 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixture-of-Experts Knowledge Graph Retrieval-Augmented Generation for Multi-Agent LLM-based Recommendation
May 27, 2026Large language models (LLMs) have recently been adopted for recommendations due to their ability to understand user intent and item semantics. However, LLM-based recommender systems often rely on parametric knowledge and suffer from outdated knowledge, motivating knowledge graph retrieval-augmented generation (KG-RAG) to ground recommendations on structured, up-to-date KGs. Despite this promise, effective KG-RAG in recommendations faces great challenges. First, users' queries vary in complexity and require KG knowledge at different granularities, whereas existing methods adopt a one-size-fits-all retrieval strategy, leading to over-retrieval for simple queries and under-retrieval for complex ones. In addition, augmenting LLMs with KG knowledge requires translating graph-structured data into linear text, which may introduce noise and cause structural information loss. Moreover, the selection of retrieval granularity lacks direct supervision and must be inferred from the final recommendation after alignment and downstream utilization, making query-aware retrieval hard to learn end-to-end. To address these issues, we propose MixRAGRec, a cooperative multi-agent framework for KG-RAG recommendations. MixRAGRec integrates a Mixture-of-Experts Retrieval Agent that routes each query to a KG retrieval expert with different granularities, a Knowledge Preference Alignment Agent that converts structured knowledge into LLM-friendly natural language, and a Contrastive Learning-reinforced Recommendation Agent trained with contrastive preference feedback. Notably, we introduce Mixture-of-Experts Multi-Agent Policy Optimization (MMAPO) to train three agents under a unified objective. Extensive experiments on real-world datasets demonstrate the effectiveness of our framework.
Prediction Algorithm for Heat Demand of Science and Technology Topics Based on Time Convolution Network
Mar 21, 2022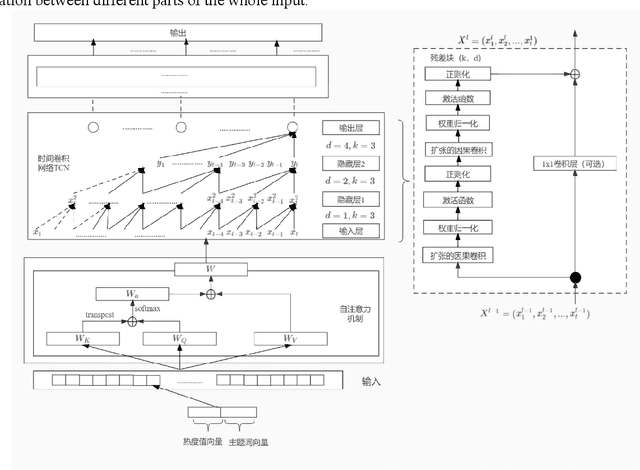
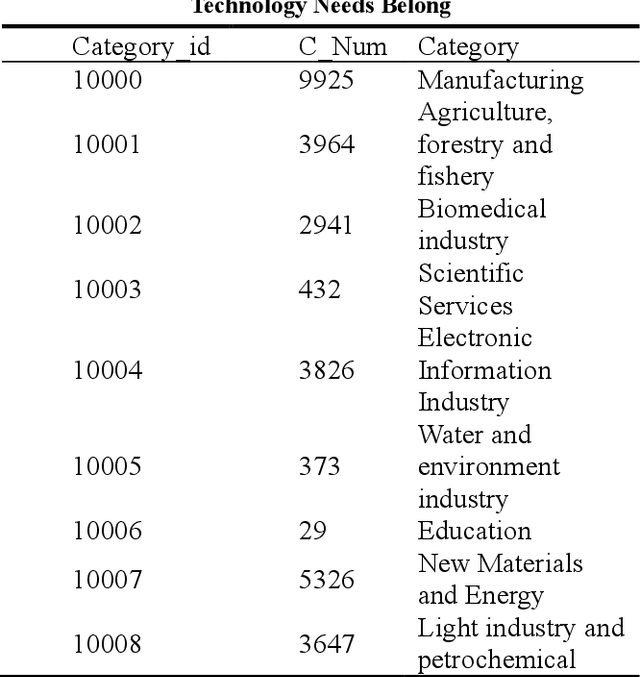
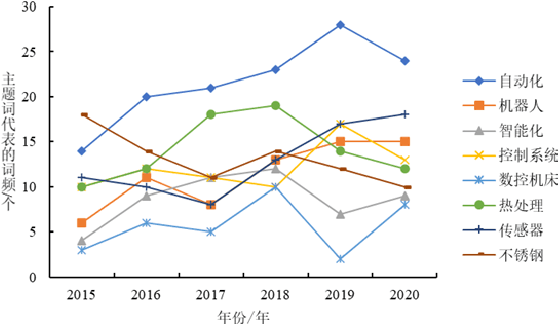
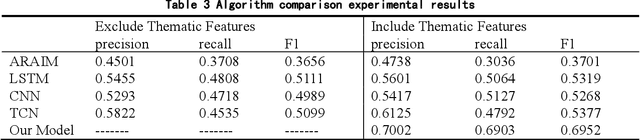
Thanks to the rapid development of deep learning, big data analysis technology is not only widely used in the field of natural language processing, but also more mature in the field of numerical prediction. It is of great significance for the subject heat prediction and analysis of science and technology demand data. How to apply theme features to accurately predict the theme heat of science and technology demand is the core to solve this problem. In this paper, a prediction method of subject heat of science and technology demand based on time convolution network (TCN) is proposed to obtain the subject feature representation of science and technology demand. Time series prediction is carried out based on TCN network and self attention mechanism, which increases the accuracy of subject heat prediction of science and technology demand data Experiments show that the prediction accuracy of this algorithm is better than other time series prediction methods on the real science and technology demand datasets.