 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDying ReLU and Initialization: Theory and Numerical Examples
Mar 15, 2019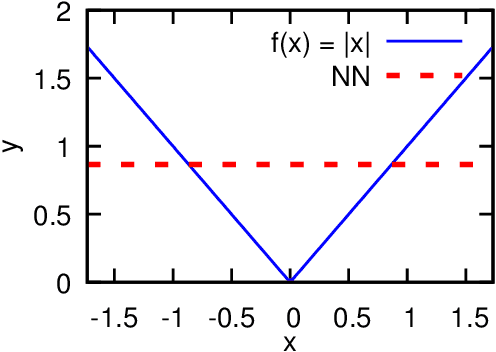
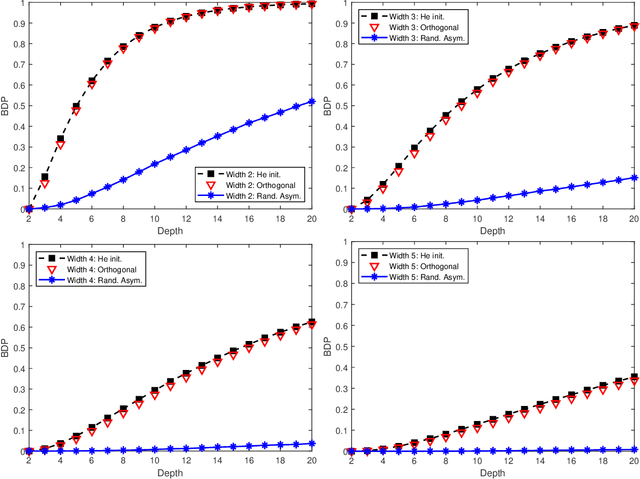
The dying ReLU refers to the problem when ReLU neurons become inactive and only output 0 for any input. There are many empirical and heuristic explanations on why ReLU neurons die. However, little is known about its theoretical analysis. In this paper, we rigorously prove that a deep ReLU network will eventually die in probability as the depth goes to infinite. Several methods have been proposed to alleviate the dying ReLU. Perhaps, one of the simplest treatments is to modify the initialization procedure. One common way of initializing weights and biases uses symmetric probability distributions, which suffers from the dying ReLU. We thus propose a new initialization procedure, namely, a randomized asymmetric initialization. We prove that the new initialization can effectively prevent the dying ReLU. All parameters required for the new initialization are theoretically designed. Numerical examples are provided to demonstrate the effectiveness of the new initialization procedure.
Collapse of Deep and Narrow Neural Nets
Aug 15, 2018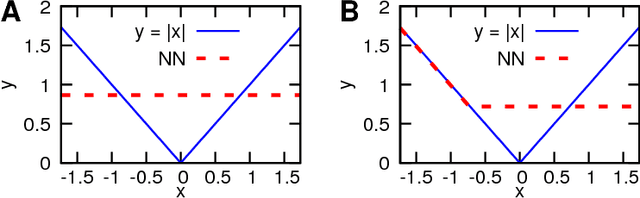
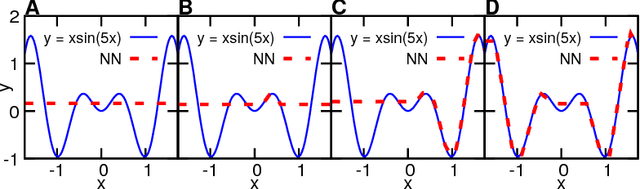
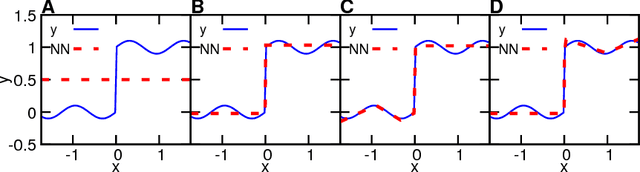
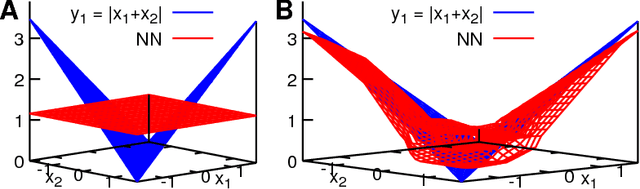
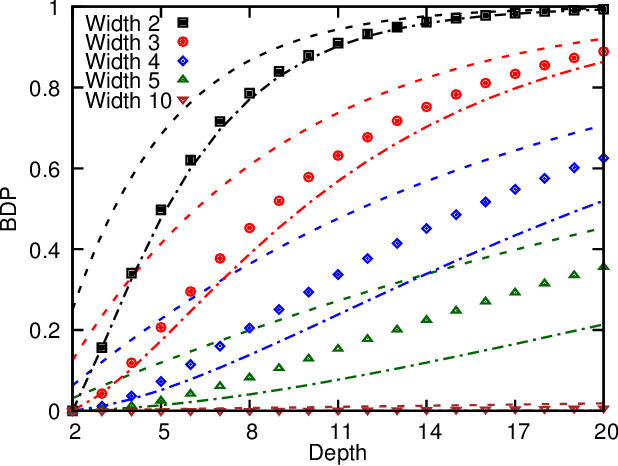
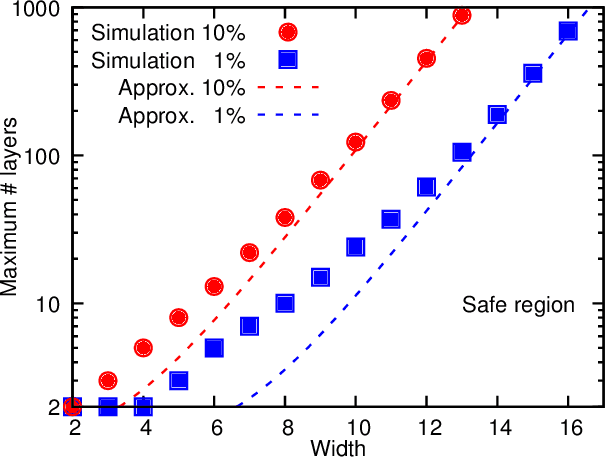
Recent theoretical work has demonstrated that deep neural networks have superior performance over shallow networks, but their training is more difficult, e.g., they suffer from the vanishing gradient problem. This problem can be typically resolved by the rectified linear unit (ReLU) activation. However, here we show that even for such activation, deep and narrow neural networks will converge to erroneous mean or median states of the target function depending on the loss with high probability. We demonstrate this collapse of deep and narrow neural networks both numerically and theoretically, and provide estimates of the probability of collapse. We also construct a diagram of a safe region of designing neural networks that avoid the collapse to erroneous states. Finally, we examine different ways of initialization and normalization that may avoid the collapse problem.