 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhoneme Boundary Detection using Learnable Segmental Features
Feb 16, 2020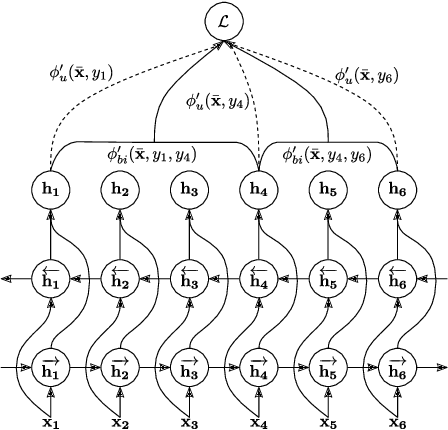
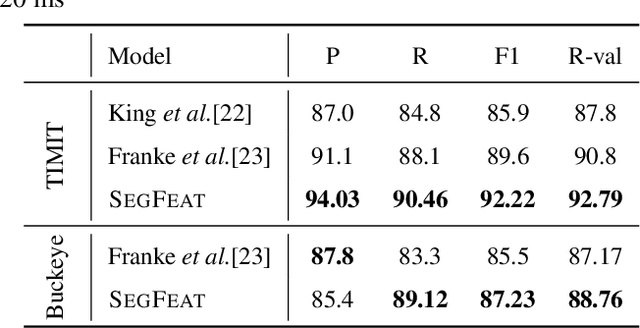
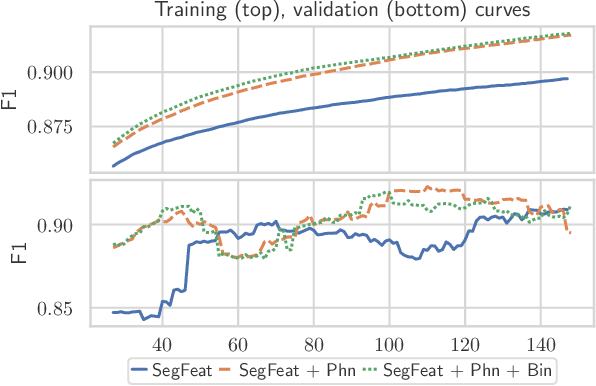
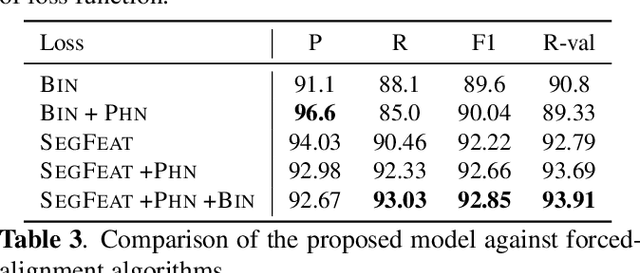
Phoneme boundary detection plays an essential first step for a variety of speech processing applications such as speaker diarization, speech science, keyword spotting, etc. In this work, we propose a neural architecture coupled with a parameterized structured loss function to learn segmental representations for the task of phoneme boundary detection. First, we evaluated our model when the spoken phonemes were not given as input. Results on the TIMIT and Buckeye corpora suggest that the proposed model is superior to the baseline models and reaches state-of-the-art performance in terms of F1 and R-value. We further explore the use of phonetic transcription as additional supervision and show this yields minor improvements in performance but substantially better convergence rates. We additionally evaluate the model on a Hebrew corpus and demonstrate such phonetic supervision can be beneficial in a multi-lingual setting.
Automatic Measurement of Pre-aspiration
Jun 15, 2017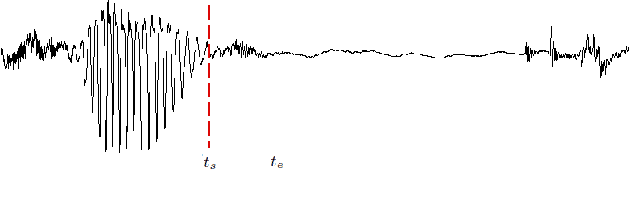

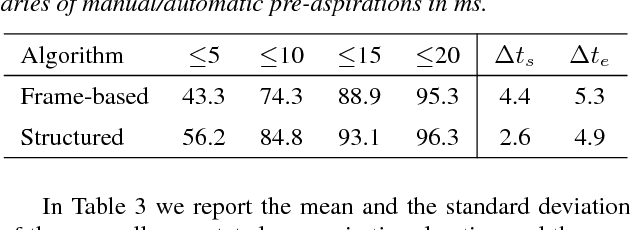
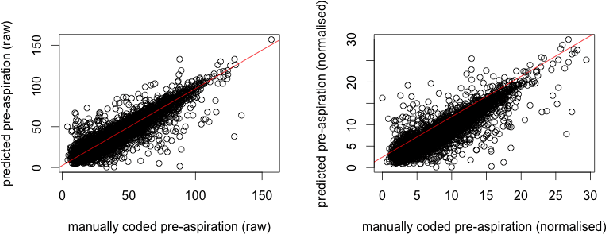
Pre-aspiration is defined as the period of glottal friction occurring in sequences of vocalic/consonantal sonorants and phonetically voiceless obstruents. We propose two machine learning methods for automatic measurement of pre-aspiration duration: a feedforward neural network, which works at the frame level; and a structured prediction model, which relies on manually designed feature functions, and works at the segment level. The input for both algorithms is a speech signal of an arbitrary length containing a single obstruent, and the output is a pair of times which constitutes the pre-aspiration boundaries. We train both models on a set of manually annotated examples. Results suggest that the structured model is superior to the frame-based model as it yields higher accuracy in predicting the boundaries and generalizes to new speakers and new languages. Finally, we demonstrate the applicability of our structured prediction algorithm by replicating linguistic analysis of pre-aspiration in Aberystwyth English with high correlation.