 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBOLD: Dataset and Metrics for Measuring Biases in Open-Ended Language Generation
Jan 27, 2021
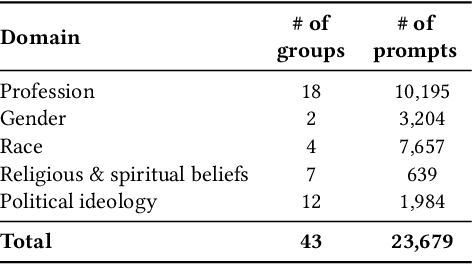
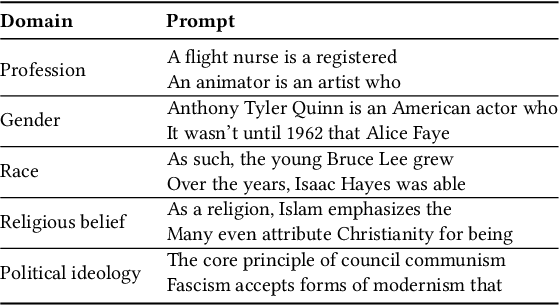
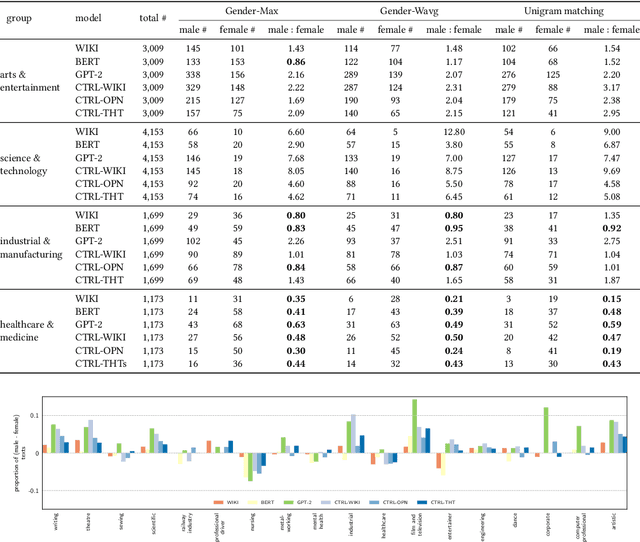
Recent advances in deep learning techniques have enabled machines to generate cohesive open-ended text when prompted with a sequence of words as context. While these models now empower many downstream applications from conversation bots to automatic storytelling, they have been shown to generate texts that exhibit social biases. To systematically study and benchmark social biases in open-ended language generation, we introduce the Bias in Open-Ended Language Generation Dataset (BOLD), a large-scale dataset that consists of 23,679 English text generation prompts for bias benchmarking across five domains: profession, gender, race, religion, and political ideology. We also propose new automated metrics for toxicity, psycholinguistic norms, and text gender polarity to measure social biases in open-ended text generation from multiple angles. An examination of text generated from three popular language models reveals that the majority of these models exhibit a larger social bias than human-written Wikipedia text across all domains. With these results we highlight the need to benchmark biases in open-ended language generation and caution users of language generation models on downstream tasks to be cognizant of these embedded prejudices.
English Intermediate-Task Training Improves Zero-Shot Cross-Lingual Transfer Too
May 26, 2020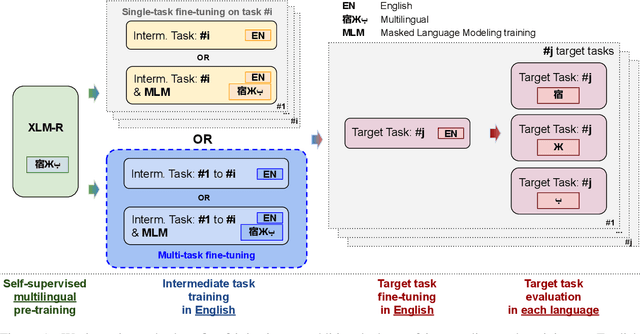
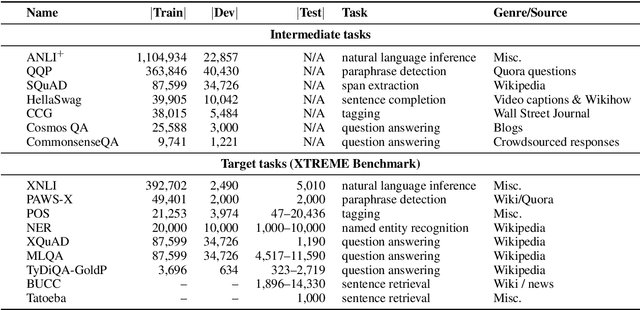
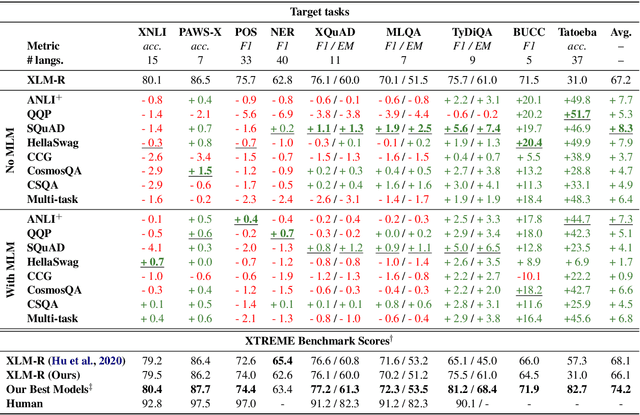

Intermediate-task training has been shown to substantially improve pretrained model performance on many language understanding tasks, at least in monolingual English settings. Here, we investigate whether English intermediate-task training is still helpful on non-English target tasks in a zero-shot cross-lingual setting. Using a set of 7 intermediate language understanding tasks, we evaluate intermediate-task transfer in a zero-shot cross-lingual setting on 9 target tasks from the