 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrain-Prompt Injection: A Route-Safety Audit for BCI-LLM Agents
Jun 08, 2026BCI-to-agent pipelines turn decoded neural activity into an authorization channel for tool-use agents, exposing a new attack surface we call \emph{brain-prompt injection}: signal-side perturbations, context-only injections, and adaptive dual-decoder attacks can all change the routed action while EEG-side or text-side monitors remain blind. Route safety in this stack depends on what the audit log can observe, not on decoder accuracy or agreement alone. We define a Route-Safety Audit Contract: a minimal log schema, denominator hierarchy, and endpoint specification, and prove an audit-schema separation theorem together with a C3 attacked-dependence decomposition; clean agreement and marginal robustness do not identify the joint term that controls C3 routing. As a calibration layer on top of the contract, we apply split-conformal calibration to a non-oracle EEG confirmation channel and report the resulting false-accept frontier under an explicit threat-archetype matrix. We instantiate the contract on EEGMMI native left/right command-control over 5{,}400 events, harmless tool stubs, and seed/case denominators. Provenance blocks C2 routes ($0.000$); agreement-plus-provenance routes C3 flips ($1.000$); confirmation-plus-provenance routes them ($0.000$). The conformal frontier reaches FAR $0.000$ at clean utility $0.150$ for $α=.005$ and FAR $0.119$ at clean utility $0.452$ for $α=.10$ under acquisition isolation; an attacker-controllable confirmation channel breaks the bound to $\approx\!1$. Subject-cluster bootstrap confirms these intervals on $60$ subjects; cross-architecture (TinyEEGNet, EEGNetV4) and capacity-sweep results show within-regime saturation. Mediation and confirmation reduce risk; they are not intent certificates.
Pretrained, Frozen, Still Leaking: Auditing Cross-Encoder Attribute Transfer in EEG Foundation Models
Jun 08, 2026EEG foundation-model releases are usually audited one endpoint at a time: raw-reconstruction, membership inference, identity linkage, or DP-SGD on the downstream head. We audit the same released embeddings under all four endpoints jointly, on BIOT, LaBraM, and EEGPT, and show that each single-endpoint audit clears releases that still leak spectral attributes. The decisive evidence is a cross-encoder transfer audit: a single ridge attribute decoder learned from one frozen encoder transfers, via a fitted linear bridge, to held-out-subject test splits of every other encoder, with subject-disjoint matched-control 95% CI lower bound at least 0.081 across all six BIOT/LaBraM/EEGPT directions. We prove a sufficient condition: two encoders sharing a nontrivial attribute-coordinate projector overlap beta admit a chained ridge bridge attacker with centered-gain lower bound sqrt(beta/(1+tau^2)) - eps_br - rho_0, and back-solve beta in [0.008, 0.198]. To turn the joint audit into a deployment-readable decision rule we introduce an audit-endpoint disagreement score (AEDS), prove sufficient conditions for its positivity, and bootstrap-calibrate it per cell; AEDS is positive in all eight matched-CI cells (BIOT/LaBraM/EEGPT on EEGMMI; LaBraM on Sleep-EDF, 54-channel LIMO, CHB-MIT pediatric scalp EEG) with p<0.001, while a head-level Carlini LiRA membership audit reaches AUC only 0.50-0.70. Standard defenses fail under audit: a Wiener-style noise-aware adaptive attacker, the LiRA audit, and DP-SGD at every utility-preserving epsilon in {4,8} leave the attribute channel essentially unchanged. The contribution is an audit framework that turns scattered single-endpoint defenses into a joint release decision, supported by a cross-encoder bridge theorem and adaptive-attacker, LiRA, and DP-SGD baselines; the audit licenses release-blocking, not raw-waveform exfiltration or held-out-subject identity recovery.
