 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTest-Time Compute Scaling for ASR with Depth-Conditioned Looped Transformers
Jun 03, 2026End-to-end ASR systems typically use fixed-depth acoustic encoders at inference, making it difficult to trade additional test-time computation for improved recognition without training a larger model. A natural approach is to reuse a shared Transformer block recurrently, but we find that naive looping does not fully exploit additional recurrent compute. We introduce LARM, a depth-conditioned looped Transformer that turns recurrent encoder depth into a controllable test-time compute axis. LARM combines sparse CTC checkpoints, supervision-clock embeddings, FiLM depth conditioning, and delayed soft-posterior feedback. These components structure the loop into recognition checkpoints separated by latent refinement phases and allow shared weights to specialize across recurrent steps. On LibriSpeech, LARM improves WER as the number of inference loops increases and achieves performance competitive with deeper unshared-parameter baselines. Our results show that test-time compute scaling can extend beyond autoregressive language-model reasoning to continuous non-autoregressive speech recognition.
Geometric Latent Reasoning Induces Shorter Generations in LLMs
Jun 01, 2026Large language models solve complex problems by generating lengthy chains of explicit reasoning tokens. While effective, this makes reasoning expensive, length-sensitive, and constrained to (discrete) natural language. While latent reasoning offers a continuous alternative, determining useful structures for intermediate latent states is an open challenge. In this paper, we formulate latent reasoning as a geometric path-approximation problem within the model's pretrained token-embedding space. We introduce Geometric Latent Reasoning (GLR), which uses a lightweight transition head to predict iterative direction updates in embedding space. Using textual chain-of-thought traces as anchors, GLR learns to approximate discrete reasoning trajectories while permitting continuous deviations from exact token embeddings. Evaluations on mathematical reasoning benchmarks using Qwen3 models reveal an emergent phenomenon: geometric latent reasoning induces substantially shorter generations without an explicit length objective. By replacing early explicit reasoning with continuous latent steps, models often reach correct answers using substantially fewer total generation steps. These findings suggest that continuous trajectories act as compact intermediate reasoning states, exposing a new tradeoff between latent computation budget, output length, and accuracy.
CLAP-Based Automatic Word Naming Recognition in Post-Stroke Aphasia
Feb 16, 2026Conventional automatic word-naming recognition systems struggle to recognize words from post-stroke patients with aphasia because of disfluencies and mispronunciations, limiting reliable automated assessment in this population. In this paper, we propose a Contrastive Language-Audio Pretraining (CLAP) based approach for automatic word-naming recognition to address this challenge by leveraging text-audio alignment. Our approach treats word-naming recognition as an audio-text matching problem, projecting speech signals and textual prompts into a shared embedding space to identify intended words even in challenging recordings. Evaluated on two speech datasets of French post-stroke patients with aphasia, our approach achieves up to 90% accuracy, outperforming existing classification-based and automatic speech recognition-based baselines.
Towards interpretable emotion recognition: Identifying key features with machine learning
Aug 06, 2025Unsupervised methods, such as wav2vec2 and HuBERT, have achieved state-of-the-art performance in audio tasks, leading to a shift away from research on interpretable features. However, the lack of interpretability in these methods limits their applicability in critical domains like medicine, where understanding feature relevance is crucial. To better understand the features of unsupervised models, it remains critical to identify the interpretable features relevant to a given task. In this work, we focus on emotion recognition and use machine learning algorithms to identify and generalize the most important interpretable features for this task. While previous studies have explored feature relevance in emotion recognition, they are often constrained by narrow contexts and present inconsistent findings. Our approach aims to overcome these limitations, providing a broader and more robust framework for identifying the most important interpretable features.
A Differentiable Alignment Framework for Sequence-to-Sequence Modeling via Optimal Transport
Feb 03, 2025



Accurate sequence-to-sequence (seq2seq) alignment is critical for applications like medical speech analysis and language learning tools relying on automatic speech recognition (ASR). State-of-the-art end-to-end (E2E) ASR systems, such as the Connectionist Temporal Classification (CTC) and transducer-based models, suffer from peaky behavior and alignment inaccuracies. In this paper, we propose a novel differentiable alignment framework based on one-dimensional optimal transport, enabling the model to learn a single alignment and perform ASR in an E2E manner. We introduce a pseudo-metric, called Sequence Optimal Transport Distance (SOTD), over the sequence space and discuss its theoretical properties. Based on the SOTD, we propose Optimal Temporal Transport Classification (OTTC) loss for ASR and contrast its behavior with CTC. Experimental results on the TIMIT, AMI, and LibriSpeech datasets show that our method considerably improves alignment performance, though with a trade-off in ASR performance when compared to CTC. We believe this work opens new avenues for seq2seq alignment research, providing a solid foundation for further exploration and development within the community.
