 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
The SYSU System for the Interspeech 2015 Automatic Speaker Verification Spoofing and Countermeasures Challenge
Jul 29, 2015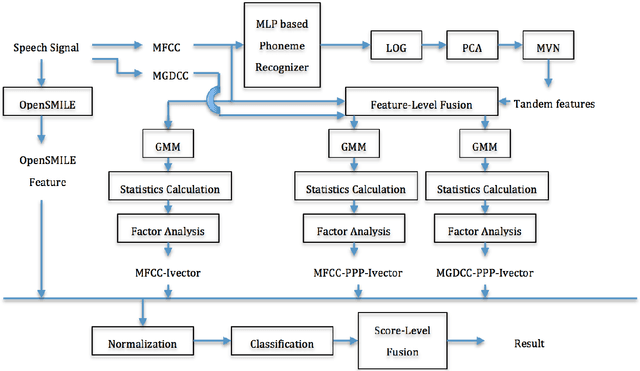
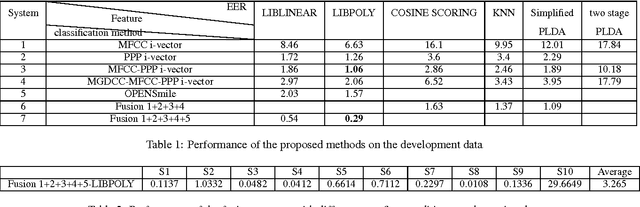


Many existing speaker verification systems are reported to be vulnerable against different spoofing attacks, for example speaker-adapted speech synthesis, voice conversion, play back, etc. In order to detect these spoofed speech signals as a countermeasure, we propose a score level fusion approach with several different i-vector subsystems. We show that the acoustic level Mel-frequency cepstral coefficients (MFCC) features, the phase level modified group delay cepstral coefficients (MGDCC) and the phonetic level phoneme posterior probability (PPP) tandem features are effective for the countermeasure. Furthermore, feature level fusion of these features before i-vector modeling also enhance the performance. A polynomial kernel support vector machine is adopted as the supervised classifier. In order to enhance the generalizability of the countermeasure, we also adopted the cosine similarity and PLDA scoring as one-class classifications methods. By combining the proposed i-vector subsystems with the OpenSMILE baseline which covers the acoustic and prosodic information further improves the final performance. The proposed fusion system achieves 0.29% and 3.26% EER on the development and test set of the database provided by the INTERSPEECH 2015 automatic speaker verification spoofing and countermeasures challenge.