Capability and Robustness Cannot Both Be Free: An Information-Theoretic Bound for Vision-Language-Action Models
May 28, 2026Vision-Language-Action (VLA) models reach high success rates on clean inputs but collapse under small adversarial perturbations: a $16/255$ PGD attack drops OpenVLA-7B's LIBERO success from above $95\%$ to under $5\%$. Empirical defenses recover part of the loss at a cost in clean accuracy, but the literature does not say whether the trade-off has a theoretical floor. We prove that it does, giving the first information-theoretic bound for action-generating policies. For any VLA policy, capability (mutual information between policy action and oracle action) and robustness (mutual information preserved under attack, minus the action-channel leakage that policies can passively transmit through their output) sum to at most a policy-independent budget: task entropy plus adversarial channel capacity. The leakage term has no analogue in classifier formulations, and is what keeps the inequality tight on action spaces, which can carry attack signal directly. The proof reduces to two applications of the Data Processing Inequality, and an encoder-specific corollary tightens the pixel-level bound by over an order of magnitude on a per-experiment basis. We validate the bound with zero violations across $320$ cells spanning closed-form Gaussian-VLAs, OpenVLA-7B under PGD and Square attacks across all four LIBERO suites, multi-step horizons up to $T{=}10$, and two structurally different action heads (continuous-$L_1$ regression and flow-matching). The bound also yields three diagnostics that practitioners can compute from $\le 200$ samples without ground-truth labels: a pre-flight encoder ceiling for deployment audits, a defense-forensics probe that identifies which channel stage a defense intervenes in, and a head-agnostic robustness ratio that compares discrete-token, $L_1$-regression, and flow-matching policies on equal footing where success-rate-under-attack cannot.
EG-GAN: Cross-Language Emotion Gain Synthesis based on Cycle-Consistent Adversarial Networks
May 27, 2019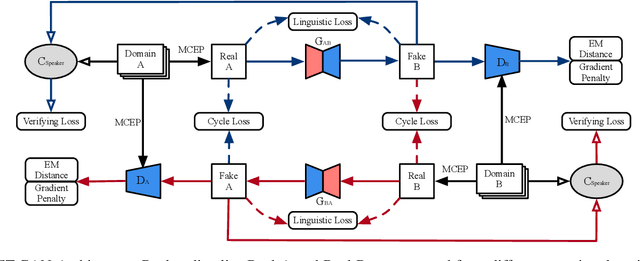
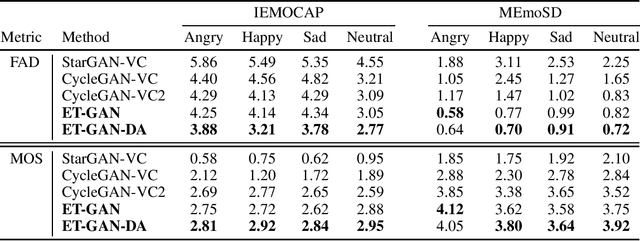
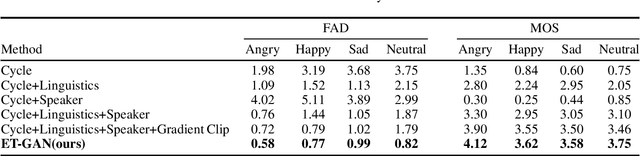

Despite remarkable contributions from existing emotional speech synthesizers, we find that these methods are based on Text-to-Speech system or limited by aligned speech pairs, which suffered from pure emotion gain synthesis. Meanwhile, few studies have discussed the cross-language generalization ability of above methods to cope with the task of emotional speech synthesis in various languages. We propose a cross-language emotion gain synthesis method named EG-GAN which can learn a language-independent mapping from source emotion domain to target emotion domain in the absence of paired speech samples. EG-GAN is based on cycle-consistent generation adversarial network with a gradient penalty and an auxiliary speaker discriminator. The domain adaptation is introduced to implement the rapid migrating and sharing of emotional gains among different languages. The experiment results show that our method can efficiently synthesize high quality emotional speech from any source speech for given emotion categories, without the limitation of language differences and aligned speech pairs.