 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Text-Instance Alignment Of Foreground Conditioned Out-Painting Via Customized Concept Embedding
Jun 09, 2026To showcase products, merchants often incur substantial costs creating high-quality display images. Foreground Conditioned Outpainting (FCO) meets this demand, allowing users to create desired backgrounds for foreground instances at a low cost by adjusting the text prompt. However, existing text-driven FCO methods exhibit critical flaws in their outputs, most notably the presence of artifacts, which refer to regions in the synthesized background that share the same semantics as the foreground instance. Such artifacts diminish the object's prominence and degrade image quality. We attribute the issue to the misalignment between the given instance and text-derived concept embeddings. To address this, we propose the Customized Concept Embedding Diffusion (CCE-Diffusion) framework. Its core is a CCE-Module to customize concept embeddings, bridging the gap between generic noun semantics and a specific visual instance. An Instance-Aware Loss guides the module's optimization, while a Semantic-Preserving Prompt Template prevents customized embeddings from distorting other words in the prompt. Both qualitative and quantitative evaluations demonstrate that CCE-Diffusion significantly reduces artifacts in the outputs. As a plug-and-play component, the CCE-Module can integrate with various FCO methods, enhancing their performance.
Pose-ICL: 3D-Aware In-Context Learning for Pose-Controllable Subject Customization
Jun 09, 2026Subject Customization is a foundational task in modern image generation. By providing a few reference images and a text prompt, users can generate images of a specific object in any desired scene. However, existing methods still struggle to achieve effective pose control for customized subjects. In practice, they often exhibit inaccurate poses or inconsistent cross-pose appearances. These limitations suggest that understanding objects in a volumetric manner remains a significant challenge for 2D-native backbones. To address this challenge, we propose Pose-ICL, a tuning-free framework that leverages 3D-aware In-Context Learning (ICL) to directly adapt to new subjects through multiple paired image-pose references. Its core mechanism,Surface-Anchored Position Embedding (SAPE), equips the model with explicit 3D awareness by anchoring image tokens to the surface coordinates of a volumetric bounding box. Dedicated refinements ensure its seamless compatibility with existing DiT models. Extensive evaluations on both 3D assets and real-world subjects demonstrate that Pose-ICL significantly outperforms current methods in both pose accuracy and identity consistency.
3D Part Assembly Generation with Instance Encoded Transformer
Jul 05, 2022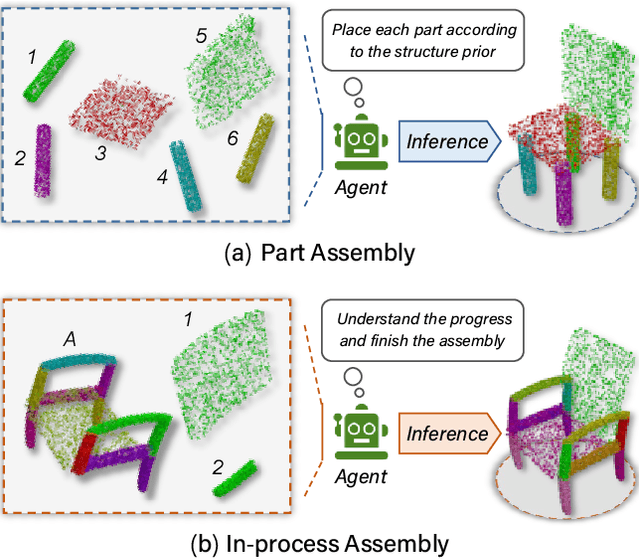
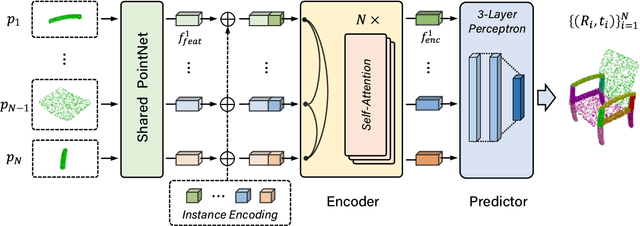
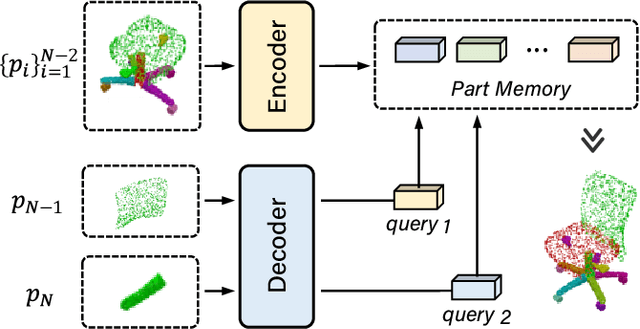
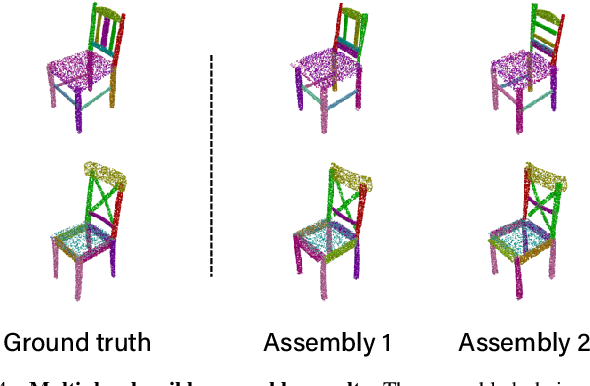
It is desirable to enable robots capable of automatic assembly. Structural understanding of object parts plays a crucial role in this task yet remains relatively unexplored. In this paper, we focus on the setting of furniture assembly from a complete set of part geometries, which is essentially a 6-DoF part pose estimation problem. We propose a multi-layer transformer-based framework that involves geometric and relational reasoning between parts to update the part poses iteratively. We carefully design a unique instance encoding to solve the ambiguity between geometrically-similar parts so that all parts can be distinguished. In addition to assembling from scratch, we extend our framework to a new task called in-process part assembly. Analogous to furniture maintenance, it requires robots to continue with unfinished products and assemble the remaining parts into appropriate positions. Our method achieves far more than 10% improvements over the current state-of-the-art in multiple metrics on the public PartNet dataset. Extensive experiments and quantitative comparisons demonstrate the effectiveness of the proposed framework.
* 8 pages, 7 figures