 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Backdoor Adversarial Unlearning through the Lens of Catastrophic Forgetting in Continual Learning
Jun 12, 2026Existing studies reveal that current backdoor defenses exhibit limited robustness and often fail against specific types of attacks. More concerningly, prevailing safety tuning strategies tend to provide only superficial safety protection, as they fall short of completely eliminating the backdoor effects. In this work, we present a novel formulation of backdoor learning and unlearning as a sequential, three-stage process from a continual learning perspective. Within this framework, we formally define complete backdoor unlearning and further derive the necessary conditions for achieving it based on the mechanism of catastrophic forgetting. Guided by these insights, we propose Blind Inversion-Backdoor Adversarial Unlearning (BI-BAU), which formulates the generation of adversarial examples satisfying the unlearning conditions as a blind inversion problem. We solve this by integrating the bi-level optimization process of adversarial training into an Expectation-Maximization (EM) algorithm framework to optimize the maximum a posteriori (MAP) objective. Furthermore, BI-BAU is extended to untargeted adversarial scenarios with unknown target classes, as well as to multi-modal contrastive learning tasks, enhancing its applicability to real-world deployment scenarios where pre-trained models may be compromised. Extensive experiments demonstrate that our method exhibits general applicability across a wide spectrum of backdoor attacks and can effectively and thoroughly eliminate the backdoor effects from a backdoor model.
From Parameters to Feature Space: Task Arithmetic for Backdoor Mitigation in Model Merging
Jun 10, 2026Model merging (MM) has gained significant attention as a cost-effective approach to integrate multiple task-specific models into a unified model. However, recent work reveals that MM is highly susceptible to backdoor attacks. Existing defenses based on task arithmetic often fail to eliminate backdoors without substantially degrading clean-task performance, owing to their reliance on direct parameter-space editing. To address this gap, we propose Linear Feature Path Minimization (LFPM), a backdoor mitigation framework for model merging, which introduces an anti-backdoor task vector into the backdoored merged model. Unlike prior approaches, LFPM formulates the backdoor robustness of the merged model from a unified feature-space perspective under the Cross-Task Linearity (CTL) framework, which leverages the approximate linearity of features across tasks. This perspective guides the optimization of the anti-backdoor task to suppress backdoors while preserving clean-task performance. Furthermore, we introduce an effective optimization mechanism based on gradient accumulation and loss path-integral, ensuring robust backdoor suppression along the interpolation path. Extensive experiments demonstrate that LFPM consistently exhibits strong robustness against backdoor attacks in both full fine-tuning and Parameter-Efficient Fine-Tuning (PEFT) settings.
CDH-Bench: A Commonsense-Driven Hallucination Benchmark for Evaluating Visual Fidelity in Vision-Language Models
Apr 01, 2026Vision-language models (VLMs) achieve strong performance on many benchmarks, yet a basic reliability question remains underexplored: when visual evidence conflicts with commonsense, do models follow what is shown or what commonsense suggests? A characteristic failure in this setting is that the model overrides visual evidence and outputs the commonsense alternative. We term this phenomenon \textbf{commonsense-driven hallucination} (CDH). To evaluate it, we introduce \textbf{CDH-Bench}, a benchmark designed to create explicit \textbf{visual evidence--commonsense conflicts}. CDH-Bench covers three dimensions: \textit{counting anomalies}, \textit{relational anomalies}, and \textit{attribute anomalies}. We evaluate frontier VLMs under \textit{binary Question Answering (QA)} and \textit{multiple-choice QA}, and report metrics including \textit{Counterfactual Accuracy} (CF-Acc), \textit{Commonsense Accuracy} (CS-Acc), \textit{Counterfactual Accuracy Drop} (CFAD), \textit{Commonsense Collapse Rate} (CCR), and \textit{Relative Prior Dependency} (RPD). Results show that even strong models remain vulnerable to prior-driven normalization under visual evidence--commonsense conflict. CDH-Bench provides a controlled diagnostic of visual fidelity under visual evidence--commonsense conflict.
BAMBO: Construct Ability and Efficiency LLM Pareto Set via Bayesian Adaptive Multi-objective Block-wise Optimization
Dec 12, 2025



Constructing a Pareto set is pivotal for navigating the capability-efficiency trade-offs in Large Language Models (LLMs); however, existing merging techniques remain inadequate for this task. Coarse-grained, model-level methods yield only a sparse set of suboptimal solutions, while fine-grained, layer-wise approaches suffer from the "curse of dimensionality," rendering the search space computationally intractable. To resolve this dichotomy, we propose BAMBO (Bayesian Adaptive Multi-objective Block-wise Optimization), a novel framework that automatically constructs the LLM Pareto set. BAMBO renders the search tractable by introducing a Hybrid Optimal Block Partitioning strategy. Formulated as a 1D clustering problem, this strategy leverages a dynamic programming approach to optimally balance intra-block homogeneity and inter-block information distribution, thereby dramatically reducing dimensionality without sacrificing critical granularity. The entire process is automated within an evolutionary loop driven by the q-Expected Hypervolume Improvement (qEHVI) acquisition function. Experiments demonstrate that BAMBO discovers a superior and more comprehensive Pareto frontier than baselines, enabling agile model selection tailored to diverse operational constraints. Code is available at: https://github.com/xin8coder/BAMBO.