Graph Neural Networks for Parkinsons Disease Detection
Sep 12, 2024



Despite the promising performance of state of the art approaches for Parkinsons Disease (PD) detection, these approaches often analyze individual speech segments in isolation, which can lead to suboptimal results. Dysarthric cues that characterize speech impairments from PD patients are expected to be related across segments from different speakers. Isolated segment analysis fails to exploit these inter segment relationships. Additionally, not all speech segments from PD patients exhibit clear dysarthric symptoms, introducing label noise that can negatively affect the performance and generalizability of current approaches. To address these challenges, we propose a novel PD detection framework utilizing Graph Convolutional Networks (GCNs). By representing speech segments as nodes and capturing the similarity between segments through edges, our GCN model facilitates the aggregation of dysarthric cues across the graph, effectively exploiting segment relationships and mitigating the impact of label noise. Experimental results demonstrate theadvantages of the proposed GCN model for PD detection and provide insights into its underlying mechanisms
A simple way to learn metrics between attributed graphs
Sep 26, 2022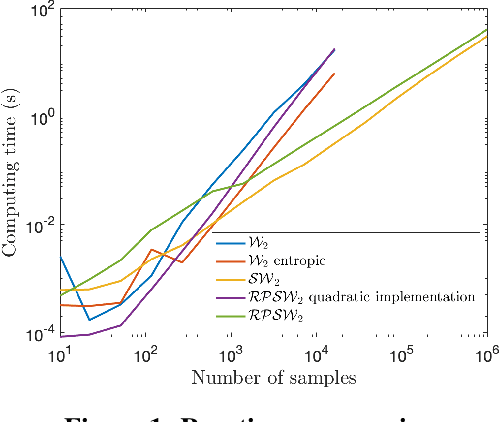
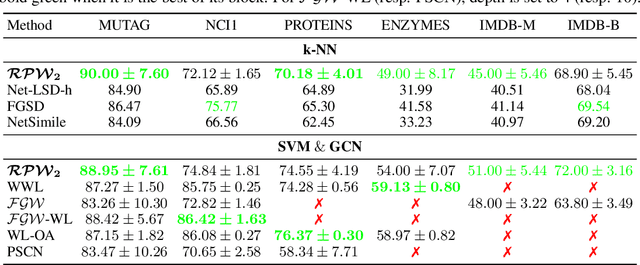
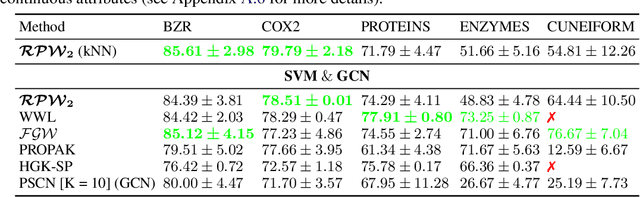
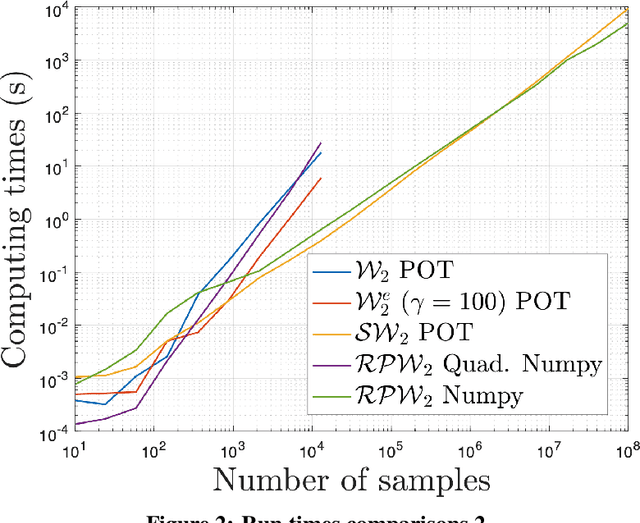
The choice of good distances and similarity measures between objects is important for many machine learning methods. Therefore, many metric learning algorithms have been developed in recent years, mainly for Euclidean data in order to improve performance of classification or clustering methods. However, due to difficulties in establishing computable, efficient and differentiable distances between attributed graphs, few metric learning algorithms adapted to graphs have been developed despite the strong interest of the community. In this paper, we address this issue by proposing a new Simple Graph Metric Learning - SGML - model with few trainable parameters based on Simple Graph Convolutional Neural Networks - SGCN - and elements of Optimal Transport theory. This model allows us to build an appropriate distance from a database of labeled (attributed) graphs to improve the performance of simple classification algorithms such as $k$-NN. This distance can be quickly trained while maintaining good performances as illustrated by the experimental study presented in this paper.