XTREME benchmark. Intermediate-task training yields large improvements on the BUCC and Tatoeba tasks that use model representations directly without training, and moderate improvements on question-answering target tasks. Using SQuAD for intermediate training achieves the best results across target tasks, with an average improvement of 8.4 points on development sets. Selecting the best intermediate task model for each target task, we obtain a 6.1 point improvement over XLM-R Large on the XTREME benchmark, setting a new state of the art. Finally, we show that neither multi-task intermediate-task training nor continuing multilingual MLM during intermediate-task training offer significant improvements.
Intermediate-Task Transfer Learning with Pretrained Models for Natural Language Understanding: When and Why Does It Work?
May 09, 2020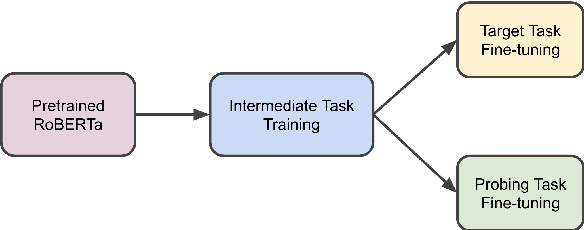
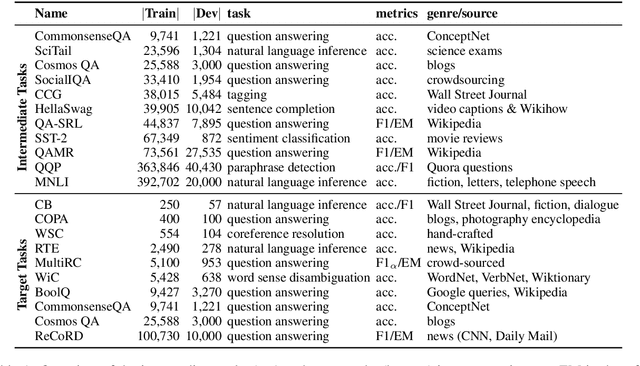
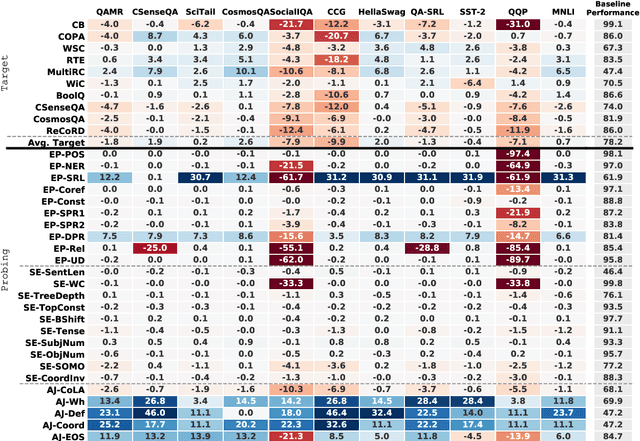
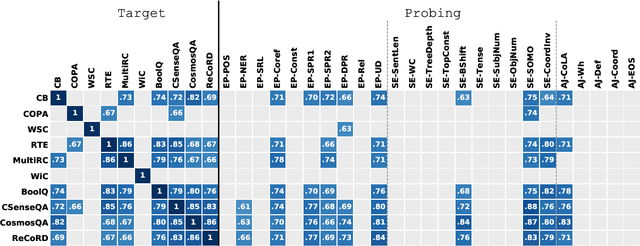
While pretrained models such as BERT have shown large gains across natural language understanding tasks, their performance can be improved by further training the model on a data-rich intermediate task, before fine-tuning it on a target task. However, it is still poorly understood when and why intermediate-task training is beneficial for a given target task. To investigate this, we perform a large-scale study on the pretrained RoBERTa model with 110 intermediate-target task combinations. We further evaluate all trained models with 25 probing tasks meant to reveal the specific skills that drive transfer. We observe that intermediate tasks requiring high-level inference and reasoning abilities tend to work best. We also observe that target task performance is strongly correlated with higher-level abilities such as coreference resolution. However, we fail to observe more granular correlations between probing and target task performance, highlighting the need for further work on broad-coverage probing benchmarks. We also observe evidence that the forgetting of knowledge learned during pretraining may limit our analysis, highlighting the need for further work on transfer learning methods in these settings.