Community-based 3-SAT Formulas with a Predefined Solution
Feb 26, 2019
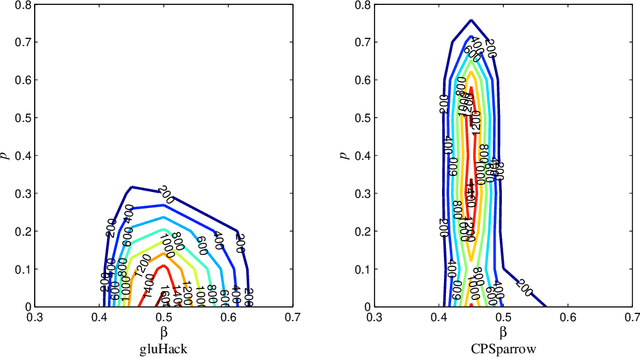
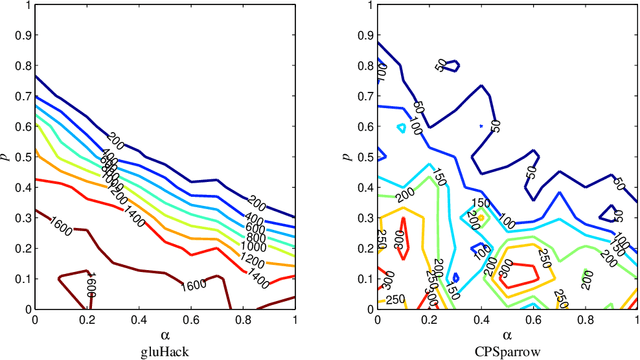
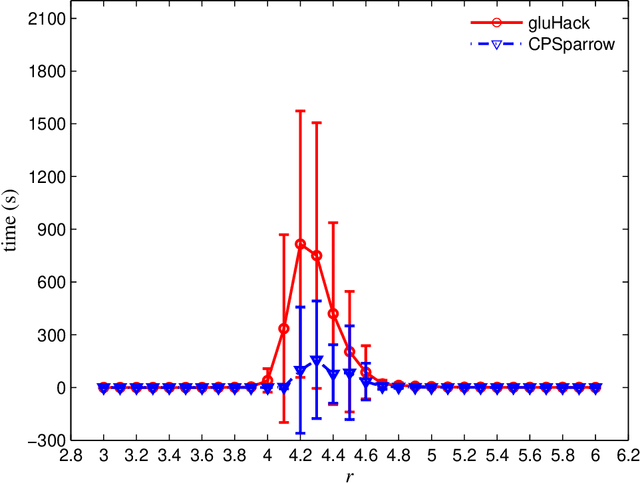
It is crucial to generate crafted SAT formulas with predefined solutions for the testing and development of SAT solvers since many SAT formulas from real-world applications have solutions. Although some generating algorithms have been proposed to generate SAT formulas with predefined solutions, community structures of SAT formulas are not considered. We propose a 3-SAT formula generating algorithm that not only guarantees the existence of a predefined solution, but also simultaneously considers community structures and clause distributions. The proposed 3-SAT formula generating algorithm controls the quality of community structures through controlling (1) the number of clauses whose variables have a common community, which we call intra-community clauses, and (2) the number of variables that only belong to one community, which we call intra-community variables. To study the combined effect of community structures and clause distributions on the hardness of SAT formulas, we measure solving runtimes of two solvers, gluHack (a leading CDCL solver) and CPSparrow (a leading SLS solver), on the generated SAT formulas under different groups of parameter settings. Through extensive experiments, we obtain some noteworthy observations on the SAT formulas generated by the proposed algorithm: (1) The community structure has little or no effects on the hardness of SAT formulas with regard to CPSparrow but a strong effect with regard to gluHack. (2) Only when the proportion of true literals in a SAT formula in terms of the predefined solution is 0.5, SAT formulas are hard-to-solve with regard to gluHack; when this proportion is below 0.5, SAT formulas are hard-to-solve with regard to CPSparrow. (3) When the ratio of the number of clauses to that of variables is around 4.25, the SAT formulas are hard-to-solve with regard to both gluHack and CPSparrow.