 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyDRA: A Hybrid Dual-Mode Network for Closed- and Open-Set RFFI with Optimized VMD
Jul 16, 2025Device recognition is vital for security in wireless communication systems, particularly for applications like access control. Radio Frequency Fingerprint Identification (RFFI) offers a non-cryptographic solution by exploiting hardware-induced signal distortions. This paper proposes HyDRA, a Hybrid Dual-mode RF Architecture that integrates an optimized Variational Mode Decomposition (VMD) with a novel architecture based on the fusion of Convolutional Neural Networks (CNNs), Transformers, and Mamba components, designed to support both closed-set and open-set classification tasks. The optimized VMD enhances preprocessing efficiency and classification accuracy by fixing center frequencies and using closed-form solutions. HyDRA employs the Transformer Dynamic Sequence Encoder (TDSE) for global dependency modeling and the Mamba Linear Flow Encoder (MLFE) for linear-complexity processing, adapting to varying conditions. Evaluation on public datasets demonstrates state-of-the-art (SOTA) accuracy in closed-set scenarios and robust performance in our proposed open-set classification method, effectively identifying unauthorized devices. Deployed on NVIDIA Jetson Xavier NX, HyDRA achieves millisecond-level inference speed with low power consumption, providing a practical solution for real-time wireless authentication in real-world environments.
Topic Modeling the Hàn diăn Ancient Classics
Feb 02, 2017
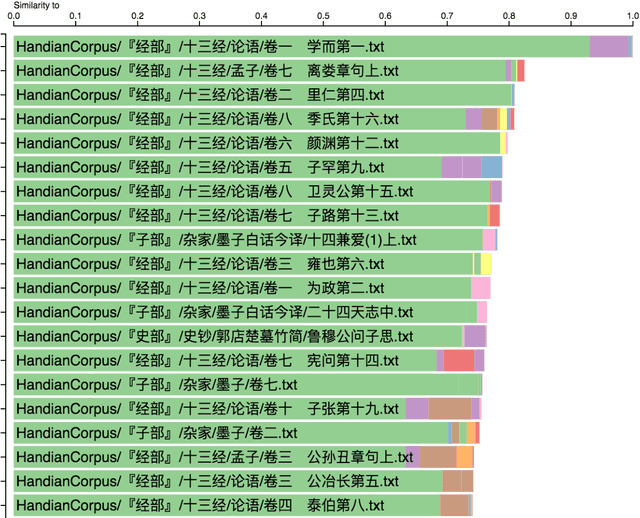
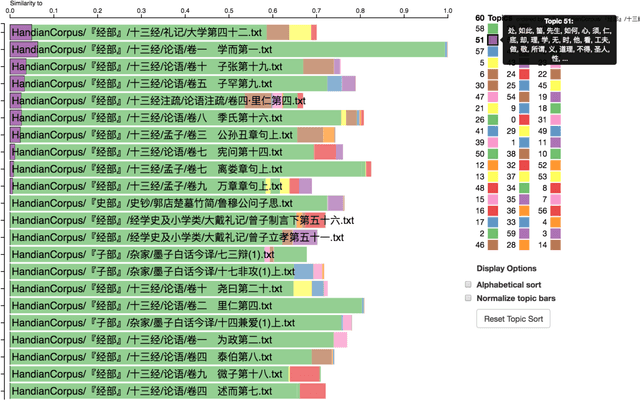
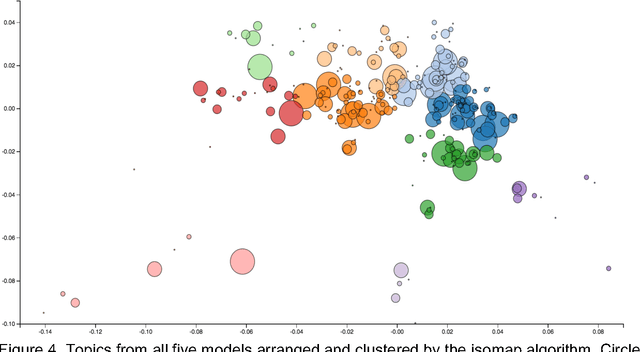
Ancient Chinese texts present an area of enormous challenge and opportunity for humanities scholars interested in exploiting computational methods to assist in the development of new insights and interpretations of culturally significant materials. In this paper we describe a collaborative effort between Indiana University and Xi'an Jiaotong University to support exploration and interpretation of a digital corpus of over 18,000 ancient Chinese documents, which we refer to as the "Handian" ancient classics corpus (H\`an di\u{a}n g\u{u} j\'i, i.e, the "Han canon" or "Chinese classics"). It contains classics of ancient Chinese philosophy, documents of historical and biographical significance, and literary works. We begin by describing the Digital Humanities context of this joint project, and the advances in humanities computing that made this project feasible. We describe the corpus and introduce our application of probabilistic topic modeling to this corpus, with attention to the particular challenges posed by modeling ancient Chinese documents. We give a specific example of how the software we have developed can be used to aid discovery and interpretation of themes in the corpus. We outline more advanced forms of computer-aided interpretation that are also made possible by the programming interface provided by our system, and the general implications of these methods for understanding the nature of meaning in these texts.