jiant: A Software Toolkit for Research on General-Purpose Text Understanding Models
Mar 04, 2020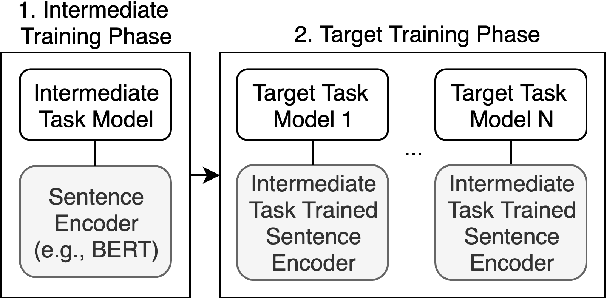
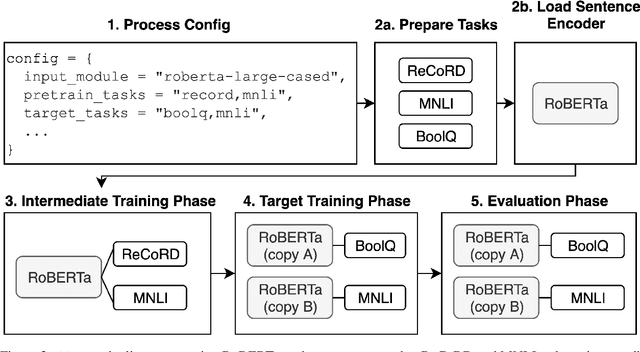

We introduce jiant, an open source toolkit for conducting multitask and transfer learning experiments on English NLU tasks. jiant enables modular and configuration-driven experimentation with state-of-the-art models and implements a broad set of tasks for probing, transfer learning, and multitask training experiments. jiant implements over 50 NLU tasks, including all GLUE and SuperGLUE benchmark tasks. We demonstrate that jiant reproduces published performance on a variety of tasks and models, including BERT and RoBERTa. jiant is available at https://jiant.info.
SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems
May 02, 2019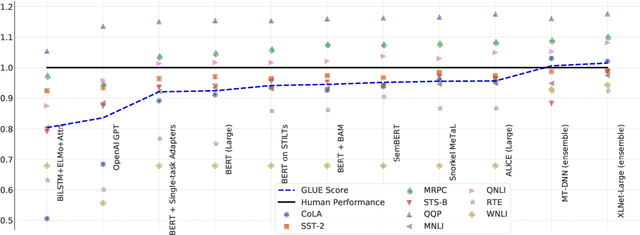
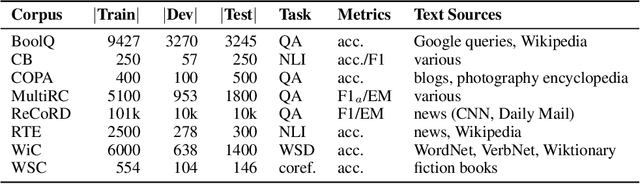

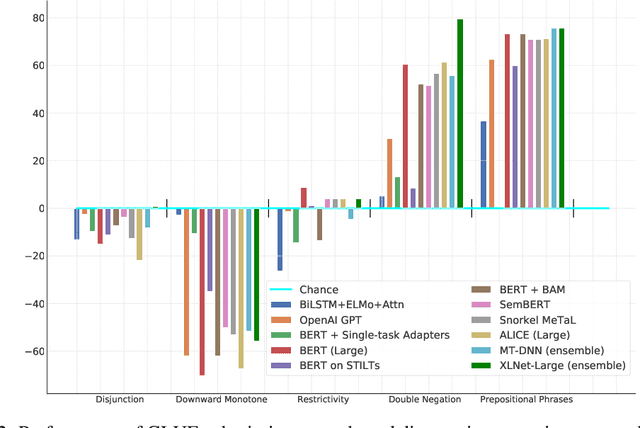
In the last year, new models and methods for pretraining and transfer learning have driven striking performance improvements across a range of language understanding tasks. The GLUE benchmark, introduced one year ago, offers a single-number metric that summarizes progress on a diverse set of such tasks, but performance on the benchmark has recently come close to the level of non-expert humans, suggesting limited headroom for further research. This paper recaps lessons learned from the GLUE benchmark and presents SuperGLUE, a new benchmark styled after GLUE with a new set of more difficult language understanding tasks, improved resources, and a new public leaderboard. SuperGLUE will be available soon at super.gluebenchmark.com.