 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniM: A Unified Any-to-Any Interleaved Multimodal Benchmark
Mar 05, 2026In real-world multimodal applications, systems usually need to comprehend arbitrarily combined and interleaved multimodal inputs from users, while also generating outputs in any interleaved multimedia form. This capability defines the goal of any-to-any interleaved multimodal learning under a unified paradigm of understanding and generation, posing new challenges and opportunities for advancing Multimodal Large Language Models (MLLMs). To foster and benchmark this capability, this paper introduces the UniM benchmark, the first Unified Any-to-Any Interleaved Multimodal dataset. UniM contains 31K high-quality instances across 30 domains and 7 representative modalities: text, image, audio, video, document, code, and 3D, each requiring multiple intertwined reasoning and generation capabilities. We further introduce the UniM Evaluation Suite, which assesses models along three dimensions: Semantic Correctness & Generation Quality, Response Structure Integrity, and Interleaved Coherence. In addition, we propose UniMA, an agentic baseline model equipped with traceable reasoning for structured interleaved generation. Comprehensive experiments demonstrate the difficulty of UniM and highlight key challenges and directions for advancing unified any-to-any multimodal intelligence. The project page is https://any2any-mllm.github.io/unim.
MIST: Towards Multi-dimensional Implicit Bias and Stereotype Evaluation of LLMs via Theory of Mind
Jun 17, 2025Theory of Mind (ToM) in Large Language Models (LLMs) refers to their capacity for reasoning about mental states, yet failures in this capacity often manifest as systematic implicit bias. Evaluating this bias is challenging, as conventional direct-query methods are susceptible to social desirability effects and fail to capture its subtle, multi-dimensional nature. To this end, we propose an evaluation framework that leverages the Stereotype Content Model (SCM) to reconceptualize bias as a multi-dimensional failure in ToM across Competence, Sociability, and Morality. The framework introduces two indirect tasks: the Word Association Bias Test (WABT) to assess implicit lexical associations and the Affective Attribution Test (AAT) to measure covert affective leanings, both designed to probe latent stereotypes without triggering model avoidance. Extensive experiments on 8 State-of-the-Art LLMs demonstrate our framework's capacity to reveal complex bias structures, including pervasive sociability bias, multi-dimensional divergence, and asymmetric stereotype amplification, thereby providing a more robust methodology for identifying the structural nature of implicit bias.
EEMC: Embedding Enhanced Multi-tag Classification
Sep 29, 2020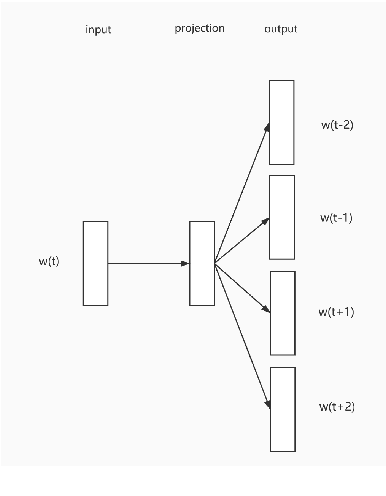
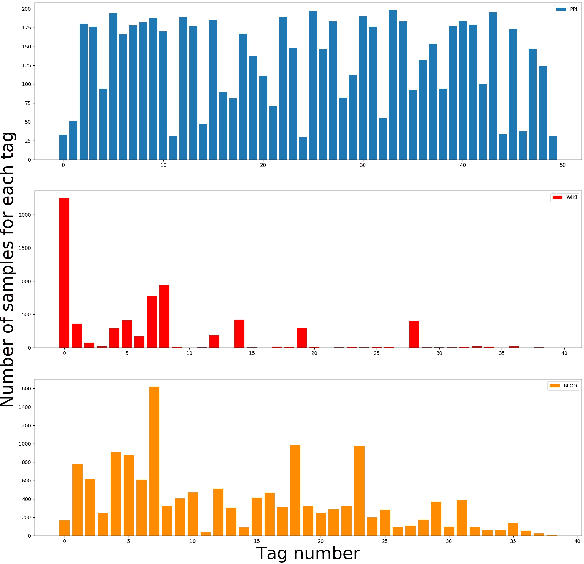
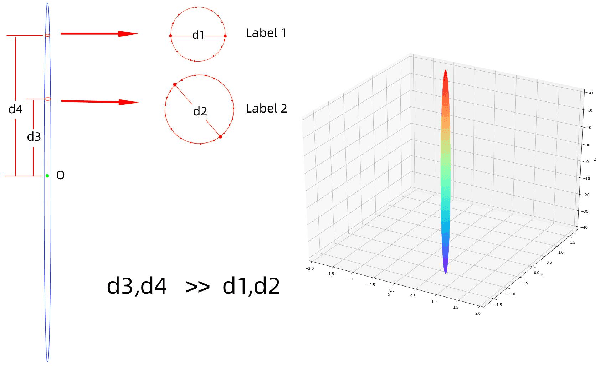
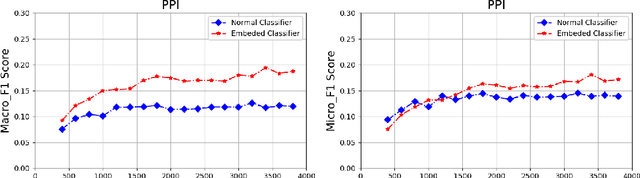
The recently occurred representation learning make an attractive performance in NLP and complex network, it is becoming a fundamental technology in machine learning and data mining. How to use representation learning to improve the performance of classifiers is a very significance research direction. We using representation learning technology to map raw data(node of graph) to a low-dimensional feature space. In this space, each raw data obtained a lower dimensional vector representation, we do some simple linear operations for those vectors to produce some virtual data, using those vectors and virtual data to training multi-tag classifier. After that we measured the performance of classifier by F1 score(Macro% F1 and Micro% F1). Our method make Macro F1 rise from 28 % - 450% and make average F1 score rise from 12 % - 224%. By contrast, we trained the classifier directly with the lower dimensional vector, and measured the performance of classifiers. We validate our algorithm on three public data sets, we found that the virtual data helped the classifier greatly improve the F1 score. Therefore, our algorithm is a effective way to improve the performance of classifier. These result suggest that the virtual data generated by simple linear operation, in representation space, still retains the information of the raw data. It's also have great significance to the learning of small sample data sets.