity to edit attributes independently). In this paper, we propose an auto-encoder which re-organizes the latent space of StyleGAN, so that each attribute which we wish to edit corresponds to an axis of the new latent space, and furthermore that the latent axes are decorrelated, encouraging disentanglement. We work in a compressed version of the latent space, using Principal Component Analysis, meaning that the parameter complexity of our autoencoder is reduced, leading to short training times ($\sim$ 45 mins). Qualitative and quantitative results demonstrate the editing capabilities of our approach, with greater disentanglement than competing methods, while maintaining fidelity to the original image with respect to identity. Our autoencoder architecture simple and straightforward, facilitating implementation.
Infusion: Internal Diffusion for Video Inpainting
Nov 02, 2023Video inpainting is the task of filling a desired region in a video in a visually convincing manner. It is a very challenging task due to the high dimensionality of the signal and the temporal consistency required for obtaining convincing results. Recently, diffusion models have shown impressive results in modeling complex data distributions, including images and videos. Diffusion models remain nonetheless very expensive to train and perform inference with, which strongly restrict their application to video. We show that in the case of video inpainting, thanks to the highly auto-similar nature of videos, the training of a diffusion model can be restricted to the video to inpaint and still produce very satisfying results. This leads us to adopt an internal learning approch, which also allows for a greatly reduced network size. We call our approach "Infusion": an internal learning algorithm for video inpainting through diffusion. Due to our frugal network, we are able to propose the first video inpainting approach based purely on diffusion. Other methods require supporting elements such as optical flow estimation, which limits their performance in the case of dynamic textures for example. We introduce a new method for efficient training and inference of diffusion models in the context of internal learning. We split the diffusion process into different learning intervals which greatly simplifies the learning steps. We show qualititative and quantitative results, demonstrating that our method reaches state-of-the-art performance, in particular in the case of dynamic backgrounds and textures.
A statistically constrained internal method for single image super-resolution
Feb 03, 2023



Deep learning based methods for single-image super-resolution (SR) have drawn a lot of attention lately. In particular, various papers have shown that the learning stage can be performed on a single image, resulting in the so-called internal approaches. The SinGAN method is one of these contributions, where the distribution of image patches is learnt on the image at hand and propagated at finer scales. Now, there are situations where some statistical a priori can be assumed for the final image. In particular, many natural phenomena yield images having power law Fourier spectrum, such as clouds and other texture images. In this work, we show how such a priori information can be integrated into an internal super-resolution approach, by constraining the learned up-sampling procedure of SinGAN. We consider various types of constraints, related to the Fourier power spectrum, the color histograms and the consistency of the upsampling scheme. We demonstrate on various experiments that these constraints are indeed satisfied, but also that some perceptual quality measures can be improved by the proposed approach.
A geometrically aware auto-encoder for multi-texture synthesis
Feb 03, 2023We propose an auto-encoder architecture for multi-texture synthesis. The approach relies on both a compact encoder accounting for second order neural statistics and a generator incorporating adaptive periodic content. Images are embedded in a compact and geometrically consistent latent space, where the texture representation and its spatial organisation are disentangled. Texture synthesis and interpolation tasks can be performed directly from these latent codes. Our experiments demonstrate that our model outperforms state-of-the-art feed-forward methods in terms of visual quality and various texture related metrics.