Multiview Variational Graph Autoencoders for Canonical Correlation Analysis
Oct 30, 2020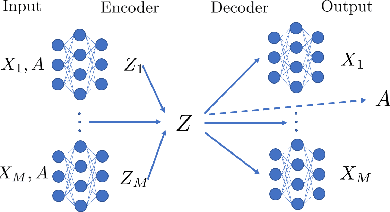
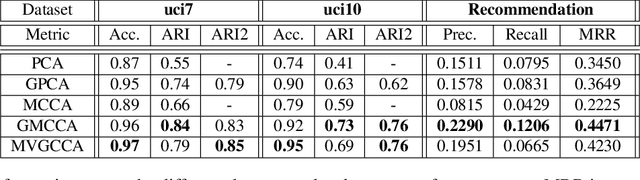
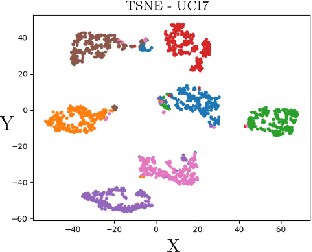
We present a novel multiview canonical correlation analysis model based on a variational approach. This is the first nonlinear model that takes into account the available graph-based geometric constraints while being scalable for processing large scale datasets with multiple views. It is based on an autoencoder architecture with graph convolutional neural network layers. We experiment with our approach on classification, clustering, and recommendation tasks on real datasets. The algorithm is competitive with state-of-the-art multiview representation learning techniques.
Hierarchical and Unsupervised Graph Representation Learning with Loukas's Coarsening
Jul 07, 2020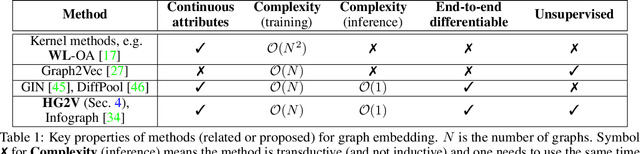
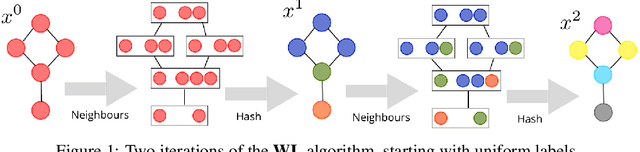
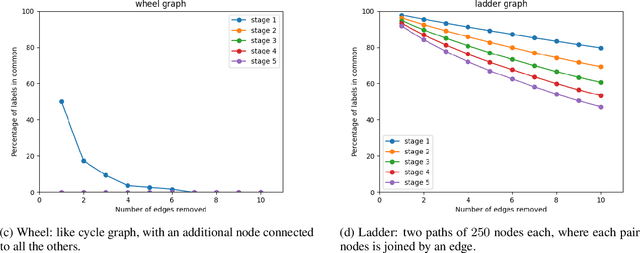
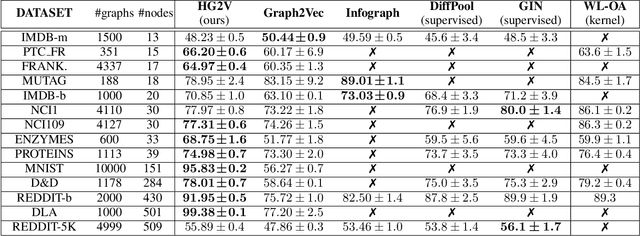
We propose a novel algorithm for unsupervised graph representation learning with attributed graphs. It combines three advantages addressing some current limitations of the literature: i) The model is inductive: it can embed new graphs without re-training in the presence of new data; ii) The method takes into account both micro-structures and macro-structures by looking at the attributed graphs at different scales; iii) The model is end-to-end differentiable: it is a building block that can be plugged into deep learning pipelines and allows for back-propagation. We show that combining a coarsening method having strong theoretical guarantees with mutual information maximization suffices to produce high quality embeddings. We evaluate them on classification tasks with common benchmarks of the literature. We show that our algorithm is competitive with state of the art among unsupervised graph representation learning methods.